Yunyi Liu , Yingshu Li , Zhanyu Wang , Xinyu Liang , Lingqiao Liu , Lei Wang , Leyang Cui , Zhaopeng Tu , Longyue Wang , Luping Zhou
{"title":"对 GPT-4V 胸部 X 光图像分析多模态功能的系统评估","authors":"Yunyi Liu , Yingshu Li , Zhanyu Wang , Xinyu Liang , Lingqiao Liu , Lei Wang , Leyang Cui , Zhaopeng Tu , Longyue Wang , Luping Zhou","doi":"10.1016/j.metrad.2024.100099","DOIUrl":null,"url":null,"abstract":"<div><div>This work evaluates GPT-4V's multimodal capability for medical image analysis, focusing on three representative tasks radiology report generation, medical visual question answering, and medical visual grounding. For the evaluation, a set of prompts is designed for each task to induce the corresponding capability of GPT-4V to produce sufficiently good outputs. Three evaluation ways including quantitative analysis, human evaluation, and case study are employed to achieve an in-depth and extensive evaluation. Our evaluation shows that GPT-4V excels in understanding medical images can generate high-quality radiology reports and effectively answer questions about medical images. Meanwhile, it is found that its performance for medical visual grounding needs to be substantially improved. In addition, we observe the discrepancy between the evaluation outcome from quantitative analysis and that from human evaluation. This discrepancy suggests the limitations of conventional metrics in assessing the performance of large language models like GPT-4V and the necessity of developing new metrics for automatic quantitative analysis.</div></div>","PeriodicalId":100921,"journal":{"name":"Meta-Radiology","volume":"2 4","pages":"Article 100099"},"PeriodicalIF":0.0000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A systematic evaluation of GPT-4V's multimodal capability for chest X-ray image analysis\",\"authors\":\"Yunyi Liu , Yingshu Li , Zhanyu Wang , Xinyu Liang , Lingqiao Liu , Lei Wang , Leyang Cui , Zhaopeng Tu , Longyue Wang , Luping Zhou\",\"doi\":\"10.1016/j.metrad.2024.100099\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>This work evaluates GPT-4V's multimodal capability for medical image analysis, focusing on three representative tasks radiology report generation, medical visual question answering, and medical visual grounding. For the evaluation, a set of prompts is designed for each task to induce the corresponding capability of GPT-4V to produce sufficiently good outputs. Three evaluation ways including quantitative analysis, human evaluation, and case study are employed to achieve an in-depth and extensive evaluation. Our evaluation shows that GPT-4V excels in understanding medical images can generate high-quality radiology reports and effectively answer questions about medical images. Meanwhile, it is found that its performance for medical visual grounding needs to be substantially improved. In addition, we observe the discrepancy between the evaluation outcome from quantitative analysis and that from human evaluation. This discrepancy suggests the limitations of conventional metrics in assessing the performance of large language models like GPT-4V and the necessity of developing new metrics for automatic quantitative analysis.</div></div>\",\"PeriodicalId\":100921,\"journal\":{\"name\":\"Meta-Radiology\",\"volume\":\"2 4\",\"pages\":\"Article 100099\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Meta-Radiology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2950162824000535\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/7/15 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Meta-Radiology","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2950162824000535","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/7/15 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
A systematic evaluation of GPT-4V's multimodal capability for chest X-ray image analysis
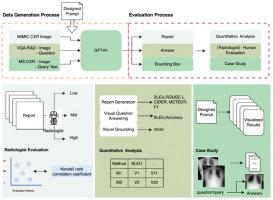
This work evaluates GPT-4V's multimodal capability for medical image analysis, focusing on three representative tasks radiology report generation, medical visual question answering, and medical visual grounding. For the evaluation, a set of prompts is designed for each task to induce the corresponding capability of GPT-4V to produce sufficiently good outputs. Three evaluation ways including quantitative analysis, human evaluation, and case study are employed to achieve an in-depth and extensive evaluation. Our evaluation shows that GPT-4V excels in understanding medical images can generate high-quality radiology reports and effectively answer questions about medical images. Meanwhile, it is found that its performance for medical visual grounding needs to be substantially improved. In addition, we observe the discrepancy between the evaluation outcome from quantitative analysis and that from human evaluation. This discrepancy suggests the limitations of conventional metrics in assessing the performance of large language models like GPT-4V and the necessity of developing new metrics for automatic quantitative analysis.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
