Maciej Rybinski , Wojciech Kusa , Sarvnaz Karimi , Allan Hanbury
{"title":"利用大型语言模型学习将患者与临床试验相匹配。","authors":"Maciej Rybinski , Wojciech Kusa , Sarvnaz Karimi , Allan Hanbury","doi":"10.1016/j.jbi.2024.104734","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective:</h3><div>This study investigates the use of Large Language Models (LLMs) for matching patients to clinical trials (CTs) within an information retrieval pipeline. Our objective is to enhance the process of patient-trial matching by leveraging the semantic processing capabilities of LLMs, thereby improving the effectiveness of patient recruitment for clinical trials.</div></div><div><h3>Methods:</h3><div>We employed a multi-stage retrieval pipeline integrating various methodologies, including BM25 and Transformer-based rankers, along with LLM-based methods. Our primary datasets were the TREC Clinical Trials 2021–23 track collections. We compared LLM-based approaches, focusing on methods that leverage LLMs in query formulation, filtering, relevance ranking, and re-ranking of CTs.</div></div><div><h3>Results:</h3><div>Our results indicate that LLM-based systems, particularly those involving re-ranking with a fine-tuned LLM, outperform traditional methods in terms of nDCG and Precision measures. The study demonstrates that fine-tuning LLMs enhances their ability to find eligible trials. Moreover, our LLM-based approach is competitive with state-of-the-art systems in the TREC challenges.</div><div>The study shows the effectiveness of LLMs in CT matching, highlighting their potential in handling complex semantic analysis and improving patient-trial matching. However, the use of LLMs increases the computational cost and reduces efficiency. We provide a detailed analysis of effectiveness-efficiency trade-offs.</div></div><div><h3>Conclusion:</h3><div>This research demonstrates the promising role of LLMs in enhancing the patient-to-clinical trial matching process, offering a significant advancement in the automation of patient recruitment. Future work should explore optimising the balance between computational cost and retrieval effectiveness in practical applications.</div></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"159 ","pages":"Article 104734"},"PeriodicalIF":4.5000,"publicationDate":"2024-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Learning to match patients to clinical trials using large language models\",\"authors\":\"Maciej Rybinski , Wojciech Kusa , Sarvnaz Karimi , Allan Hanbury\",\"doi\":\"10.1016/j.jbi.2024.104734\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objective:</h3><div>This study investigates the use of Large Language Models (LLMs) for matching patients to clinical trials (CTs) within an information retrieval pipeline. Our objective is to enhance the process of patient-trial matching by leveraging the semantic processing capabilities of LLMs, thereby improving the effectiveness of patient recruitment for clinical trials.</div></div><div><h3>Methods:</h3><div>We employed a multi-stage retrieval pipeline integrating various methodologies, including BM25 and Transformer-based rankers, along with LLM-based methods. Our primary datasets were the TREC Clinical Trials 2021–23 track collections. We compared LLM-based approaches, focusing on methods that leverage LLMs in query formulation, filtering, relevance ranking, and re-ranking of CTs.</div></div><div><h3>Results:</h3><div>Our results indicate that LLM-based systems, particularly those involving re-ranking with a fine-tuned LLM, outperform traditional methods in terms of nDCG and Precision measures. The study demonstrates that fine-tuning LLMs enhances their ability to find eligible trials. Moreover, our LLM-based approach is competitive with state-of-the-art systems in the TREC challenges.</div><div>The study shows the effectiveness of LLMs in CT matching, highlighting their potential in handling complex semantic analysis and improving patient-trial matching. However, the use of LLMs increases the computational cost and reduces efficiency. We provide a detailed analysis of effectiveness-efficiency trade-offs.</div></div><div><h3>Conclusion:</h3><div>This research demonstrates the promising role of LLMs in enhancing the patient-to-clinical trial matching process, offering a significant advancement in the automation of patient recruitment. Future work should explore optimising the balance between computational cost and retrieval effectiveness in practical applications.</div></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"159 \",\"pages\":\"Article 104734\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2024-11-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424001527\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/9 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424001527","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/9 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Learning to match patients to clinical trials using large language models
Objective:
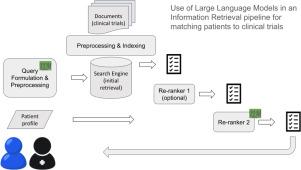
This study investigates the use of Large Language Models (LLMs) for matching patients to clinical trials (CTs) within an information retrieval pipeline. Our objective is to enhance the process of patient-trial matching by leveraging the semantic processing capabilities of LLMs, thereby improving the effectiveness of patient recruitment for clinical trials.
Methods:
We employed a multi-stage retrieval pipeline integrating various methodologies, including BM25 and Transformer-based rankers, along with LLM-based methods. Our primary datasets were the TREC Clinical Trials 2021–23 track collections. We compared LLM-based approaches, focusing on methods that leverage LLMs in query formulation, filtering, relevance ranking, and re-ranking of CTs.
Results:
Our results indicate that LLM-based systems, particularly those involving re-ranking with a fine-tuned LLM, outperform traditional methods in terms of nDCG and Precision measures. The study demonstrates that fine-tuning LLMs enhances their ability to find eligible trials. Moreover, our LLM-based approach is competitive with state-of-the-art systems in the TREC challenges.
The study shows the effectiveness of LLMs in CT matching, highlighting their potential in handling complex semantic analysis and improving patient-trial matching. However, the use of LLMs increases the computational cost and reduces efficiency. We provide a detailed analysis of effectiveness-efficiency trade-offs.
Conclusion:
This research demonstrates the promising role of LLMs in enhancing the patient-to-clinical trial matching process, offering a significant advancement in the automation of patient recruitment. Future work should explore optimising the balance between computational cost and retrieval effectiveness in practical applications.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
