Shichong Wu, Lingli Xie, Jun Xian, Fei Liao, Wenhua Wu, Mingqing Lu, Xian Yi
{"title":"未知动态和干扰条件下基于强化学习的跨媒体车辆有限时间跨媒体跟踪控制","authors":"Shichong Wu, Lingli Xie, Jun Xian, Fei Liao, Wenhua Wu, Mingqing Lu, Xian Yi","doi":"10.1049/cth2.12693","DOIUrl":null,"url":null,"abstract":"<p>This study proposes a reinforcement learning-based finite-time cross-media tracking control approach for a slender body cross-media vehicle encountering unknown hydrodynamics, wind, and wave disturbances. Initially, a reinforcement learning framework consisting of the actor neural network and critic neural network is constructed. The critic neural network monitors the actions of the actor neural network and approximates the cost function, while the actor neural network estimates the unknown hydrodynamics and disturbances, minimising the cost function to optimise performance. Subsequently, the command filter featuring finite-time convergence is formulated, effectively managing the corresponding filter error through a proposed error compensating signal. By integrating these techniques, a reinforcement learning-based finite-time control strategy is developed, circumventing the singularity issue inherent in traditional finite-time backstepping strategies. Comparative analysis with existing methods demonstrates the strong robustness of the proposed scheme against unknown hydrodynamics and disturbances, ensuring finite-time convergence of the system's states and optimising controller performance. Finally, simulations confirm the effectiveness and superiority of the presented approach.</p>","PeriodicalId":50382,"journal":{"name":"IET Control Theory and Applications","volume":"18 11","pages":"1475-1490"},"PeriodicalIF":2.3000,"publicationDate":"2024-06-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/cth2.12693","citationCount":"0","resultStr":"{\"title\":\"Reinforcement learning-based finite-time cross-media tracking control for a cross-media vehicle under unknown dynamics and disturbances\",\"authors\":\"Shichong Wu, Lingli Xie, Jun Xian, Fei Liao, Wenhua Wu, Mingqing Lu, Xian Yi\",\"doi\":\"10.1049/cth2.12693\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>This study proposes a reinforcement learning-based finite-time cross-media tracking control approach for a slender body cross-media vehicle encountering unknown hydrodynamics, wind, and wave disturbances. Initially, a reinforcement learning framework consisting of the actor neural network and critic neural network is constructed. The critic neural network monitors the actions of the actor neural network and approximates the cost function, while the actor neural network estimates the unknown hydrodynamics and disturbances, minimising the cost function to optimise performance. Subsequently, the command filter featuring finite-time convergence is formulated, effectively managing the corresponding filter error through a proposed error compensating signal. By integrating these techniques, a reinforcement learning-based finite-time control strategy is developed, circumventing the singularity issue inherent in traditional finite-time backstepping strategies. Comparative analysis with existing methods demonstrates the strong robustness of the proposed scheme against unknown hydrodynamics and disturbances, ensuring finite-time convergence of the system's states and optimising controller performance. Finally, simulations confirm the effectiveness and superiority of the presented approach.</p>\",\"PeriodicalId\":50382,\"journal\":{\"name\":\"IET Control Theory and Applications\",\"volume\":\"18 11\",\"pages\":\"1475-1490\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2024-06-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1049/cth2.12693\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"IET Control Theory and Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/cth2.12693\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"AUTOMATION & CONTROL SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Control Theory and Applications","FirstCategoryId":"94","ListUrlMain":"https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/cth2.12693","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
Reinforcement learning-based finite-time cross-media tracking control for a cross-media vehicle under unknown dynamics and disturbances
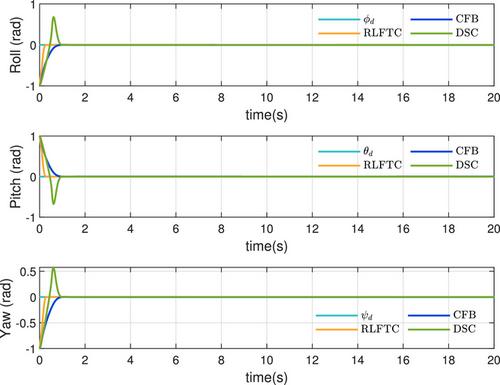
This study proposes a reinforcement learning-based finite-time cross-media tracking control approach for a slender body cross-media vehicle encountering unknown hydrodynamics, wind, and wave disturbances. Initially, a reinforcement learning framework consisting of the actor neural network and critic neural network is constructed. The critic neural network monitors the actions of the actor neural network and approximates the cost function, while the actor neural network estimates the unknown hydrodynamics and disturbances, minimising the cost function to optimise performance. Subsequently, the command filter featuring finite-time convergence is formulated, effectively managing the corresponding filter error through a proposed error compensating signal. By integrating these techniques, a reinforcement learning-based finite-time control strategy is developed, circumventing the singularity issue inherent in traditional finite-time backstepping strategies. Comparative analysis with existing methods demonstrates the strong robustness of the proposed scheme against unknown hydrodynamics and disturbances, ensuring finite-time convergence of the system's states and optimising controller performance. Finally, simulations confirm the effectiveness and superiority of the presented approach.
期刊介绍:
IET Control Theory & Applications is devoted to control systems in the broadest sense, covering new theoretical results and the applications of new and established control methods. Among the topics of interest are system modelling, identification and simulation, the analysis and design of control systems (including computer-aided design), and practical implementation. The scope encompasses technological, economic, physiological (biomedical) and other systems, including man-machine interfaces.
Most of the papers published deal with original work from industrial and government laboratories and universities, but subject reviews and tutorial expositions of current methods are welcomed. Correspondence discussing published papers is also welcomed.
Applications papers need not necessarily involve new theory. Papers which describe new realisations of established methods, or control techniques applied in a novel situation, or practical studies which compare various designs, would be of interest. Of particular value are theoretical papers which discuss the applicability of new work or applications which engender new theoretical applications.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
