{"title":"动态决策中的 \"Tweedledum \"和 \"Tweedledee\":区分扩散决策模型和累加器模型。","authors":"Peter D Kvam","doi":"10.3758/s13423-024-02587-0","DOIUrl":null,"url":null,"abstract":"<p><p>Theories of dynamic decision-making are typically built on evidence accumulation, which is modeled using racing accumulators or diffusion models that track a shifting balance of support over time. However, these two types of models are only two special cases of a more general evidence accumulation process where options correspond to directions in an accumulation space. Using this generalized evidence accumulation approach as a starting point, I identify four ways to discriminate between absolute-evidence and relative-evidence models. First, an experimenter can look at the information that decision-makers considered to identify whether there is a filtering of near-zero evidence samples, which is characteristic of a relative-evidence decision rule (e.g., diffusion decision model). Second, an experimenter can disentangle different components of drift rates by manipulating the discriminability of the two response options relative to the stimulus to delineate the balance of evidence from the total amount of evidence. Third, a modeler can use machine learning to classify a set of data according to its generative model. Finally, machine learning can also be used to directly estimate the geometric relationships between choice options. I illustrate these different approaches by applying them to data from an orientation-discrimination task, showing converging conclusions across all four methods in favor of accumulator-based representations of evidence during choice. These tools can clearly delineate absolute-evidence and relative-evidence models, and should be useful for comparing many other types of decision theories.</p>","PeriodicalId":20763,"journal":{"name":"Psychonomic Bulletin & Review","volume":" ","pages":"588-613"},"PeriodicalIF":3.1000,"publicationDate":"2025-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12000211/pdf/","citationCount":"0","resultStr":"{\"title\":\"The Tweedledum and Tweedledee of dynamic decisions: Discriminating between diffusion decision and accumulator models.\",\"authors\":\"Peter D Kvam\",\"doi\":\"10.3758/s13423-024-02587-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Theories of dynamic decision-making are typically built on evidence accumulation, which is modeled using racing accumulators or diffusion models that track a shifting balance of support over time. However, these two types of models are only two special cases of a more general evidence accumulation process where options correspond to directions in an accumulation space. Using this generalized evidence accumulation approach as a starting point, I identify four ways to discriminate between absolute-evidence and relative-evidence models. First, an experimenter can look at the information that decision-makers considered to identify whether there is a filtering of near-zero evidence samples, which is characteristic of a relative-evidence decision rule (e.g., diffusion decision model). Second, an experimenter can disentangle different components of drift rates by manipulating the discriminability of the two response options relative to the stimulus to delineate the balance of evidence from the total amount of evidence. Third, a modeler can use machine learning to classify a set of data according to its generative model. Finally, machine learning can also be used to directly estimate the geometric relationships between choice options. I illustrate these different approaches by applying them to data from an orientation-discrimination task, showing converging conclusions across all four methods in favor of accumulator-based representations of evidence during choice. These tools can clearly delineate absolute-evidence and relative-evidence models, and should be useful for comparing many other types of decision theories.</p>\",\"PeriodicalId\":20763,\"journal\":{\"name\":\"Psychonomic Bulletin & Review\",\"volume\":\" \",\"pages\":\"588-613\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2025-04-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12000211/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Psychonomic Bulletin & Review\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://doi.org/10.3758/s13423-024-02587-0\",\"RegionNum\":3,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/1 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"PSYCHOLOGY, EXPERIMENTAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Psychonomic Bulletin & Review","FirstCategoryId":"102","ListUrlMain":"https://doi.org/10.3758/s13423-024-02587-0","RegionNum":3,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/1 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"PSYCHOLOGY, EXPERIMENTAL","Score":null,"Total":0}
The Tweedledum and Tweedledee of dynamic decisions: Discriminating between diffusion decision and accumulator models.
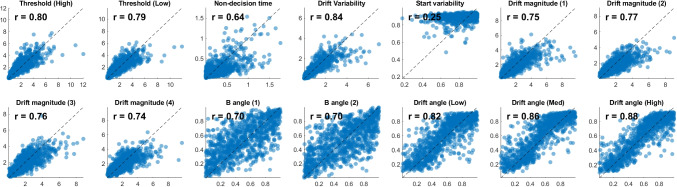
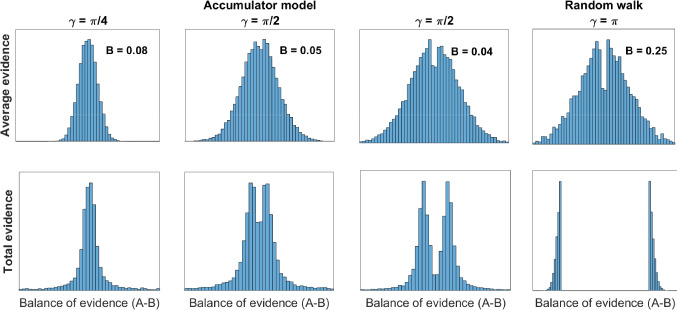
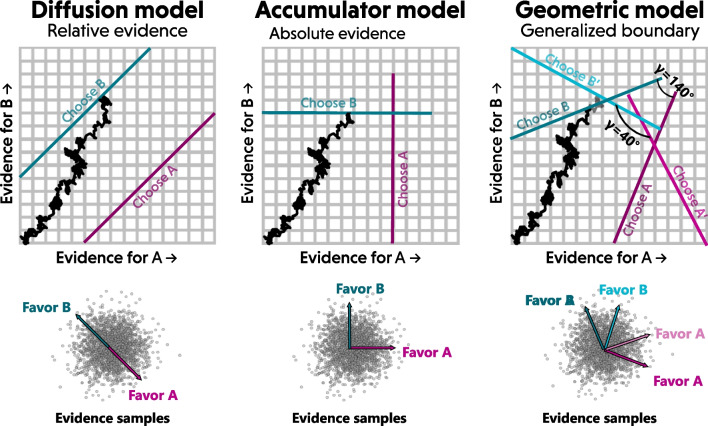
Theories of dynamic decision-making are typically built on evidence accumulation, which is modeled using racing accumulators or diffusion models that track a shifting balance of support over time. However, these two types of models are only two special cases of a more general evidence accumulation process where options correspond to directions in an accumulation space. Using this generalized evidence accumulation approach as a starting point, I identify four ways to discriminate between absolute-evidence and relative-evidence models. First, an experimenter can look at the information that decision-makers considered to identify whether there is a filtering of near-zero evidence samples, which is characteristic of a relative-evidence decision rule (e.g., diffusion decision model). Second, an experimenter can disentangle different components of drift rates by manipulating the discriminability of the two response options relative to the stimulus to delineate the balance of evidence from the total amount of evidence. Third, a modeler can use machine learning to classify a set of data according to its generative model. Finally, machine learning can also be used to directly estimate the geometric relationships between choice options. I illustrate these different approaches by applying them to data from an orientation-discrimination task, showing converging conclusions across all four methods in favor of accumulator-based representations of evidence during choice. These tools can clearly delineate absolute-evidence and relative-evidence models, and should be useful for comparing many other types of decision theories.
期刊介绍:
The journal provides coverage spanning a broad spectrum of topics in all areas of experimental psychology. The journal is primarily dedicated to the publication of theory and review articles and brief reports of outstanding experimental work. Areas of coverage include cognitive psychology broadly construed, including but not limited to action, perception, & attention, language, learning & memory, reasoning & decision making, and social cognition. We welcome submissions that approach these issues from a variety of perspectives such as behavioral measurements, comparative psychology, development, evolutionary psychology, genetics, neuroscience, and quantitative/computational modeling. We particularly encourage integrative research that crosses traditional content and methodological boundaries.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
