Magdalena Wysocka , Oskar Wysocki , Maxime Delmas , Vincent Mutel , André Freitas
{"title":"大型语言模型、科学知识和事实性:简化人类专家评估的框架","authors":"Magdalena Wysocka , Oskar Wysocki , Maxime Delmas , Vincent Mutel , André Freitas","doi":"10.1016/j.jbi.2024.104724","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective:</h3><p>The paper introduces a framework for the evaluation of the encoding of factual scientific knowledge, designed to streamline the manual evaluation process typically conducted by domain experts. Inferring over and extracting information from Large Language Models (LLMs) trained on a large corpus of scientific literature can potentially define a step change in biomedical discovery, reducing the barriers for accessing and integrating existing medical evidence. This work explores the potential of LLMs for dialoguing with biomedical background knowledge, using the context of antibiotic discovery.</p></div><div><h3>Methods:</h3><p>The framework involves three evaluation steps, each assessing different aspects sequentially: fluency, prompt alignment, semantic coherence, factual knowledge, and specificity of the generated responses. By splitting these tasks between non-experts and experts, the framework reduces the effort required from the latter. The work provides a systematic assessment on the ability of eleven state-of-the-art LLMs, including ChatGPT, GPT-4 and Llama 2, in two prompting-based tasks: chemical compound definition generation and chemical compound–fungus relation determination.</p></div><div><h3>Results:</h3><p>Although recent models have improved in fluency, factual accuracy is still low and models are biased towards over-represented entities. The ability of LLMs to serve as biomedical knowledge bases is questioned, and the need for additional systematic evaluation frameworks is highlighted.</p></div><div><h3>Conclusion:</h3><p>While LLMs are currently not fit for purpose to be used as biomedical factual knowledge bases in a zero-shot setting, there is a promising emerging property in the direction of factuality as the models become domain specialised, scale up in size and level of human feedback.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"158 ","pages":"Article 104724"},"PeriodicalIF":4.5000,"publicationDate":"2024-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S1532046424001424/pdfft?md5=ac0ecdf9dc0e6bc7bc1738a6853505c0&pid=1-s2.0-S1532046424001424-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Large Language Models, scientific knowledge and factuality: A framework to streamline human expert evaluation\",\"authors\":\"Magdalena Wysocka , Oskar Wysocki , Maxime Delmas , Vincent Mutel , André Freitas\",\"doi\":\"10.1016/j.jbi.2024.104724\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objective:</h3><p>The paper introduces a framework for the evaluation of the encoding of factual scientific knowledge, designed to streamline the manual evaluation process typically conducted by domain experts. Inferring over and extracting information from Large Language Models (LLMs) trained on a large corpus of scientific literature can potentially define a step change in biomedical discovery, reducing the barriers for accessing and integrating existing medical evidence. This work explores the potential of LLMs for dialoguing with biomedical background knowledge, using the context of antibiotic discovery.</p></div><div><h3>Methods:</h3><p>The framework involves three evaluation steps, each assessing different aspects sequentially: fluency, prompt alignment, semantic coherence, factual knowledge, and specificity of the generated responses. By splitting these tasks between non-experts and experts, the framework reduces the effort required from the latter. The work provides a systematic assessment on the ability of eleven state-of-the-art LLMs, including ChatGPT, GPT-4 and Llama 2, in two prompting-based tasks: chemical compound definition generation and chemical compound–fungus relation determination.</p></div><div><h3>Results:</h3><p>Although recent models have improved in fluency, factual accuracy is still low and models are biased towards over-represented entities. The ability of LLMs to serve as biomedical knowledge bases is questioned, and the need for additional systematic evaluation frameworks is highlighted.</p></div><div><h3>Conclusion:</h3><p>While LLMs are currently not fit for purpose to be used as biomedical factual knowledge bases in a zero-shot setting, there is a promising emerging property in the direction of factuality as the models become domain specialised, scale up in size and level of human feedback.</p></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"158 \",\"pages\":\"Article 104724\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2024-10-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S1532046424001424/pdfft?md5=ac0ecdf9dc0e6bc7bc1738a6853505c0&pid=1-s2.0-S1532046424001424-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424001424\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/9/12 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424001424","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/12 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
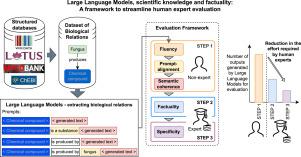
Large Language Models, scientific knowledge and factuality: A framework to streamline human expert evaluation
Objective:
The paper introduces a framework for the evaluation of the encoding of factual scientific knowledge, designed to streamline the manual evaluation process typically conducted by domain experts. Inferring over and extracting information from Large Language Models (LLMs) trained on a large corpus of scientific literature can potentially define a step change in biomedical discovery, reducing the barriers for accessing and integrating existing medical evidence. This work explores the potential of LLMs for dialoguing with biomedical background knowledge, using the context of antibiotic discovery.
Methods:
The framework involves three evaluation steps, each assessing different aspects sequentially: fluency, prompt alignment, semantic coherence, factual knowledge, and specificity of the generated responses. By splitting these tasks between non-experts and experts, the framework reduces the effort required from the latter. The work provides a systematic assessment on the ability of eleven state-of-the-art LLMs, including ChatGPT, GPT-4 and Llama 2, in two prompting-based tasks: chemical compound definition generation and chemical compound–fungus relation determination.
Results:
Although recent models have improved in fluency, factual accuracy is still low and models are biased towards over-represented entities. The ability of LLMs to serve as biomedical knowledge bases is questioned, and the need for additional systematic evaluation frameworks is highlighted.
Conclusion:
While LLMs are currently not fit for purpose to be used as biomedical factual knowledge bases in a zero-shot setting, there is a promising emerging property in the direction of factuality as the models become domain specialised, scale up in size and level of human feedback.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
