{"title":"多变量校准模型的调整帕累托缩放法","authors":"Kurt Varmuza, Peter Filzmoser","doi":"10.1002/cem.3588","DOIUrl":null,"url":null,"abstract":"<p>The performance of multivariate calibration models <i>ŷ</i> = f(<b><i>x</i></b>) for the prediction of a numerical property <i>y</i> from a set of <i>x</i>-variables depends on the type of scaling of the <i>x</i>-variables. Common scaling methods are autoscaling (dividing the centered <i>x</i> by its standard deviation <i>s</i>) and Pareto scaling (dividing the centered <i>x</i> by <i>s</i><sup><i>P</i></sup> with <i>P</i> = 0.5). The adjusted Pareto scaling presented here varies the exponent <i>P</i> between 0 (no scaling) and 1 (autoscaling) with the aim of obtaining an optimum prediction performance for <i>ŷ</i>. Related scaling methods based on the variable spread are range scaling and vast scaling; while level scaling is based on the location (central value) of the variable. These scaling methods and robust versions are compared for models created by partial least-squares (PLS) regression. The applied strategy repeated double cross validation (rdCV) evaluates the model performance for test set objects and considers its variability. Results with three data sets from chemistry show: (a) the efficacy of the different scaling methods depends on the data structure; (b) optimization of the Pareto exponent <i>P</i> is recommended; (c) range scaling or vast scaling may be better than adjusted Pareto scaling; (d) in general a heuristic search for the best scaling method is advisable. Overall, the consideration of different variants of scaling allow for a flexible adjustment of the variable contributions to the calibration model.</p>","PeriodicalId":15274,"journal":{"name":"Journal of Chemometrics","volume":"38 11","pages":""},"PeriodicalIF":2.3000,"publicationDate":"2024-08-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/cem.3588","citationCount":"0","resultStr":"{\"title\":\"Adjusted Pareto Scaling for Multivariate Calibration Models\",\"authors\":\"Kurt Varmuza, Peter Filzmoser\",\"doi\":\"10.1002/cem.3588\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The performance of multivariate calibration models <i>ŷ</i> = f(<b><i>x</i></b>) for the prediction of a numerical property <i>y</i> from a set of <i>x</i>-variables depends on the type of scaling of the <i>x</i>-variables. Common scaling methods are autoscaling (dividing the centered <i>x</i> by its standard deviation <i>s</i>) and Pareto scaling (dividing the centered <i>x</i> by <i>s</i><sup><i>P</i></sup> with <i>P</i> = 0.5). The adjusted Pareto scaling presented here varies the exponent <i>P</i> between 0 (no scaling) and 1 (autoscaling) with the aim of obtaining an optimum prediction performance for <i>ŷ</i>. Related scaling methods based on the variable spread are range scaling and vast scaling; while level scaling is based on the location (central value) of the variable. These scaling methods and robust versions are compared for models created by partial least-squares (PLS) regression. The applied strategy repeated double cross validation (rdCV) evaluates the model performance for test set objects and considers its variability. Results with three data sets from chemistry show: (a) the efficacy of the different scaling methods depends on the data structure; (b) optimization of the Pareto exponent <i>P</i> is recommended; (c) range scaling or vast scaling may be better than adjusted Pareto scaling; (d) in general a heuristic search for the best scaling method is advisable. Overall, the consideration of different variants of scaling allow for a flexible adjustment of the variable contributions to the calibration model.</p>\",\"PeriodicalId\":15274,\"journal\":{\"name\":\"Journal of Chemometrics\",\"volume\":\"38 11\",\"pages\":\"\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2024-08-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/cem.3588\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Chemometrics\",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/cem.3588\",\"RegionNum\":4,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"SOCIAL WORK\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Chemometrics","FirstCategoryId":"92","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/cem.3588","RegionNum":4,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"SOCIAL WORK","Score":null,"Total":0}
引用次数: 0
摘要
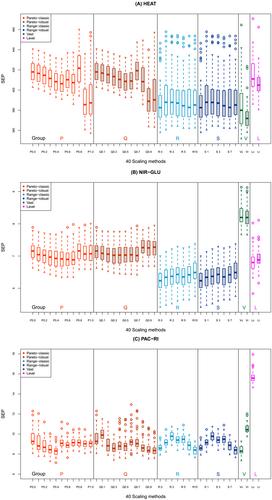
多元校准模型 ŷ = f(x)从一组 x 变量预测数值属性 y 的性能取决于 x 变量的缩放类型。常见的缩放方法有自动缩放(将中心 x 除以标准偏差 s)和帕累托缩放(将中心 x 除以 sP,p = 0.5)。本文介绍的调整帕累托缩放法在 0(无缩放)和 1(自动缩放)之间改变指数 P,目的是获得 ŷ 的最佳预测性能。基于变量分布的相关缩放方法有范围缩放和广度缩放;而水平缩放则基于变量的位置(中心值)。通过偏最小二乘(PLS)回归创建的模型,对这些缩放方法和稳健版本进行了比较。所采用的重复双重交叉验证(rdCV)策略可评估测试集对象的模型性能,并考虑其可变性。三个化学数据集的结果表明:(a) 不同缩放方法的效果取决于数据结构;(b) 建议优化帕累托指数 P;(c) 范围缩放或广域缩放可能比调整后的帕累托缩放更好;(d) 一般来说,最好采用启发式搜索最佳缩放方法。总之,考虑不同的缩放变量可以灵活调整校准模型的变量贡献。
Adjusted Pareto Scaling for Multivariate Calibration Models
The performance of multivariate calibration models ŷ = f(x) for the prediction of a numerical property y from a set of x-variables depends on the type of scaling of the x-variables. Common scaling methods are autoscaling (dividing the centered x by its standard deviation s) and Pareto scaling (dividing the centered x by sP with P = 0.5). The adjusted Pareto scaling presented here varies the exponent P between 0 (no scaling) and 1 (autoscaling) with the aim of obtaining an optimum prediction performance for ŷ. Related scaling methods based on the variable spread are range scaling and vast scaling; while level scaling is based on the location (central value) of the variable. These scaling methods and robust versions are compared for models created by partial least-squares (PLS) regression. The applied strategy repeated double cross validation (rdCV) evaluates the model performance for test set objects and considers its variability. Results with three data sets from chemistry show: (a) the efficacy of the different scaling methods depends on the data structure; (b) optimization of the Pareto exponent P is recommended; (c) range scaling or vast scaling may be better than adjusted Pareto scaling; (d) in general a heuristic search for the best scaling method is advisable. Overall, the consideration of different variants of scaling allow for a flexible adjustment of the variable contributions to the calibration model.
期刊介绍:
The Journal of Chemometrics is devoted to the rapid publication of original scientific papers, reviews and short communications on fundamental and applied aspects of chemometrics. It also provides a forum for the exchange of information on meetings and other news relevant to the growing community of scientists who are interested in chemometrics and its applications. Short, critical review papers are a particularly important feature of the journal, in view of the multidisciplinary readership at which it is aimed.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
