Dongli Wang, Xiaolin Zhu, Jinfu Liu, Zixin Zhang, Yan Zhou
{"title":"用于群体活动识别的多维卷积变换器","authors":"Dongli Wang, Xiaolin Zhu, Jinfu Liu, Zixin Zhang, Yan Zhou","doi":"10.1007/s11042-024-19973-4","DOIUrl":null,"url":null,"abstract":"<p>Group activity recognition, which aims to understand the activity performed by a group of people, has attracted growing attention in the realm of computer vision over the past decade. In this paper, we propose a novel multi-dimensional convolution Transformer network for group activity recognition, which not only models spatial-temporal feature representations, but also combines channel information to analyze the spatial-temporal dependencies of individual actors. Specifically, we first construct a multi-scale feature extraction module in the feature extraction stage, which can exploit discriminative high-level and low-level feature representations. The multi-branching strategy combined with the dilated convolution can further capture multi-scale feature information in complex group scenarios. Then, to construct the inter-dependence among involved actors from different dimensions, we design a multi-dimensional convolution Transformer in the relational reasoning stage, which consists of the following three parts: a channel attention module, a spatial-temporal convolutional Transformer, and a spatial-temporal attention module. Finally, the final activity recognition result is obtained by using a softmax classifier. Extensive experiments on two public GAR datasets demonstrate that the recognition accuracy on the Volleyball Dataset and Collective Activity Dataset can reach 92.8% and 96.1%, respectively, which is a significant improvement compared with the mainstream methods in recent years.</p>","PeriodicalId":18770,"journal":{"name":"Multimedia Tools and Applications","volume":"32 1","pages":""},"PeriodicalIF":3.0000,"publicationDate":"2024-09-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Multi-dimensional convolution transformer for group activity recognition\",\"authors\":\"Dongli Wang, Xiaolin Zhu, Jinfu Liu, Zixin Zhang, Yan Zhou\",\"doi\":\"10.1007/s11042-024-19973-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Group activity recognition, which aims to understand the activity performed by a group of people, has attracted growing attention in the realm of computer vision over the past decade. In this paper, we propose a novel multi-dimensional convolution Transformer network for group activity recognition, which not only models spatial-temporal feature representations, but also combines channel information to analyze the spatial-temporal dependencies of individual actors. Specifically, we first construct a multi-scale feature extraction module in the feature extraction stage, which can exploit discriminative high-level and low-level feature representations. The multi-branching strategy combined with the dilated convolution can further capture multi-scale feature information in complex group scenarios. Then, to construct the inter-dependence among involved actors from different dimensions, we design a multi-dimensional convolution Transformer in the relational reasoning stage, which consists of the following three parts: a channel attention module, a spatial-temporal convolutional Transformer, and a spatial-temporal attention module. Finally, the final activity recognition result is obtained by using a softmax classifier. Extensive experiments on two public GAR datasets demonstrate that the recognition accuracy on the Volleyball Dataset and Collective Activity Dataset can reach 92.8% and 96.1%, respectively, which is a significant improvement compared with the mainstream methods in recent years.</p>\",\"PeriodicalId\":18770,\"journal\":{\"name\":\"Multimedia Tools and Applications\",\"volume\":\"32 1\",\"pages\":\"\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2024-09-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Multimedia Tools and Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11042-024-19973-4\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Multimedia Tools and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11042-024-19973-4","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
摘要
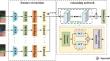
群体活动识别旨在了解一群人所进行的活动,在过去十年中,它在计算机视觉领域引起了越来越多的关注。在本文中,我们提出了一种用于群体活动识别的新型多维卷积变换器网络,它不仅能建立时空特征表征模型,还能结合通道信息来分析单个参与者的时空依赖关系。具体来说,我们首先在特征提取阶段构建了一个多尺度特征提取模块,该模块可以利用具有区分性的高层和低层特征表征。多分支策略与扩张卷积相结合,可以进一步捕捉复杂群体场景中的多尺度特征信息。然后,为了从不同维度构建参与者之间的相互依存关系,我们在关系推理阶段设计了一个多维卷积变换器,它由以下三个部分组成:通道注意模块、时空卷积变换器和时空注意模块。最后,使用软最大分类器得出最终的活动识别结果。在两个公开的 GAR 数据集上进行的大量实验表明,排球数据集和集体活动数据集的识别准确率分别达到了 92.8% 和 96.1%,与近年来的主流方法相比有了显著提高。
Multi-dimensional convolution transformer for group activity recognition
Group activity recognition, which aims to understand the activity performed by a group of people, has attracted growing attention in the realm of computer vision over the past decade. In this paper, we propose a novel multi-dimensional convolution Transformer network for group activity recognition, which not only models spatial-temporal feature representations, but also combines channel information to analyze the spatial-temporal dependencies of individual actors. Specifically, we first construct a multi-scale feature extraction module in the feature extraction stage, which can exploit discriminative high-level and low-level feature representations. The multi-branching strategy combined with the dilated convolution can further capture multi-scale feature information in complex group scenarios. Then, to construct the inter-dependence among involved actors from different dimensions, we design a multi-dimensional convolution Transformer in the relational reasoning stage, which consists of the following three parts: a channel attention module, a spatial-temporal convolutional Transformer, and a spatial-temporal attention module. Finally, the final activity recognition result is obtained by using a softmax classifier. Extensive experiments on two public GAR datasets demonstrate that the recognition accuracy on the Volleyball Dataset and Collective Activity Dataset can reach 92.8% and 96.1%, respectively, which is a significant improvement compared with the mainstream methods in recent years.
期刊介绍:
Multimedia Tools and Applications publishes original research articles on multimedia development and system support tools as well as case studies of multimedia applications. It also features experimental and survey articles. The journal is intended for academics, practitioners, scientists and engineers who are involved in multimedia system research, design and applications. All papers are peer reviewed.
Specific areas of interest include:
- Multimedia Tools:
- Multimedia Applications:
- Prototype multimedia systems and platforms




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
