{"title":"DFCNet +:用于连续手语识别的跨模态动态特征对比网","authors":"Yuan Feng , Nuoyi Chen , Yumeng Wu , Caoyu Jiang , Sheng Liu , Shengyong Chen","doi":"10.1016/j.imavis.2024.105260","DOIUrl":null,"url":null,"abstract":"<div><div>In sign language communication, the combination of hand signs and facial expressions is used to convey messages in a fluid manner. Accurate interpretation relies heavily on understanding the context of these signs. Current methods, however, often focus on static images, missing the continuous flow and the story that unfolds through successive movements in sign language. To address this constraint, our research introduces the Dynamic Feature Contrast Net Plus (DFCNet<!--> <!-->+), a novel model that incorporates both dynamic feature extraction and cross-modal learning. The dynamic feature extraction module of DFCNet<!--> <!-->+ uses dynamic trajectory capture to monitor and record motion across frames and apply key features as an enhancement tool that highlights pixels that are critical for recognizing important sign language movements, allowing the model to follow the temporal variation of the signs. In the cross-modal learning module, we depart from the conventional approach of aligning video frames with textual descriptions. Instead, we adopt a gloss-level alignment, which provides a more detailed match between the visual signals and their corresponding text glosses, capturing the intricate relationship between what is seen and the associated text. The enhanced proficiency of DFCNet<!--> <!-->+ in discerning inter-frame details translates to heightened precision on benchmarks such as PHOENIX14, PHOENIX14-T and CSL-Daily. Such performance underscores its advantage in dynamic feature capture and inter-modal learning compared to conventional approaches to sign language interpretation. Our code is available at <span><span>https://github.com/fyzjut/DFCNet_Plus</span><svg><path></path></svg></span>.</div></div>","PeriodicalId":50374,"journal":{"name":"Image and Vision Computing","volume":"151 ","pages":"Article 105260"},"PeriodicalIF":4.2000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"DFCNet +: Cross-modal dynamic feature contrast net for continuous sign language recognition\",\"authors\":\"Yuan Feng , Nuoyi Chen , Yumeng Wu , Caoyu Jiang , Sheng Liu , Shengyong Chen\",\"doi\":\"10.1016/j.imavis.2024.105260\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>In sign language communication, the combination of hand signs and facial expressions is used to convey messages in a fluid manner. Accurate interpretation relies heavily on understanding the context of these signs. Current methods, however, often focus on static images, missing the continuous flow and the story that unfolds through successive movements in sign language. To address this constraint, our research introduces the Dynamic Feature Contrast Net Plus (DFCNet<!--> <!-->+), a novel model that incorporates both dynamic feature extraction and cross-modal learning. The dynamic feature extraction module of DFCNet<!--> <!-->+ uses dynamic trajectory capture to monitor and record motion across frames and apply key features as an enhancement tool that highlights pixels that are critical for recognizing important sign language movements, allowing the model to follow the temporal variation of the signs. In the cross-modal learning module, we depart from the conventional approach of aligning video frames with textual descriptions. Instead, we adopt a gloss-level alignment, which provides a more detailed match between the visual signals and their corresponding text glosses, capturing the intricate relationship between what is seen and the associated text. The enhanced proficiency of DFCNet<!--> <!-->+ in discerning inter-frame details translates to heightened precision on benchmarks such as PHOENIX14, PHOENIX14-T and CSL-Daily. Such performance underscores its advantage in dynamic feature capture and inter-modal learning compared to conventional approaches to sign language interpretation. Our code is available at <span><span>https://github.com/fyzjut/DFCNet_Plus</span><svg><path></path></svg></span>.</div></div>\",\"PeriodicalId\":50374,\"journal\":{\"name\":\"Image and Vision Computing\",\"volume\":\"151 \",\"pages\":\"Article 105260\"},\"PeriodicalIF\":4.2000,\"publicationDate\":\"2024-11-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Image and Vision Computing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0262885624003652\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/9/11 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Image and Vision Computing","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0262885624003652","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/11 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
DFCNet +: Cross-modal dynamic feature contrast net for continuous sign language recognition
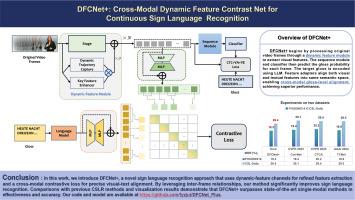
In sign language communication, the combination of hand signs and facial expressions is used to convey messages in a fluid manner. Accurate interpretation relies heavily on understanding the context of these signs. Current methods, however, often focus on static images, missing the continuous flow and the story that unfolds through successive movements in sign language. To address this constraint, our research introduces the Dynamic Feature Contrast Net Plus (DFCNet +), a novel model that incorporates both dynamic feature extraction and cross-modal learning. The dynamic feature extraction module of DFCNet + uses dynamic trajectory capture to monitor and record motion across frames and apply key features as an enhancement tool that highlights pixels that are critical for recognizing important sign language movements, allowing the model to follow the temporal variation of the signs. In the cross-modal learning module, we depart from the conventional approach of aligning video frames with textual descriptions. Instead, we adopt a gloss-level alignment, which provides a more detailed match between the visual signals and their corresponding text glosses, capturing the intricate relationship between what is seen and the associated text. The enhanced proficiency of DFCNet + in discerning inter-frame details translates to heightened precision on benchmarks such as PHOENIX14, PHOENIX14-T and CSL-Daily. Such performance underscores its advantage in dynamic feature capture and inter-modal learning compared to conventional approaches to sign language interpretation. Our code is available at https://github.com/fyzjut/DFCNet_Plus.
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
