Dong Hyun Choi, Min Hyuk Lim, Ki Jeong Hong, Young Gyun Kim, Jeong Ho Park, Kyoung Jun Song, Sang Do Shin, Sungwan Kim
{"title":"利用强化学习在院外心脏骤停的现场复苏时间内做出个性化决策","authors":"Dong Hyun Choi, Min Hyuk Lim, Ki Jeong Hong, Young Gyun Kim, Jeong Ho Park, Kyoung Jun Song, Sang Do Shin, Sungwan Kim","doi":"10.1038/s41746-024-01278-3","DOIUrl":null,"url":null,"abstract":"On-scene resuscitation time is associated with out-of-hospital cardiac arrest (OHCA) outcomes. We developed and validated reinforcement learning models for individualized on-scene resuscitation times, leveraging nationwide Korean data. Adult OHCA patients with a medical cause of arrest were included (N = 73,905). The optimal policy was derived from conservative Q-learning to maximize survival. The on-scene return of spontaneous circulation hazard rates estimated from the Random Survival Forest were used as intermediate rewards to handle sparse rewards, while patients’ historical survival was reflected in the terminal rewards. The optimal policy increased the survival to hospital discharge rate from 9.6% to 12.5% (95% CI: 12.2–12.8) and the good neurological recovery rate from 5.4% to 7.5% (95% CI: 7.3–7.7). The recommended maximum on-scene resuscitation times for patients demonstrated a bimodal distribution, varying with patient, emergency medical services, and OHCA characteristics. Our survival analysis-based approach generates explainable rewards, reducing subjectivity in reinforcement learning.","PeriodicalId":19349,"journal":{"name":"NPJ Digital Medicine","volume":" ","pages":"1-14"},"PeriodicalIF":15.1000,"publicationDate":"2024-10-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s41746-024-01278-3.pdf","citationCount":"0","resultStr":"{\"title\":\"Individualized decision making in on-scene resuscitation time for out-of-hospital cardiac arrest using reinforcement learning\",\"authors\":\"Dong Hyun Choi, Min Hyuk Lim, Ki Jeong Hong, Young Gyun Kim, Jeong Ho Park, Kyoung Jun Song, Sang Do Shin, Sungwan Kim\",\"doi\":\"10.1038/s41746-024-01278-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"On-scene resuscitation time is associated with out-of-hospital cardiac arrest (OHCA) outcomes. We developed and validated reinforcement learning models for individualized on-scene resuscitation times, leveraging nationwide Korean data. Adult OHCA patients with a medical cause of arrest were included (N = 73,905). The optimal policy was derived from conservative Q-learning to maximize survival. The on-scene return of spontaneous circulation hazard rates estimated from the Random Survival Forest were used as intermediate rewards to handle sparse rewards, while patients’ historical survival was reflected in the terminal rewards. The optimal policy increased the survival to hospital discharge rate from 9.6% to 12.5% (95% CI: 12.2–12.8) and the good neurological recovery rate from 5.4% to 7.5% (95% CI: 7.3–7.7). The recommended maximum on-scene resuscitation times for patients demonstrated a bimodal distribution, varying with patient, emergency medical services, and OHCA characteristics. Our survival analysis-based approach generates explainable rewards, reducing subjectivity in reinforcement learning.\",\"PeriodicalId\":19349,\"journal\":{\"name\":\"NPJ Digital Medicine\",\"volume\":\" \",\"pages\":\"1-14\"},\"PeriodicalIF\":15.1000,\"publicationDate\":\"2024-10-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.nature.com/articles/s41746-024-01278-3.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"NPJ Digital Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.nature.com/articles/s41746-024-01278-3\",\"RegionNum\":1,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"NPJ Digital Medicine","FirstCategoryId":"3","ListUrlMain":"https://www.nature.com/articles/s41746-024-01278-3","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Individualized decision making in on-scene resuscitation time for out-of-hospital cardiac arrest using reinforcement learning
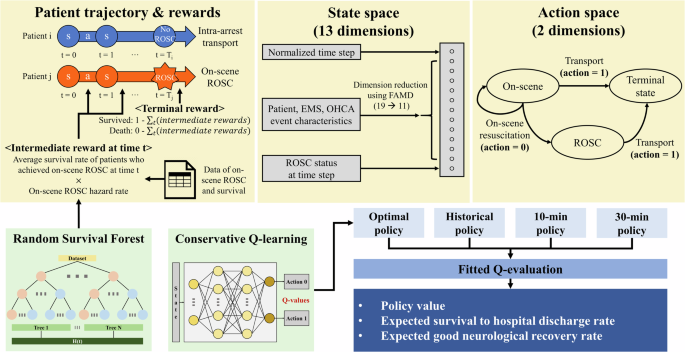
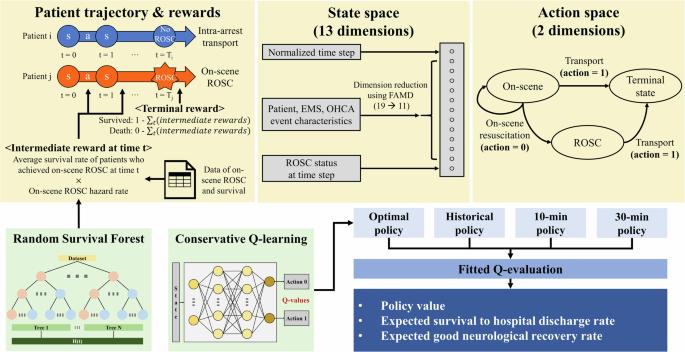
On-scene resuscitation time is associated with out-of-hospital cardiac arrest (OHCA) outcomes. We developed and validated reinforcement learning models for individualized on-scene resuscitation times, leveraging nationwide Korean data. Adult OHCA patients with a medical cause of arrest were included (N = 73,905). The optimal policy was derived from conservative Q-learning to maximize survival. The on-scene return of spontaneous circulation hazard rates estimated from the Random Survival Forest were used as intermediate rewards to handle sparse rewards, while patients’ historical survival was reflected in the terminal rewards. The optimal policy increased the survival to hospital discharge rate from 9.6% to 12.5% (95% CI: 12.2–12.8) and the good neurological recovery rate from 5.4% to 7.5% (95% CI: 7.3–7.7). The recommended maximum on-scene resuscitation times for patients demonstrated a bimodal distribution, varying with patient, emergency medical services, and OHCA characteristics. Our survival analysis-based approach generates explainable rewards, reducing subjectivity in reinforcement learning.
期刊介绍:
npj Digital Medicine is an online open-access journal that focuses on publishing peer-reviewed research in the field of digital medicine. The journal covers various aspects of digital medicine, including the application and implementation of digital and mobile technologies in clinical settings, virtual healthcare, and the use of artificial intelligence and informatics.
The primary goal of the journal is to support innovation and the advancement of healthcare through the integration of new digital and mobile technologies. When determining if a manuscript is suitable for publication, the journal considers four important criteria: novelty, clinical relevance, scientific rigor, and digital innovation.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
