Yu Yin , Hyunjae Kim , Xiao Xiao , Chih Hsuan Wei , Jaewoo Kang , Zhiyong Lu , Hua Xu , Meng Fang , Qingyu Chen
{"title":"利用通用领域资源增强生物医学命名实体识别。","authors":"Yu Yin , Hyunjae Kim , Xiao Xiao , Chih Hsuan Wei , Jaewoo Kang , Zhiyong Lu , Hua Xu , Meng Fang , Qingyu Chen","doi":"10.1016/j.jbi.2024.104731","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective</h3><div>Training a neural network-based biomedical named entity recognition (BioNER) model usually requires extensive and costly human annotations. While several studies have employed multi-task learning with multiple BioNER datasets to reduce human effort, this approach does not consistently yield performance improvements and may introduce label ambiguity in different biomedical corpora. We aim to tackle those challenges through transfer learning from easily accessible resources with fewer concept overlaps with biomedical datasets.</div></div><div><h3>Methods</h3><div>We proposed GERBERA, a simple-yet-effective method that utilized general-domain NER datasets for training. We performed multi-task learning to train a pre-trained biomedical language model with both the target BioNER dataset and the general-domain dataset. Subsequently, we fine-tuned the models specifically for the BioNER dataset.</div></div><div><h3>Results</h3><div>We systematically evaluated GERBERA on five datasets of eight entity types, collectively consisting of 81,410 instances. Despite using fewer biomedical resources, our models demonstrated superior performance compared to baseline models trained with additional BioNER datasets. Specifically, our models consistently outperformed the baseline models in six out of eight entity types, achieving an average improvement of 0.9% over the best baseline performance across eight entities. Our method was especially effective in amplifying performance on BioNER datasets characterized by limited data, with a 4.7% improvement in F1 scores on the JNLPBA-RNA dataset.</div></div><div><h3>Conclusion</h3><div>This study introduces a new training method that leverages cost-effective general-domain NER datasets to augment BioNER models. This approach significantly improves BioNER model performance, making it a valuable asset for scenarios with scarce or costly biomedical datasets. We make data, codes, and models publicly available via <span><span>https://github.com/qingyu-qc/bioner_gerbera</span><svg><path></path></svg></span>.</div></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"159 ","pages":"Article 104731"},"PeriodicalIF":4.5000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Augmenting biomedical named entity recognition with general-domain resources\",\"authors\":\"Yu Yin , Hyunjae Kim , Xiao Xiao , Chih Hsuan Wei , Jaewoo Kang , Zhiyong Lu , Hua Xu , Meng Fang , Qingyu Chen\",\"doi\":\"10.1016/j.jbi.2024.104731\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objective</h3><div>Training a neural network-based biomedical named entity recognition (BioNER) model usually requires extensive and costly human annotations. While several studies have employed multi-task learning with multiple BioNER datasets to reduce human effort, this approach does not consistently yield performance improvements and may introduce label ambiguity in different biomedical corpora. We aim to tackle those challenges through transfer learning from easily accessible resources with fewer concept overlaps with biomedical datasets.</div></div><div><h3>Methods</h3><div>We proposed GERBERA, a simple-yet-effective method that utilized general-domain NER datasets for training. We performed multi-task learning to train a pre-trained biomedical language model with both the target BioNER dataset and the general-domain dataset. Subsequently, we fine-tuned the models specifically for the BioNER dataset.</div></div><div><h3>Results</h3><div>We systematically evaluated GERBERA on five datasets of eight entity types, collectively consisting of 81,410 instances. Despite using fewer biomedical resources, our models demonstrated superior performance compared to baseline models trained with additional BioNER datasets. Specifically, our models consistently outperformed the baseline models in six out of eight entity types, achieving an average improvement of 0.9% over the best baseline performance across eight entities. Our method was especially effective in amplifying performance on BioNER datasets characterized by limited data, with a 4.7% improvement in F1 scores on the JNLPBA-RNA dataset.</div></div><div><h3>Conclusion</h3><div>This study introduces a new training method that leverages cost-effective general-domain NER datasets to augment BioNER models. This approach significantly improves BioNER model performance, making it a valuable asset for scenarios with scarce or costly biomedical datasets. We make data, codes, and models publicly available via <span><span>https://github.com/qingyu-qc/bioner_gerbera</span><svg><path></path></svg></span>.</div></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"159 \",\"pages\":\"Article 104731\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2024-11-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424001497\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/4 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424001497","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/4 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Augmenting biomedical named entity recognition with general-domain resources
Objective
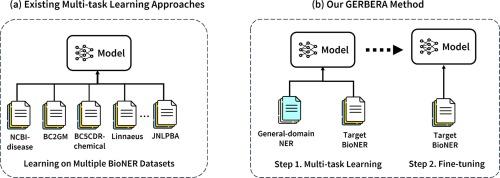
Training a neural network-based biomedical named entity recognition (BioNER) model usually requires extensive and costly human annotations. While several studies have employed multi-task learning with multiple BioNER datasets to reduce human effort, this approach does not consistently yield performance improvements and may introduce label ambiguity in different biomedical corpora. We aim to tackle those challenges through transfer learning from easily accessible resources with fewer concept overlaps with biomedical datasets.
Methods
We proposed GERBERA, a simple-yet-effective method that utilized general-domain NER datasets for training. We performed multi-task learning to train a pre-trained biomedical language model with both the target BioNER dataset and the general-domain dataset. Subsequently, we fine-tuned the models specifically for the BioNER dataset.
Results
We systematically evaluated GERBERA on five datasets of eight entity types, collectively consisting of 81,410 instances. Despite using fewer biomedical resources, our models demonstrated superior performance compared to baseline models trained with additional BioNER datasets. Specifically, our models consistently outperformed the baseline models in six out of eight entity types, achieving an average improvement of 0.9% over the best baseline performance across eight entities. Our method was especially effective in amplifying performance on BioNER datasets characterized by limited data, with a 4.7% improvement in F1 scores on the JNLPBA-RNA dataset.
Conclusion
This study introduces a new training method that leverages cost-effective general-domain NER datasets to augment BioNER models. This approach significantly improves BioNER model performance, making it a valuable asset for scenarios with scarce or costly biomedical datasets. We make data, codes, and models publicly available via https://github.com/qingyu-qc/bioner_gerbera.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
