Niher Tabassum Snigdha, Rumesa Batul, Mohmed Isaqali Karobari, Abdul Habeeb Adil, Ali Azhar Dawasaz, Mohammad Shahul Hameed, Vini Mehta, Tahir Yusuf Noorani
{"title":"评估 ChatGPT 3.5 和 ChatGPT 4 在牙科手术和根管治疗中的性能:一项探索性研究","authors":"Niher Tabassum Snigdha, Rumesa Batul, Mohmed Isaqali Karobari, Abdul Habeeb Adil, Ali Azhar Dawasaz, Mohammad Shahul Hameed, Vini Mehta, Tahir Yusuf Noorani","doi":"10.1155/2024/1119816","DOIUrl":null,"url":null,"abstract":"<p><b>Background</b>: Artificial intelligence is an innovative technology that mimics human cognitive capacities and has gathered the world’s attention through its vast applications in various fields.</p><p><b>Aim:</b> This study is aimed at assessing the effects of ChatGPT 3.5 and ChatGPT 4 on the validity, reliability, and authenticity of standard assessment techniques used in undergraduate dentistry education.</p><p><b>Methodology:</b> Twenty questions, each requiring a single best answer, were selected from two domains: 10 from operative dentistry and 10 from endodontics. These questions were divided equally, with half presented with multiple choice options and the other half without. Two investigators used different ChatGPT accounts to generate answers, repeating each question three times. The answers were scored between 0% and 100% based on their accuracy. The mean score of the three attempts was recorded, and statistical analysis was conducted.</p><p><b>Results</b>: No statistically significant differences were found between ChatGPT 3.5 and ChatGPT 4 in the accuracy of their responses. Additionally, the analysis showed high consistency between the two reviewers, with no significant difference in their assessments.</p><p><b>Conclusion:</b> This study evaluated the performance of ChatGPT 3.5 and ChatGPT 4 in answering questions related to endodontics and operative dentistry. The results showed no statistically significant differences between the two versions, indicating comparable response accuracy. The consistency between reviewers further validated the reliability of the assessment process.</p>","PeriodicalId":36408,"journal":{"name":"Human Behavior and Emerging Technologies","volume":"2024 1","pages":""},"PeriodicalIF":4.9000,"publicationDate":"2024-10-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1155/2024/1119816","citationCount":"0","resultStr":"{\"title\":\"Assessing the Performance of ChatGPT 3.5 and ChatGPT 4 in Operative Dentistry and Endodontics: An Exploratory Study\",\"authors\":\"Niher Tabassum Snigdha, Rumesa Batul, Mohmed Isaqali Karobari, Abdul Habeeb Adil, Ali Azhar Dawasaz, Mohammad Shahul Hameed, Vini Mehta, Tahir Yusuf Noorani\",\"doi\":\"10.1155/2024/1119816\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><b>Background</b>: Artificial intelligence is an innovative technology that mimics human cognitive capacities and has gathered the world’s attention through its vast applications in various fields.</p><p><b>Aim:</b> This study is aimed at assessing the effects of ChatGPT 3.5 and ChatGPT 4 on the validity, reliability, and authenticity of standard assessment techniques used in undergraduate dentistry education.</p><p><b>Methodology:</b> Twenty questions, each requiring a single best answer, were selected from two domains: 10 from operative dentistry and 10 from endodontics. These questions were divided equally, with half presented with multiple choice options and the other half without. Two investigators used different ChatGPT accounts to generate answers, repeating each question three times. The answers were scored between 0% and 100% based on their accuracy. The mean score of the three attempts was recorded, and statistical analysis was conducted.</p><p><b>Results</b>: No statistically significant differences were found between ChatGPT 3.5 and ChatGPT 4 in the accuracy of their responses. Additionally, the analysis showed high consistency between the two reviewers, with no significant difference in their assessments.</p><p><b>Conclusion:</b> This study evaluated the performance of ChatGPT 3.5 and ChatGPT 4 in answering questions related to endodontics and operative dentistry. The results showed no statistically significant differences between the two versions, indicating comparable response accuracy. The consistency between reviewers further validated the reliability of the assessment process.</p>\",\"PeriodicalId\":36408,\"journal\":{\"name\":\"Human Behavior and Emerging Technologies\",\"volume\":\"2024 1\",\"pages\":\"\"},\"PeriodicalIF\":4.9000,\"publicationDate\":\"2024-10-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1155/2024/1119816\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Human Behavior and Emerging Technologies\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1155/2024/1119816\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"PSYCHOLOGY, MULTIDISCIPLINARY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Human Behavior and Emerging Technologies","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1155/2024/1119816","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PSYCHOLOGY, MULTIDISCIPLINARY","Score":null,"Total":0}
Assessing the Performance of ChatGPT 3.5 and ChatGPT 4 in Operative Dentistry and Endodontics: An Exploratory Study
Background: Artificial intelligence is an innovative technology that mimics human cognitive capacities and has gathered the world’s attention through its vast applications in various fields.
Aim: This study is aimed at assessing the effects of ChatGPT 3.5 and ChatGPT 4 on the validity, reliability, and authenticity of standard assessment techniques used in undergraduate dentistry education.
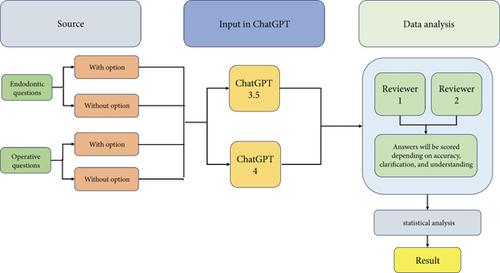
Methodology: Twenty questions, each requiring a single best answer, were selected from two domains: 10 from operative dentistry and 10 from endodontics. These questions were divided equally, with half presented with multiple choice options and the other half without. Two investigators used different ChatGPT accounts to generate answers, repeating each question three times. The answers were scored between 0% and 100% based on their accuracy. The mean score of the three attempts was recorded, and statistical analysis was conducted.
Results: No statistically significant differences were found between ChatGPT 3.5 and ChatGPT 4 in the accuracy of their responses. Additionally, the analysis showed high consistency between the two reviewers, with no significant difference in their assessments.
Conclusion: This study evaluated the performance of ChatGPT 3.5 and ChatGPT 4 in answering questions related to endodontics and operative dentistry. The results showed no statistically significant differences between the two versions, indicating comparable response accuracy. The consistency between reviewers further validated the reliability of the assessment process.
期刊介绍:
Human Behavior and Emerging Technologies is an interdisciplinary journal dedicated to publishing high-impact research that enhances understanding of the complex interactions between diverse human behavior and emerging digital technologies.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
