{"title":"利用发音表征学习进行音视频深度伪造检测","authors":"Yujia Wang, Hua Huang","doi":"10.1016/j.cviu.2024.104133","DOIUrl":null,"url":null,"abstract":"<div><p>Advancements in generative artificial intelligence have made it easier to manipulate auditory and visual elements, highlighting the critical need for robust audio–visual deepfake detection methods. In this paper, we propose an articulatory representation-based audio–visual deepfake detection approach, <em>ART-AVDF</em>. First, we devise an audio encoder to extract articulatory features that capture the physical significance of articulation movement, integrating with a lip encoder to explore audio–visual articulatory correspondences in a self-supervised learning manner. Then, we design a multimodal joint fusion module to further explore inherent audio–visual consistency using the articulatory embeddings. Extensive experiments on the DFDC, FakeAVCeleb, and DefakeAVMiT datasets demonstrate that <em>ART-AVDF</em> obtains a significant performance improvement compared to many deepfake detection models.</p></div>","PeriodicalId":50633,"journal":{"name":"Computer Vision and Image Understanding","volume":"248 ","pages":"Article 104133"},"PeriodicalIF":3.5000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Audio–visual deepfake detection using articulatory representation learning\",\"authors\":\"Yujia Wang, Hua Huang\",\"doi\":\"10.1016/j.cviu.2024.104133\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Advancements in generative artificial intelligence have made it easier to manipulate auditory and visual elements, highlighting the critical need for robust audio–visual deepfake detection methods. In this paper, we propose an articulatory representation-based audio–visual deepfake detection approach, <em>ART-AVDF</em>. First, we devise an audio encoder to extract articulatory features that capture the physical significance of articulation movement, integrating with a lip encoder to explore audio–visual articulatory correspondences in a self-supervised learning manner. Then, we design a multimodal joint fusion module to further explore inherent audio–visual consistency using the articulatory embeddings. Extensive experiments on the DFDC, FakeAVCeleb, and DefakeAVMiT datasets demonstrate that <em>ART-AVDF</em> obtains a significant performance improvement compared to many deepfake detection models.</p></div>\",\"PeriodicalId\":50633,\"journal\":{\"name\":\"Computer Vision and Image Understanding\",\"volume\":\"248 \",\"pages\":\"Article 104133\"},\"PeriodicalIF\":3.5000,\"publicationDate\":\"2024-11-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computer Vision and Image Understanding\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1077314224002145\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/8/22 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Vision and Image Understanding","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1077314224002145","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/22 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Audio–visual deepfake detection using articulatory representation learning
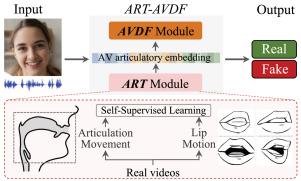
Advancements in generative artificial intelligence have made it easier to manipulate auditory and visual elements, highlighting the critical need for robust audio–visual deepfake detection methods. In this paper, we propose an articulatory representation-based audio–visual deepfake detection approach, ART-AVDF. First, we devise an audio encoder to extract articulatory features that capture the physical significance of articulation movement, integrating with a lip encoder to explore audio–visual articulatory correspondences in a self-supervised learning manner. Then, we design a multimodal joint fusion module to further explore inherent audio–visual consistency using the articulatory embeddings. Extensive experiments on the DFDC, FakeAVCeleb, and DefakeAVMiT datasets demonstrate that ART-AVDF obtains a significant performance improvement compared to many deepfake detection models.
期刊介绍:
The central focus of this journal is the computer analysis of pictorial information. Computer Vision and Image Understanding publishes papers covering all aspects of image analysis from the low-level, iconic processes of early vision to the high-level, symbolic processes of recognition and interpretation. A wide range of topics in the image understanding area is covered, including papers offering insights that differ from predominant views.
Research Areas Include:
• Theory
• Early vision
• Data structures and representations
• Shape
• Range
• Motion
• Matching and recognition
• Architecture and languages
• Vision systems




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
