Jianfu Li, Yiming Li, Yuanyi Pan, Jinjing Guo, Zenan Sun, Fang Li, Yongqun He, Cui Tao
{"title":"使用级联微调特定领域语言模型将临床试验中的疫苗名称映射到疫苗本体。","authors":"Jianfu Li, Yiming Li, Yuanyi Pan, Jinjing Guo, Zenan Sun, Fang Li, Yongqun He, Cui Tao","doi":"10.1186/s13326-024-00318-x","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Vaccines have revolutionized public health by providing protection against infectious diseases. They stimulate the immune system and generate memory cells to defend against targeted diseases. Clinical trials evaluate vaccine performance, including dosage, administration routes, and potential side effects.</p><p><strong>Clinicaltrials: </strong>gov is a valuable repository of clinical trial information, but the vaccine data in them lacks standardization, leading to challenges in automatic concept mapping, vaccine-related knowledge development, evidence-based decision-making, and vaccine surveillance.</p><p><strong>Results: </strong>In this study, we developed a cascaded framework that capitalized on multiple domain knowledge sources, including clinical trials, the Unified Medical Language System (UMLS), and the Vaccine Ontology (VO), to enhance the performance of domain-specific language models for automated mapping of VO from clinical trials. The Vaccine Ontology (VO) is a community-based ontology that was developed to promote vaccine data standardization, integration, and computer-assisted reasoning. Our methodology involved extracting and annotating data from various sources. We then performed pre-training on the PubMedBERT model, leading to the development of CTPubMedBERT. Subsequently, we enhanced CTPubMedBERT by incorporating SAPBERT, which was pretrained using the UMLS, resulting in CTPubMedBERT + SAPBERT. Further refinement was accomplished through fine-tuning using the Vaccine Ontology corpus and vaccine data from clinical trials, yielding the CTPubMedBERT + SAPBERT + VO model. Finally, we utilized a collection of pre-trained models, along with the weighted rule-based ensemble approach, to normalize the vaccine corpus and improve the accuracy of the process. The ranking process in concept normalization involves prioritizing and ordering potential concepts to identify the most suitable match for a given context. We conducted a ranking of the Top 10 concepts, and our experimental results demonstrate that our proposed cascaded framework consistently outperformed existing effective baselines on vaccine mapping, achieving 71.8% on top 1 candidate's accuracy and 90.0% on top 10 candidate's accuracy.</p><p><strong>Conclusion: </strong>This study provides a detailed insight into a cascaded framework of fine-tuned domain-specific language models improving mapping of VO from clinical trials. By effectively leveraging domain-specific information and applying weighted rule-based ensembles of different pre-trained BERT models, our framework can significantly enhance the mapping of VO from clinical trials.</p>","PeriodicalId":15055,"journal":{"name":"Journal of Biomedical Semantics","volume":"15 1","pages":"14"},"PeriodicalIF":2.0000,"publicationDate":"2024-08-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11316402/pdf/","citationCount":"0","resultStr":"{\"title\":\"Mapping vaccine names in clinical trials to vaccine ontology using cascaded fine-tuned domain-specific language models.\",\"authors\":\"Jianfu Li, Yiming Li, Yuanyi Pan, Jinjing Guo, Zenan Sun, Fang Li, Yongqun He, Cui Tao\",\"doi\":\"10.1186/s13326-024-00318-x\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Vaccines have revolutionized public health by providing protection against infectious diseases. They stimulate the immune system and generate memory cells to defend against targeted diseases. Clinical trials evaluate vaccine performance, including dosage, administration routes, and potential side effects.</p><p><strong>Clinicaltrials: </strong>gov is a valuable repository of clinical trial information, but the vaccine data in them lacks standardization, leading to challenges in automatic concept mapping, vaccine-related knowledge development, evidence-based decision-making, and vaccine surveillance.</p><p><strong>Results: </strong>In this study, we developed a cascaded framework that capitalized on multiple domain knowledge sources, including clinical trials, the Unified Medical Language System (UMLS), and the Vaccine Ontology (VO), to enhance the performance of domain-specific language models for automated mapping of VO from clinical trials. The Vaccine Ontology (VO) is a community-based ontology that was developed to promote vaccine data standardization, integration, and computer-assisted reasoning. Our methodology involved extracting and annotating data from various sources. We then performed pre-training on the PubMedBERT model, leading to the development of CTPubMedBERT. Subsequently, we enhanced CTPubMedBERT by incorporating SAPBERT, which was pretrained using the UMLS, resulting in CTPubMedBERT + SAPBERT. Further refinement was accomplished through fine-tuning using the Vaccine Ontology corpus and vaccine data from clinical trials, yielding the CTPubMedBERT + SAPBERT + VO model. Finally, we utilized a collection of pre-trained models, along with the weighted rule-based ensemble approach, to normalize the vaccine corpus and improve the accuracy of the process. The ranking process in concept normalization involves prioritizing and ordering potential concepts to identify the most suitable match for a given context. We conducted a ranking of the Top 10 concepts, and our experimental results demonstrate that our proposed cascaded framework consistently outperformed existing effective baselines on vaccine mapping, achieving 71.8% on top 1 candidate's accuracy and 90.0% on top 10 candidate's accuracy.</p><p><strong>Conclusion: </strong>This study provides a detailed insight into a cascaded framework of fine-tuned domain-specific language models improving mapping of VO from clinical trials. By effectively leveraging domain-specific information and applying weighted rule-based ensembles of different pre-trained BERT models, our framework can significantly enhance the mapping of VO from clinical trials.</p>\",\"PeriodicalId\":15055,\"journal\":{\"name\":\"Journal of Biomedical Semantics\",\"volume\":\"15 1\",\"pages\":\"14\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2024-08-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11316402/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Semantics\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1186/s13326-024-00318-x\",\"RegionNum\":3,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Semantics","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1186/s13326-024-00318-x","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Mapping vaccine names in clinical trials to vaccine ontology using cascaded fine-tuned domain-specific language models.
Background: Vaccines have revolutionized public health by providing protection against infectious diseases. They stimulate the immune system and generate memory cells to defend against targeted diseases. Clinical trials evaluate vaccine performance, including dosage, administration routes, and potential side effects.
Clinicaltrials: gov is a valuable repository of clinical trial information, but the vaccine data in them lacks standardization, leading to challenges in automatic concept mapping, vaccine-related knowledge development, evidence-based decision-making, and vaccine surveillance.
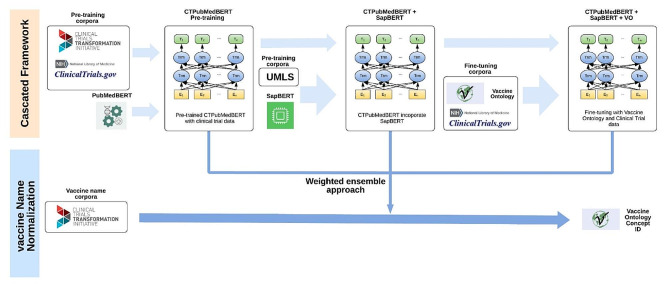
Results: In this study, we developed a cascaded framework that capitalized on multiple domain knowledge sources, including clinical trials, the Unified Medical Language System (UMLS), and the Vaccine Ontology (VO), to enhance the performance of domain-specific language models for automated mapping of VO from clinical trials. The Vaccine Ontology (VO) is a community-based ontology that was developed to promote vaccine data standardization, integration, and computer-assisted reasoning. Our methodology involved extracting and annotating data from various sources. We then performed pre-training on the PubMedBERT model, leading to the development of CTPubMedBERT. Subsequently, we enhanced CTPubMedBERT by incorporating SAPBERT, which was pretrained using the UMLS, resulting in CTPubMedBERT + SAPBERT. Further refinement was accomplished through fine-tuning using the Vaccine Ontology corpus and vaccine data from clinical trials, yielding the CTPubMedBERT + SAPBERT + VO model. Finally, we utilized a collection of pre-trained models, along with the weighted rule-based ensemble approach, to normalize the vaccine corpus and improve the accuracy of the process. The ranking process in concept normalization involves prioritizing and ordering potential concepts to identify the most suitable match for a given context. We conducted a ranking of the Top 10 concepts, and our experimental results demonstrate that our proposed cascaded framework consistently outperformed existing effective baselines on vaccine mapping, achieving 71.8% on top 1 candidate's accuracy and 90.0% on top 10 candidate's accuracy.
Conclusion: This study provides a detailed insight into a cascaded framework of fine-tuned domain-specific language models improving mapping of VO from clinical trials. By effectively leveraging domain-specific information and applying weighted rule-based ensembles of different pre-trained BERT models, our framework can significantly enhance the mapping of VO from clinical trials.
期刊介绍:
Journal of Biomedical Semantics addresses issues of semantic enrichment and semantic processing in the biomedical domain. The scope of the journal covers two main areas:
Infrastructure for biomedical semantics: focusing on semantic resources and repositories, meta-data management and resource description, knowledge representation and semantic frameworks, the Biomedical Semantic Web, and semantic interoperability.
Semantic mining, annotation, and analysis: focusing on approaches and applications of semantic resources; and tools for investigation, reasoning, prediction, and discoveries in biomedicine.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
