Song Wang, Yiliang Zhou, Ziqiang Han, Cui Tao, Yunyu Xiao, Ying Ding, Joydeep Ghosh, Yifan Peng
{"title":"用自然语言处理方法检测死亡调查笔记中归因于自杀情况的不一致之处","authors":"Song Wang, Yiliang Zhou, Ziqiang Han, Cui Tao, Yunyu Xiao, Ying Ding, Joydeep Ghosh, Yifan Peng","doi":"10.1038/s43856-024-00631-7","DOIUrl":null,"url":null,"abstract":"Data accuracy is essential for scientific research and policy development. The National Violent Death Reporting System (NVDRS) data is widely used for discovering the patterns and causing factors of death. Recent studies suggested the annotation inconsistencies within the NVDRS and the potential impact on erroneous suicide-circumstance attributions. We present an empirical Natural Language Processing (NLP) approach to detect annotation inconsistencies and adopt a cross-validation-like paradigm to identify possible label errors. We analyzed 267,804 suicide death incidents between 2003 and 2020 from the NVDRS. We measured annotation inconsistency by the degree of changes in the F-1 score. Our results show that incorporating the target state’s data into training the suicide-circumstance classifier brings an increase of 5.4% to the F-1 score on the target state’s test set and a decrease of 1.1% on other states’ test set. To conclude, we present an NLP framework to detect the annotation inconsistencies, show the effectiveness of identifying and rectifying possible label errors, and eventually propose an improvement solution to improve the coding consistency of human annotators. Data accuracy is essential for scientific research and policy development. The National Violent Death Reporting System (NVDRS) contains the recording of individual suicide incidents taking place in the United States, and the contributing suicide circumstances. We used a computational method to check the accuracy of NVDRS records. Our method identified and rectified possible errors in labeling within the database. This method could be used to improve the label accuracy in the NVDRS database, enabling more accurate recording and study of suicide circumstances. Improved data recording of suicide circumstances could potentially be used to develop improved approaches to prevent suicide in the future. Wang et al. use a Natural Language Processing approach to detect suicide-circumstance annotation inconsistencies in death investigation notes. They identify possible label errors, show the effectiveness of identifying and rectifying possible label errors, and propose a coding consistency improvement solution.","PeriodicalId":72646,"journal":{"name":"Communications medicine","volume":" ","pages":"1-13"},"PeriodicalIF":5.4000,"publicationDate":"2024-10-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s43856-024-00631-7.pdf","citationCount":"0","resultStr":"{\"title\":\"A natural language processing approach to detect inconsistencies in death investigation notes attributing suicide circumstances\",\"authors\":\"Song Wang, Yiliang Zhou, Ziqiang Han, Cui Tao, Yunyu Xiao, Ying Ding, Joydeep Ghosh, Yifan Peng\",\"doi\":\"10.1038/s43856-024-00631-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Data accuracy is essential for scientific research and policy development. The National Violent Death Reporting System (NVDRS) data is widely used for discovering the patterns and causing factors of death. Recent studies suggested the annotation inconsistencies within the NVDRS and the potential impact on erroneous suicide-circumstance attributions. We present an empirical Natural Language Processing (NLP) approach to detect annotation inconsistencies and adopt a cross-validation-like paradigm to identify possible label errors. We analyzed 267,804 suicide death incidents between 2003 and 2020 from the NVDRS. We measured annotation inconsistency by the degree of changes in the F-1 score. Our results show that incorporating the target state’s data into training the suicide-circumstance classifier brings an increase of 5.4% to the F-1 score on the target state’s test set and a decrease of 1.1% on other states’ test set. To conclude, we present an NLP framework to detect the annotation inconsistencies, show the effectiveness of identifying and rectifying possible label errors, and eventually propose an improvement solution to improve the coding consistency of human annotators. Data accuracy is essential for scientific research and policy development. The National Violent Death Reporting System (NVDRS) contains the recording of individual suicide incidents taking place in the United States, and the contributing suicide circumstances. We used a computational method to check the accuracy of NVDRS records. Our method identified and rectified possible errors in labeling within the database. This method could be used to improve the label accuracy in the NVDRS database, enabling more accurate recording and study of suicide circumstances. Improved data recording of suicide circumstances could potentially be used to develop improved approaches to prevent suicide in the future. Wang et al. use a Natural Language Processing approach to detect suicide-circumstance annotation inconsistencies in death investigation notes. They identify possible label errors, show the effectiveness of identifying and rectifying possible label errors, and propose a coding consistency improvement solution.\",\"PeriodicalId\":72646,\"journal\":{\"name\":\"Communications medicine\",\"volume\":\" \",\"pages\":\"1-13\"},\"PeriodicalIF\":5.4000,\"publicationDate\":\"2024-10-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.nature.com/articles/s43856-024-00631-7.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Communications medicine\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.nature.com/articles/s43856-024-00631-7\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MEDICINE, RESEARCH & EXPERIMENTAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Communications medicine","FirstCategoryId":"1085","ListUrlMain":"https://www.nature.com/articles/s43856-024-00631-7","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MEDICINE, RESEARCH & EXPERIMENTAL","Score":null,"Total":0}
A natural language processing approach to detect inconsistencies in death investigation notes attributing suicide circumstances
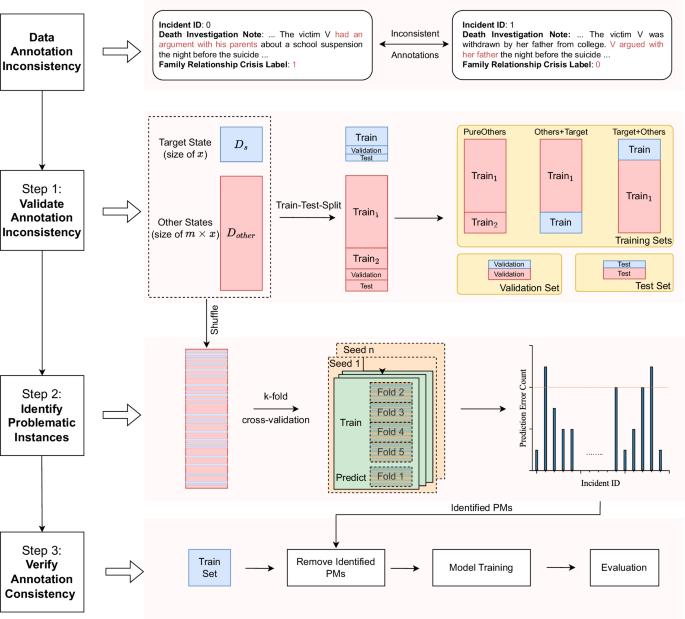
Data accuracy is essential for scientific research and policy development. The National Violent Death Reporting System (NVDRS) data is widely used for discovering the patterns and causing factors of death. Recent studies suggested the annotation inconsistencies within the NVDRS and the potential impact on erroneous suicide-circumstance attributions. We present an empirical Natural Language Processing (NLP) approach to detect annotation inconsistencies and adopt a cross-validation-like paradigm to identify possible label errors. We analyzed 267,804 suicide death incidents between 2003 and 2020 from the NVDRS. We measured annotation inconsistency by the degree of changes in the F-1 score. Our results show that incorporating the target state’s data into training the suicide-circumstance classifier brings an increase of 5.4% to the F-1 score on the target state’s test set and a decrease of 1.1% on other states’ test set. To conclude, we present an NLP framework to detect the annotation inconsistencies, show the effectiveness of identifying and rectifying possible label errors, and eventually propose an improvement solution to improve the coding consistency of human annotators. Data accuracy is essential for scientific research and policy development. The National Violent Death Reporting System (NVDRS) contains the recording of individual suicide incidents taking place in the United States, and the contributing suicide circumstances. We used a computational method to check the accuracy of NVDRS records. Our method identified and rectified possible errors in labeling within the database. This method could be used to improve the label accuracy in the NVDRS database, enabling more accurate recording and study of suicide circumstances. Improved data recording of suicide circumstances could potentially be used to develop improved approaches to prevent suicide in the future. Wang et al. use a Natural Language Processing approach to detect suicide-circumstance annotation inconsistencies in death investigation notes. They identify possible label errors, show the effectiveness of identifying and rectifying possible label errors, and propose a coding consistency improvement solution.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
