Matthew Rosenblatt, Link Tejavibulya, Huili Sun, Chris C. Camp, Milana Khaitova, Brendan D. Adkinson, Rongtao Jiang, Margaret L. Westwater, Stephanie Noble, Dustin Scheinost
{"title":"大脑表型预测外部验证的有效性和可重复性","authors":"Matthew Rosenblatt, Link Tejavibulya, Huili Sun, Chris C. Camp, Milana Khaitova, Brendan D. Adkinson, Rongtao Jiang, Margaret L. Westwater, Stephanie Noble, Dustin Scheinost","doi":"10.1038/s41562-024-01931-7","DOIUrl":null,"url":null,"abstract":"Brain-phenotype predictive models seek to identify reproducible and generalizable brain-phenotype associations. External validation, or the evaluation of a model in external datasets, is the gold standard in evaluating the generalizability of models in neuroimaging. Unlike typical studies, external validation involves two sample sizes: the training and the external sample sizes. Thus, traditional power calculations may not be appropriate. Here we ran over 900 million resampling-based simulations in functional and structural connectivity data to investigate the relationship between training sample size, external sample size, phenotype effect size, theoretical power and simulated power. Our analysis included a wide range of datasets: the Healthy Brain Network, the Adolescent Brain Cognitive Development Study, the Human Connectome Project (Development and Young Adult), the Philadelphia Neurodevelopmental Cohort, the Queensland Twin Adolescent Brain Project, and the Chinese Human Connectome Project; and phenotypes: age, body mass index, matrix reasoning, working memory, attention problems, anxiety/depression symptoms and relational processing. High effect size predictions achieved adequate power with training and external sample sizes of a few hundred individuals, whereas low and medium effect size predictions required hundreds to thousands of training and external samples. In addition, most previous external validation studies used sample sizes prone to low power, and theoretical power curves should be adjusted for the training sample size. Furthermore, model performance in internal validation often informed subsequent external validation performance (Pearson’s r difference <0.2), particularly for well-harmonized datasets. These results could help decide how to power future external validation studies. Rosenblatt et al. run over 900 million resampling-based simulations in functional and structural connectivity data to show that low and medium effect size predictions require training and external samples in the hundreds to thousands of participants.","PeriodicalId":19074,"journal":{"name":"Nature Human Behaviour","volume":"8 10","pages":"2018-2033"},"PeriodicalIF":15.9000,"publicationDate":"2024-07-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Power and reproducibility in the external validation of brain-phenotype predictions\",\"authors\":\"Matthew Rosenblatt, Link Tejavibulya, Huili Sun, Chris C. Camp, Milana Khaitova, Brendan D. Adkinson, Rongtao Jiang, Margaret L. Westwater, Stephanie Noble, Dustin Scheinost\",\"doi\":\"10.1038/s41562-024-01931-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Brain-phenotype predictive models seek to identify reproducible and generalizable brain-phenotype associations. External validation, or the evaluation of a model in external datasets, is the gold standard in evaluating the generalizability of models in neuroimaging. Unlike typical studies, external validation involves two sample sizes: the training and the external sample sizes. Thus, traditional power calculations may not be appropriate. Here we ran over 900 million resampling-based simulations in functional and structural connectivity data to investigate the relationship between training sample size, external sample size, phenotype effect size, theoretical power and simulated power. Our analysis included a wide range of datasets: the Healthy Brain Network, the Adolescent Brain Cognitive Development Study, the Human Connectome Project (Development and Young Adult), the Philadelphia Neurodevelopmental Cohort, the Queensland Twin Adolescent Brain Project, and the Chinese Human Connectome Project; and phenotypes: age, body mass index, matrix reasoning, working memory, attention problems, anxiety/depression symptoms and relational processing. High effect size predictions achieved adequate power with training and external sample sizes of a few hundred individuals, whereas low and medium effect size predictions required hundreds to thousands of training and external samples. In addition, most previous external validation studies used sample sizes prone to low power, and theoretical power curves should be adjusted for the training sample size. Furthermore, model performance in internal validation often informed subsequent external validation performance (Pearson’s r difference <0.2), particularly for well-harmonized datasets. These results could help decide how to power future external validation studies. Rosenblatt et al. run over 900 million resampling-based simulations in functional and structural connectivity data to show that low and medium effect size predictions require training and external samples in the hundreds to thousands of participants.\",\"PeriodicalId\":19074,\"journal\":{\"name\":\"Nature Human Behaviour\",\"volume\":\"8 10\",\"pages\":\"2018-2033\"},\"PeriodicalIF\":15.9000,\"publicationDate\":\"2024-07-31\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Human Behaviour\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://www.nature.com/articles/s41562-024-01931-7\",\"RegionNum\":1,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Human Behaviour","FirstCategoryId":"102","ListUrlMain":"https://www.nature.com/articles/s41562-024-01931-7","RegionNum":1,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Power and reproducibility in the external validation of brain-phenotype predictions
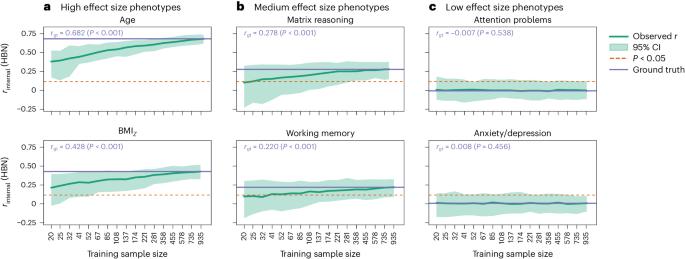
Brain-phenotype predictive models seek to identify reproducible and generalizable brain-phenotype associations. External validation, or the evaluation of a model in external datasets, is the gold standard in evaluating the generalizability of models in neuroimaging. Unlike typical studies, external validation involves two sample sizes: the training and the external sample sizes. Thus, traditional power calculations may not be appropriate. Here we ran over 900 million resampling-based simulations in functional and structural connectivity data to investigate the relationship between training sample size, external sample size, phenotype effect size, theoretical power and simulated power. Our analysis included a wide range of datasets: the Healthy Brain Network, the Adolescent Brain Cognitive Development Study, the Human Connectome Project (Development and Young Adult), the Philadelphia Neurodevelopmental Cohort, the Queensland Twin Adolescent Brain Project, and the Chinese Human Connectome Project; and phenotypes: age, body mass index, matrix reasoning, working memory, attention problems, anxiety/depression symptoms and relational processing. High effect size predictions achieved adequate power with training and external sample sizes of a few hundred individuals, whereas low and medium effect size predictions required hundreds to thousands of training and external samples. In addition, most previous external validation studies used sample sizes prone to low power, and theoretical power curves should be adjusted for the training sample size. Furthermore, model performance in internal validation often informed subsequent external validation performance (Pearson’s r difference <0.2), particularly for well-harmonized datasets. These results could help decide how to power future external validation studies. Rosenblatt et al. run over 900 million resampling-based simulations in functional and structural connectivity data to show that low and medium effect size predictions require training and external samples in the hundreds to thousands of participants.
期刊介绍:
Nature Human Behaviour is a journal that focuses on publishing research of outstanding significance into any aspect of human behavior.The research can cover various areas such as psychological, biological, and social bases of human behavior.It also includes the study of origins, development, and disorders related to human behavior.The primary aim of the journal is to increase the visibility of research in the field and enhance its societal reach and impact.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
