{"title":"利用 K-anonymity 和统计机器学习方法,通过基于信任的服务机制增强云网络安全","authors":"Himani Saini, Gopal Singh, Sandeep Dalal, Umesh Kumar Lilhore, Sarita Simaiya, Surjeet Dalal","doi":"10.1007/s12083-024-01759-y","DOIUrl":null,"url":null,"abstract":"<p>This Research work addresses the pressing need within cloud computing for a trust-based service mechanism that effectively manages the burgeoning volume and variety of data while mitigating privacy concerns. The primary aim is to address pressing security challenges within cloud networks through a novel approach tailored to enhance privacy preservation mechanisms. Experiments were done on a variety of datasets using a hybrid privacy-preserving strategy to assess the efficacy of the suggested solution. The datasets were divided into both testing and training sets for the experimental design, using a 70% validation ratio for training. The method's performance was compared with that of existing strategies, including caching and spatial K-anonymity (CSKA) and privacy-preserving incentive and rewarding (PPIR), using precision, recall, and F-measure analysis. The findings show that the suggested strategy performs better than the baseline approaches in a number of assessment measures, indicating its greater capacity to protect privacy in cloud environments. Specifically, the approach achieved an average precision of 0.85, significantly surpassing the precision values of existing techniques by 8-10%. Moreover, the method exhibited an average recall of 0.84, indicating its robustness in recalling values across all test samples. Across various experiments, our method consistently achieved impressive F1 scores ranging from 0.80 to 0.85, underscoring its robustness in maintaining a balance between precision and recall. Furthermore, with an accuracy hovering around 0.85, our approach demonstrated remarkable proficiency in accurately classifying instances while preserving privacy in cloud environments. These promising results underscore the efficacy of the proposed approach in enhancing privacy preservation mechanisms within cloud networks, paving the way for more secure and reliable cloud computing infrastructures. By leveraging a hybrid privacy-preserving method, the paper offers a holistic approach to address the complex problems faced by cloud networks in safeguarding sensitive information. The experimental evaluation demonstrates the efficacy of the proposed approach, highlighting its superior performance compared to existing techniques.</p>","PeriodicalId":49313,"journal":{"name":"Peer-To-Peer Networking and Applications","volume":"2 1","pages":""},"PeriodicalIF":2.6000,"publicationDate":"2024-09-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Enhancing cloud network security with a trust-based service mechanism using k-anonymity and statistical machine learning approach\",\"authors\":\"Himani Saini, Gopal Singh, Sandeep Dalal, Umesh Kumar Lilhore, Sarita Simaiya, Surjeet Dalal\",\"doi\":\"10.1007/s12083-024-01759-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>This Research work addresses the pressing need within cloud computing for a trust-based service mechanism that effectively manages the burgeoning volume and variety of data while mitigating privacy concerns. The primary aim is to address pressing security challenges within cloud networks through a novel approach tailored to enhance privacy preservation mechanisms. Experiments were done on a variety of datasets using a hybrid privacy-preserving strategy to assess the efficacy of the suggested solution. The datasets were divided into both testing and training sets for the experimental design, using a 70% validation ratio for training. The method's performance was compared with that of existing strategies, including caching and spatial K-anonymity (CSKA) and privacy-preserving incentive and rewarding (PPIR), using precision, recall, and F-measure analysis. The findings show that the suggested strategy performs better than the baseline approaches in a number of assessment measures, indicating its greater capacity to protect privacy in cloud environments. Specifically, the approach achieved an average precision of 0.85, significantly surpassing the precision values of existing techniques by 8-10%. Moreover, the method exhibited an average recall of 0.84, indicating its robustness in recalling values across all test samples. Across various experiments, our method consistently achieved impressive F1 scores ranging from 0.80 to 0.85, underscoring its robustness in maintaining a balance between precision and recall. Furthermore, with an accuracy hovering around 0.85, our approach demonstrated remarkable proficiency in accurately classifying instances while preserving privacy in cloud environments. These promising results underscore the efficacy of the proposed approach in enhancing privacy preservation mechanisms within cloud networks, paving the way for more secure and reliable cloud computing infrastructures. By leveraging a hybrid privacy-preserving method, the paper offers a holistic approach to address the complex problems faced by cloud networks in safeguarding sensitive information. The experimental evaluation demonstrates the efficacy of the proposed approach, highlighting its superior performance compared to existing techniques.</p>\",\"PeriodicalId\":49313,\"journal\":{\"name\":\"Peer-To-Peer Networking and Applications\",\"volume\":\"2 1\",\"pages\":\"\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2024-09-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Peer-To-Peer Networking and Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s12083-024-01759-y\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Peer-To-Peer Networking and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s12083-024-01759-y","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Enhancing cloud network security with a trust-based service mechanism using k-anonymity and statistical machine learning approach
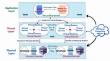
This Research work addresses the pressing need within cloud computing for a trust-based service mechanism that effectively manages the burgeoning volume and variety of data while mitigating privacy concerns. The primary aim is to address pressing security challenges within cloud networks through a novel approach tailored to enhance privacy preservation mechanisms. Experiments were done on a variety of datasets using a hybrid privacy-preserving strategy to assess the efficacy of the suggested solution. The datasets were divided into both testing and training sets for the experimental design, using a 70% validation ratio for training. The method's performance was compared with that of existing strategies, including caching and spatial K-anonymity (CSKA) and privacy-preserving incentive and rewarding (PPIR), using precision, recall, and F-measure analysis. The findings show that the suggested strategy performs better than the baseline approaches in a number of assessment measures, indicating its greater capacity to protect privacy in cloud environments. Specifically, the approach achieved an average precision of 0.85, significantly surpassing the precision values of existing techniques by 8-10%. Moreover, the method exhibited an average recall of 0.84, indicating its robustness in recalling values across all test samples. Across various experiments, our method consistently achieved impressive F1 scores ranging from 0.80 to 0.85, underscoring its robustness in maintaining a balance between precision and recall. Furthermore, with an accuracy hovering around 0.85, our approach demonstrated remarkable proficiency in accurately classifying instances while preserving privacy in cloud environments. These promising results underscore the efficacy of the proposed approach in enhancing privacy preservation mechanisms within cloud networks, paving the way for more secure and reliable cloud computing infrastructures. By leveraging a hybrid privacy-preserving method, the paper offers a holistic approach to address the complex problems faced by cloud networks in safeguarding sensitive information. The experimental evaluation demonstrates the efficacy of the proposed approach, highlighting its superior performance compared to existing techniques.
期刊介绍:
The aim of the Peer-to-Peer Networking and Applications journal is to disseminate state-of-the-art research and development results in this rapidly growing research area, to facilitate the deployment of P2P networking and applications, and to bring together the academic and industry communities, with the goal of fostering interaction to promote further research interests and activities, thus enabling new P2P applications and services. The journal not only addresses research topics related to networking and communications theory, but also considers the standardization, economic, and engineering aspects of P2P technologies, and their impacts on software engineering, computer engineering, networked communication, and security.
The journal serves as a forum for tackling the technical problems arising from both file sharing and media streaming applications. It also includes state-of-the-art technologies in the P2P security domain.
Peer-to-Peer Networking and Applications publishes regular papers, tutorials and review papers, case studies, and correspondence from the research, development, and standardization communities. Papers addressing system, application, and service issues are encouraged.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
