{"title":"基于行列分离注意力的低照度图像/视频增强技术","authors":"Chengqi Dong, Zhiyuan Cao, Tuoshi Qi, Kexin Wu, Yixing Gao, Fan Tang","doi":"10.1111/cgf.15192","DOIUrl":null,"url":null,"abstract":"<p>U-Net structure is widely used for low-light image/video enhancement. The enhanced images result in areas with large local noise and loss of more details without proper guidance for global information. Attention mechanisms can better focus on and use global information. However, attention to images could significantly increase the number of parameters and computations. We propose a Row–Column Separated Attention module (RCSA) inserted after an improved U-Net. The RCSA module's input is the mean and maximum of the row and column of the feature map, which utilizes global information to guide local information with fewer parameters. We propose two temporal loss functions to apply the method to low-light video enhancement and maintain temporal consistency. Extensive experiments on the LOL, MIT Adobe FiveK image, and SDSD video datasets demonstrate the effectiveness of our approach.</p>","PeriodicalId":10687,"journal":{"name":"Computer Graphics Forum","volume":"43 6","pages":""},"PeriodicalIF":2.7000,"publicationDate":"2024-08-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Row–Column Separated Attention Based Low-Light Image/Video Enhancement\",\"authors\":\"Chengqi Dong, Zhiyuan Cao, Tuoshi Qi, Kexin Wu, Yixing Gao, Fan Tang\",\"doi\":\"10.1111/cgf.15192\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>U-Net structure is widely used for low-light image/video enhancement. The enhanced images result in areas with large local noise and loss of more details without proper guidance for global information. Attention mechanisms can better focus on and use global information. However, attention to images could significantly increase the number of parameters and computations. We propose a Row–Column Separated Attention module (RCSA) inserted after an improved U-Net. The RCSA module's input is the mean and maximum of the row and column of the feature map, which utilizes global information to guide local information with fewer parameters. We propose two temporal loss functions to apply the method to low-light video enhancement and maintain temporal consistency. Extensive experiments on the LOL, MIT Adobe FiveK image, and SDSD video datasets demonstrate the effectiveness of our approach.</p>\",\"PeriodicalId\":10687,\"journal\":{\"name\":\"Computer Graphics Forum\",\"volume\":\"43 6\",\"pages\":\"\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2024-08-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computer Graphics Forum\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/cgf.15192\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Graphics Forum","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/cgf.15192","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
Row–Column Separated Attention Based Low-Light Image/Video Enhancement
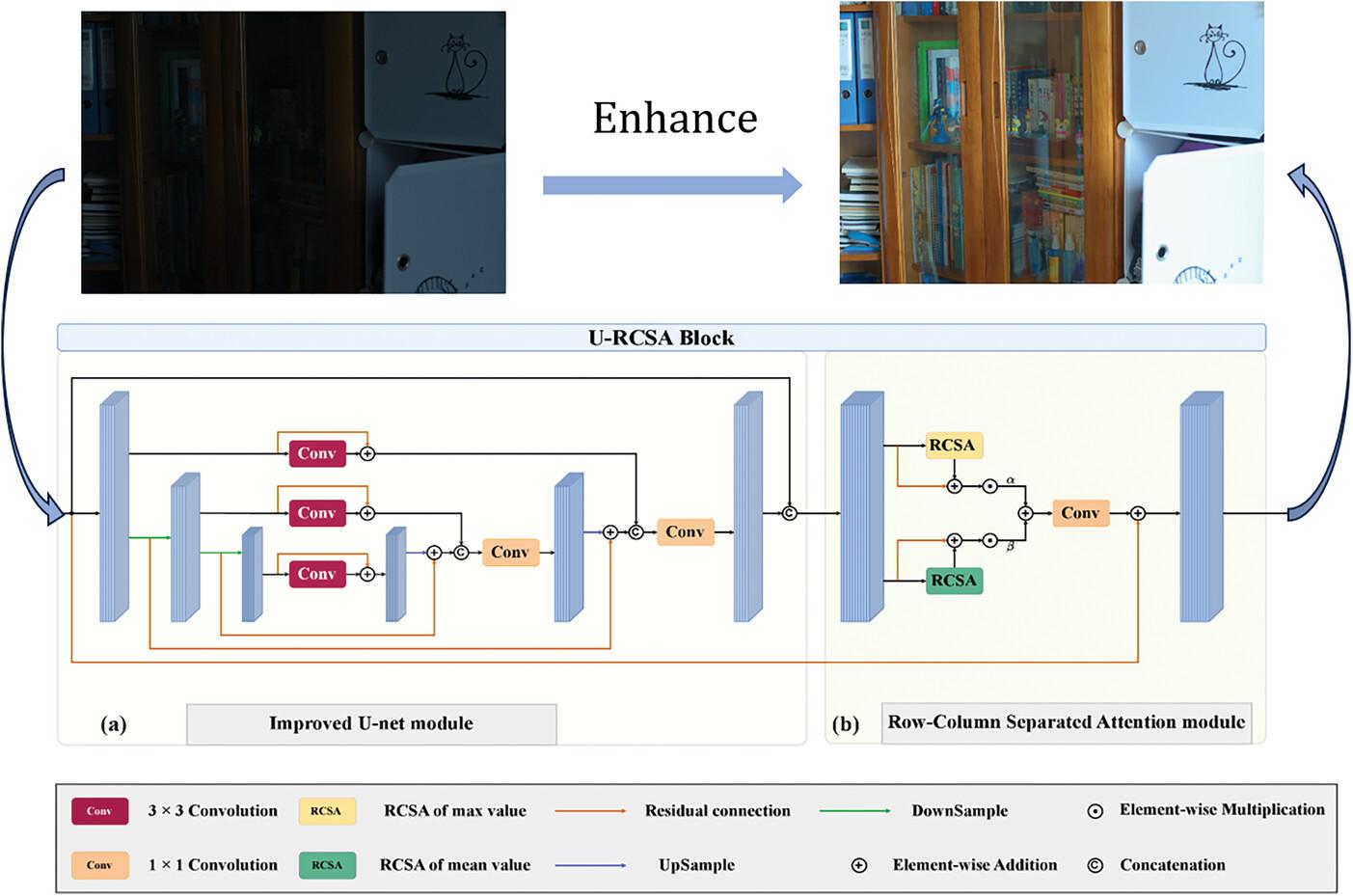
U-Net structure is widely used for low-light image/video enhancement. The enhanced images result in areas with large local noise and loss of more details without proper guidance for global information. Attention mechanisms can better focus on and use global information. However, attention to images could significantly increase the number of parameters and computations. We propose a Row–Column Separated Attention module (RCSA) inserted after an improved U-Net. The RCSA module's input is the mean and maximum of the row and column of the feature map, which utilizes global information to guide local information with fewer parameters. We propose two temporal loss functions to apply the method to low-light video enhancement and maintain temporal consistency. Extensive experiments on the LOL, MIT Adobe FiveK image, and SDSD video datasets demonstrate the effectiveness of our approach.
期刊介绍:
Computer Graphics Forum is the official journal of Eurographics, published in cooperation with Wiley-Blackwell, and is a unique, international source of information for computer graphics professionals interested in graphics developments worldwide. It is now one of the leading journals for researchers, developers and users of computer graphics in both commercial and academic environments. The journal reports on the latest developments in the field throughout the world and covers all aspects of the theory, practice and application of computer graphics.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
