{"title":"评估分析课堂对话的大型语言模型。","authors":"Yun Long, Haifeng Luo, Yu Zhang","doi":"10.1038/s41539-024-00273-3","DOIUrl":null,"url":null,"abstract":"<p><p>This study explores the use of Large Language Models (LLMs), specifically GPT-4, in analysing classroom dialogue-a key task for teaching diagnosis and quality improvement. Traditional qualitative methods are both knowledge- and labour-intensive. This research investigates the potential of LLMs to streamline and enhance this process. Using datasets from middle school mathematics and Chinese classes, classroom dialogues were manually coded by experts and then analysed with a customised GPT-4 model. The study compares manual annotations with GPT-4 outputs to evaluate efficacy. Metrics include time efficiency, inter-coder agreement, and reliability between human coders and GPT-4. Results show significant time savings and high coding consistency between the model and human coders, with minor discrepancies. These findings highlight the strong potential of LLMs in teaching evaluation and facilitation.</p>","PeriodicalId":48503,"journal":{"name":"npj Science of Learning","volume":"9 1","pages":"60"},"PeriodicalIF":3.0000,"publicationDate":"2024-10-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11447259/pdf/","citationCount":"0","resultStr":"{\"title\":\"Evaluating large language models in analysing classroom dialogue.\",\"authors\":\"Yun Long, Haifeng Luo, Yu Zhang\",\"doi\":\"10.1038/s41539-024-00273-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>This study explores the use of Large Language Models (LLMs), specifically GPT-4, in analysing classroom dialogue-a key task for teaching diagnosis and quality improvement. Traditional qualitative methods are both knowledge- and labour-intensive. This research investigates the potential of LLMs to streamline and enhance this process. Using datasets from middle school mathematics and Chinese classes, classroom dialogues were manually coded by experts and then analysed with a customised GPT-4 model. The study compares manual annotations with GPT-4 outputs to evaluate efficacy. Metrics include time efficiency, inter-coder agreement, and reliability between human coders and GPT-4. Results show significant time savings and high coding consistency between the model and human coders, with minor discrepancies. These findings highlight the strong potential of LLMs in teaching evaluation and facilitation.</p>\",\"PeriodicalId\":48503,\"journal\":{\"name\":\"npj Science of Learning\",\"volume\":\"9 1\",\"pages\":\"60\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2024-10-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11447259/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"npj Science of Learning\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://doi.org/10.1038/s41539-024-00273-3\",\"RegionNum\":1,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"EDUCATION & EDUCATIONAL RESEARCH\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"npj Science of Learning","FirstCategoryId":"102","ListUrlMain":"https://doi.org/10.1038/s41539-024-00273-3","RegionNum":1,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"EDUCATION & EDUCATIONAL RESEARCH","Score":null,"Total":0}
Evaluating large language models in analysing classroom dialogue.
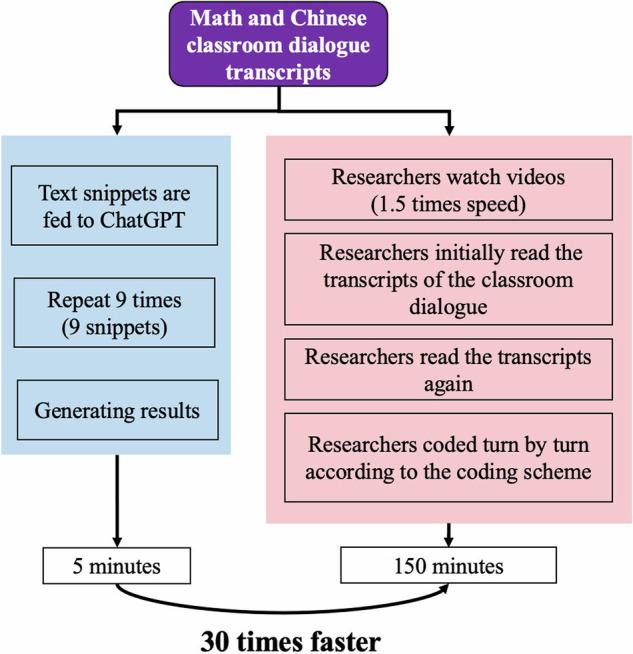
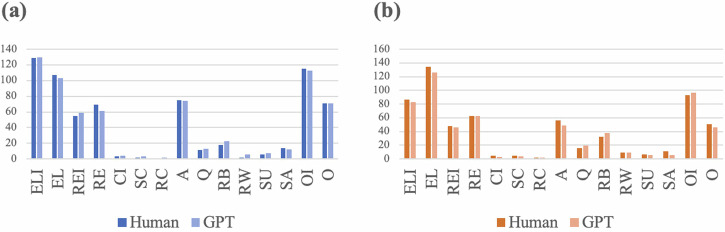
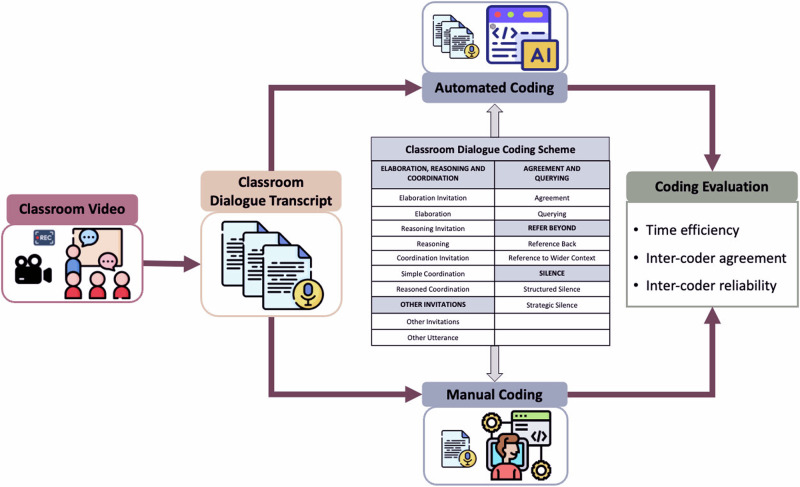
This study explores the use of Large Language Models (LLMs), specifically GPT-4, in analysing classroom dialogue-a key task for teaching diagnosis and quality improvement. Traditional qualitative methods are both knowledge- and labour-intensive. This research investigates the potential of LLMs to streamline and enhance this process. Using datasets from middle school mathematics and Chinese classes, classroom dialogues were manually coded by experts and then analysed with a customised GPT-4 model. The study compares manual annotations with GPT-4 outputs to evaluate efficacy. Metrics include time efficiency, inter-coder agreement, and reliability between human coders and GPT-4. Results show significant time savings and high coding consistency between the model and human coders, with minor discrepancies. These findings highlight the strong potential of LLMs in teaching evaluation and facilitation.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
