Gaelen P Adam, Jay DeYoung, Alice Paul, Ian J Saldanha, Ethan M Balk, Thomas A Trikalinos, Byron C Wallace
{"title":"文献检索沙箱:为系统综述生成检索查询的大型语言模型。","authors":"Gaelen P Adam, Jay DeYoung, Alice Paul, Ian J Saldanha, Ethan M Balk, Thomas A Trikalinos, Byron C Wallace","doi":"10.1093/jamiaopen/ooae098","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Development of search queries for systematic reviews (SRs) is time-consuming. In this work, we capitalize on recent advances in large language models (LLMs) and a relatively large dataset of natural language descriptions of reviews and corresponding Boolean searches to generate Boolean search queries from SR titles and key questions.</p><p><strong>Materials and methods: </strong>We curated a training dataset of 10 346 SR search queries registered in PROSPERO. We used this dataset to fine-tune a set of models to generate search queries based on Mistral-Instruct-7b. We evaluated the models quantitatively using an evaluation dataset of 57 SRs and qualitatively through semi-structured interviews with 8 experienced medical librarians.</p><p><strong>Results: </strong>The model-generated search queries had median sensitivity of 85% (interquartile range [IQR] 40%-100%) and number needed to read of 1206 citations (IQR 205-5810). The interviews suggested that the models lack both the necessary sensitivity and precision to be used without scrutiny but could be useful for topic scoping or as initial queries to be refined.</p><p><strong>Discussion: </strong>Future research should focus on improving the dataset with more high-quality search queries, assessing whether fine-tuning the model on other fields, such as the population and intervention, improves performance, and exploring the addition of interactivity to the interface.</p><p><strong>Conclusions: </strong>The datasets developed for this project can be used to train and evaluate LLMs that map review descriptions to Boolean search queries. The models cannot replace thoughtful search query design but may be useful in providing suggestions for key words and the framework for the query.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"7 3","pages":"ooae098"},"PeriodicalIF":3.4000,"publicationDate":"2024-09-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11424077/pdf/","citationCount":"0","resultStr":"{\"title\":\"<i>Literature search sandbox</i>: a large language model that generates search queries for systematic reviews.\",\"authors\":\"Gaelen P Adam, Jay DeYoung, Alice Paul, Ian J Saldanha, Ethan M Balk, Thomas A Trikalinos, Byron C Wallace\",\"doi\":\"10.1093/jamiaopen/ooae098\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>Development of search queries for systematic reviews (SRs) is time-consuming. In this work, we capitalize on recent advances in large language models (LLMs) and a relatively large dataset of natural language descriptions of reviews and corresponding Boolean searches to generate Boolean search queries from SR titles and key questions.</p><p><strong>Materials and methods: </strong>We curated a training dataset of 10 346 SR search queries registered in PROSPERO. We used this dataset to fine-tune a set of models to generate search queries based on Mistral-Instruct-7b. We evaluated the models quantitatively using an evaluation dataset of 57 SRs and qualitatively through semi-structured interviews with 8 experienced medical librarians.</p><p><strong>Results: </strong>The model-generated search queries had median sensitivity of 85% (interquartile range [IQR] 40%-100%) and number needed to read of 1206 citations (IQR 205-5810). The interviews suggested that the models lack both the necessary sensitivity and precision to be used without scrutiny but could be useful for topic scoping or as initial queries to be refined.</p><p><strong>Discussion: </strong>Future research should focus on improving the dataset with more high-quality search queries, assessing whether fine-tuning the model on other fields, such as the population and intervention, improves performance, and exploring the addition of interactivity to the interface.</p><p><strong>Conclusions: </strong>The datasets developed for this project can be used to train and evaluate LLMs that map review descriptions to Boolean search queries. The models cannot replace thoughtful search query design but may be useful in providing suggestions for key words and the framework for the query.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"7 3\",\"pages\":\"ooae098\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2024-09-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11424077/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooae098\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooae098","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Literature search sandbox: a large language model that generates search queries for systematic reviews.
Objectives: Development of search queries for systematic reviews (SRs) is time-consuming. In this work, we capitalize on recent advances in large language models (LLMs) and a relatively large dataset of natural language descriptions of reviews and corresponding Boolean searches to generate Boolean search queries from SR titles and key questions.
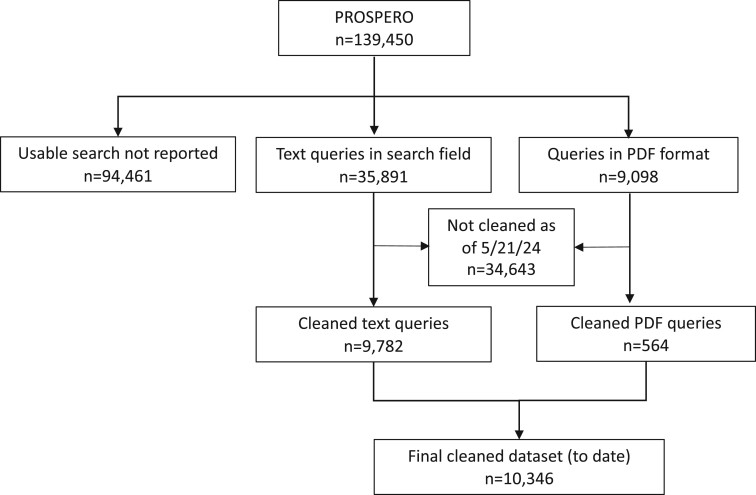
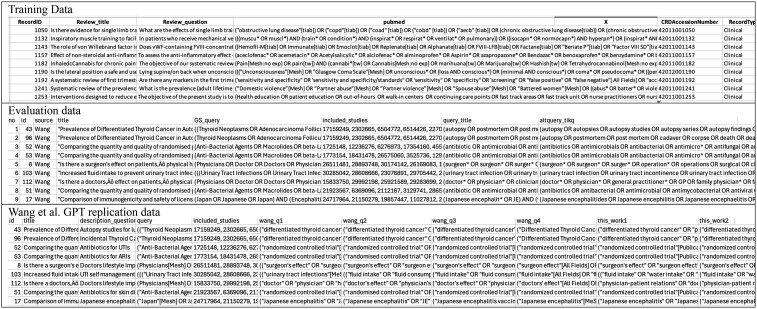
Materials and methods: We curated a training dataset of 10 346 SR search queries registered in PROSPERO. We used this dataset to fine-tune a set of models to generate search queries based on Mistral-Instruct-7b. We evaluated the models quantitatively using an evaluation dataset of 57 SRs and qualitatively through semi-structured interviews with 8 experienced medical librarians.
Results: The model-generated search queries had median sensitivity of 85% (interquartile range [IQR] 40%-100%) and number needed to read of 1206 citations (IQR 205-5810). The interviews suggested that the models lack both the necessary sensitivity and precision to be used without scrutiny but could be useful for topic scoping or as initial queries to be refined.
Discussion: Future research should focus on improving the dataset with more high-quality search queries, assessing whether fine-tuning the model on other fields, such as the population and intervention, improves performance, and exploring the addition of interactivity to the interface.
Conclusions: The datasets developed for this project can be used to train and evaluate LLMs that map review descriptions to Boolean search queries. The models cannot replace thoughtful search query design but may be useful in providing suggestions for key words and the framework for the query.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
