Mehmet Eren Ahsen, Robert Vogel, Gustavo Stolovitzky
{"title":"二元分类器的最优线性组合。","authors":"Mehmet Eren Ahsen, Robert Vogel, Gustavo Stolovitzky","doi":"10.1093/bioadv/vbae093","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>The integration of vast, complex biological data with computational models offers profound insights and predictive accuracy. Yet, such models face challenges: poor generalization and limited labeled data.</p><p><strong>Results: </strong>To overcome these difficulties in binary classification tasks, we developed the Method for Optimal Classification by Aggregation (MOCA) algorithm, which addresses the problem of generalization by virtue of being an ensemble learning method and can be used in problems with limited or no labeled data. We developed both an unsupervised (uMOCA) and a supervised (sMOCA) variant of MOCA. For uMOCA, we show how to infer the MOCA weights in an unsupervised way, which are optimal under the assumption of class-conditioned independent classifier predictions. When it is possible to use labels, sMOCA uses empirically computed MOCA weights. We demonstrate the performance of uMOCA and sMOCA using simulated data as well as actual data previously used in Dialogue on Reverse Engineering and Methods (DREAM) challenges. We also propose an application of sMOCA for transfer learning where we use pre-trained computational models from a domain where labeled data are abundant and apply them to a different domain with less abundant labeled data.</p><p><strong>Availability and implementation: </strong>GitHub repository, https://github.com/robert-vogel/moca.</p>","PeriodicalId":72368,"journal":{"name":"Bioinformatics advances","volume":"4 1","pages":"vbae093"},"PeriodicalIF":2.8000,"publicationDate":"2024-06-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11249386/pdf/","citationCount":"0","resultStr":"{\"title\":\"Optimal linear ensemble of binary classifiers.\",\"authors\":\"Mehmet Eren Ahsen, Robert Vogel, Gustavo Stolovitzky\",\"doi\":\"10.1093/bioadv/vbae093\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Motivation: </strong>The integration of vast, complex biological data with computational models offers profound insights and predictive accuracy. Yet, such models face challenges: poor generalization and limited labeled data.</p><p><strong>Results: </strong>To overcome these difficulties in binary classification tasks, we developed the Method for Optimal Classification by Aggregation (MOCA) algorithm, which addresses the problem of generalization by virtue of being an ensemble learning method and can be used in problems with limited or no labeled data. We developed both an unsupervised (uMOCA) and a supervised (sMOCA) variant of MOCA. For uMOCA, we show how to infer the MOCA weights in an unsupervised way, which are optimal under the assumption of class-conditioned independent classifier predictions. When it is possible to use labels, sMOCA uses empirically computed MOCA weights. We demonstrate the performance of uMOCA and sMOCA using simulated data as well as actual data previously used in Dialogue on Reverse Engineering and Methods (DREAM) challenges. We also propose an application of sMOCA for transfer learning where we use pre-trained computational models from a domain where labeled data are abundant and apply them to a different domain with less abundant labeled data.</p><p><strong>Availability and implementation: </strong>GitHub repository, https://github.com/robert-vogel/moca.</p>\",\"PeriodicalId\":72368,\"journal\":{\"name\":\"Bioinformatics advances\",\"volume\":\"4 1\",\"pages\":\"vbae093\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2024-06-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11249386/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Bioinformatics advances\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/bioadv/vbae093\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Bioinformatics advances","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/bioadv/vbae093","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Motivation: The integration of vast, complex biological data with computational models offers profound insights and predictive accuracy. Yet, such models face challenges: poor generalization and limited labeled data.
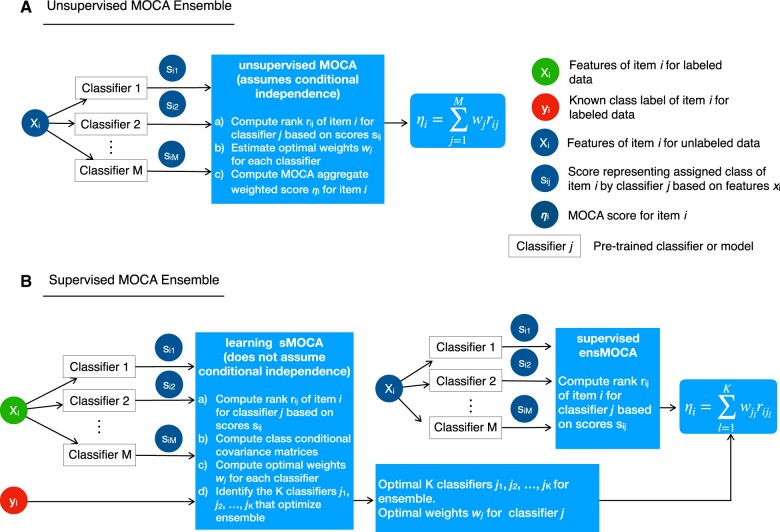
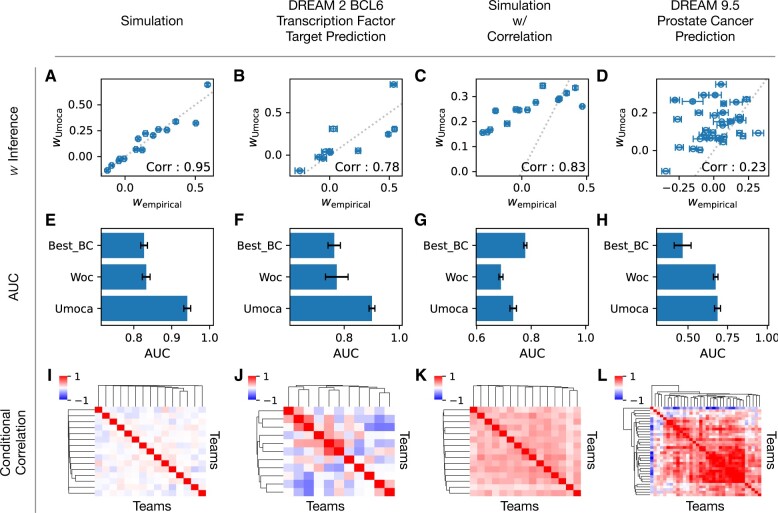
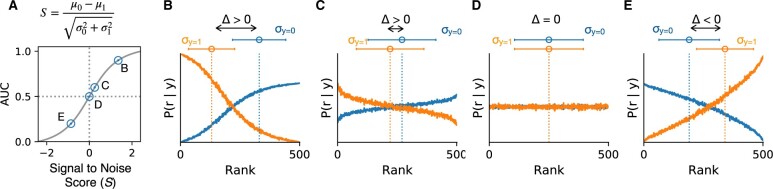
Results: To overcome these difficulties in binary classification tasks, we developed the Method for Optimal Classification by Aggregation (MOCA) algorithm, which addresses the problem of generalization by virtue of being an ensemble learning method and can be used in problems with limited or no labeled data. We developed both an unsupervised (uMOCA) and a supervised (sMOCA) variant of MOCA. For uMOCA, we show how to infer the MOCA weights in an unsupervised way, which are optimal under the assumption of class-conditioned independent classifier predictions. When it is possible to use labels, sMOCA uses empirically computed MOCA weights. We demonstrate the performance of uMOCA and sMOCA using simulated data as well as actual data previously used in Dialogue on Reverse Engineering and Methods (DREAM) challenges. We also propose an application of sMOCA for transfer learning where we use pre-trained computational models from a domain where labeled data are abundant and apply them to a different domain with less abundant labeled data.
Availability and implementation: GitHub repository, https://github.com/robert-vogel/moca.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
