Cezary Turek, Márton Ölbei, Tamás Stirling, Gergely Fekete, Ervin Tasnádi, Leila Gul, Balázs Bohár, Balázs Papp, Wiktor Jurkowski, Eszter Ari
{"title":"mulea:使用多本体和经验错误发现率进行富集分析的 R 软件包。","authors":"Cezary Turek, Márton Ölbei, Tamás Stirling, Gergely Fekete, Ervin Tasnádi, Leila Gul, Balázs Bohár, Balázs Papp, Wiktor Jurkowski, Eszter Ari","doi":"10.1186/s12859-024-05948-7","DOIUrl":null,"url":null,"abstract":"<p><p>Traditional gene set enrichment analyses are typically limited to a few ontologies and do not account for the interdependence of gene sets or terms, resulting in overcorrected p-values. To address these challenges, we introduce mulea, an R package offering comprehensive overrepresentation and functional enrichment analysis. mulea employs a progressive empirical false discovery rate (eFDR) method, specifically designed for interconnected biological data, to accurately identify significant terms within diverse ontologies. mulea expands beyond traditional tools by incorporating a wide range of ontologies, encompassing Gene Ontology, pathways, regulatory elements, genomic locations, and protein domains. This flexibility enables researchers to tailor enrichment analysis to their specific questions, such as identifying enriched transcriptional regulators in gene expression data or overrepresented protein domains in protein sets. To facilitate seamless analysis, mulea provides gene sets (in standardised GMT format) for 27 model organisms, covering 22 ontology types from 16 databases and various identifiers resulting in almost 900 files. Additionally, the muleaData ExperimentData Bioconductor package simplifies access to these pre-defined ontologies. Finally, mulea's architecture allows for easy integration of user-defined ontologies, or GMT files from external sources (e.g., MSigDB or Enrichr), expanding its applicability across diverse research areas. mulea is distributed as a CRAN R package downloadable from https://cran.r-project.org/web/packages/mulea/ and https://github.com/ELTEbioinformatics/mulea . It offers researchers a powerful and flexible toolkit for functional enrichment analysis, addressing limitations of traditional tools with its progressive eFDR and by supporting a variety of ontologies. Overall, mulea fosters the exploration of diverse biological questions across various model organisms.</p>","PeriodicalId":8958,"journal":{"name":"BMC Bioinformatics","volume":"25 1","pages":"334"},"PeriodicalIF":3.3000,"publicationDate":"2024-10-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11490090/pdf/","citationCount":"0","resultStr":"{\"title\":\"mulea: An R package for enrichment analysis using multiple ontologies and empirical false discovery rate.\",\"authors\":\"Cezary Turek, Márton Ölbei, Tamás Stirling, Gergely Fekete, Ervin Tasnádi, Leila Gul, Balázs Bohár, Balázs Papp, Wiktor Jurkowski, Eszter Ari\",\"doi\":\"10.1186/s12859-024-05948-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Traditional gene set enrichment analyses are typically limited to a few ontologies and do not account for the interdependence of gene sets or terms, resulting in overcorrected p-values. To address these challenges, we introduce mulea, an R package offering comprehensive overrepresentation and functional enrichment analysis. mulea employs a progressive empirical false discovery rate (eFDR) method, specifically designed for interconnected biological data, to accurately identify significant terms within diverse ontologies. mulea expands beyond traditional tools by incorporating a wide range of ontologies, encompassing Gene Ontology, pathways, regulatory elements, genomic locations, and protein domains. This flexibility enables researchers to tailor enrichment analysis to their specific questions, such as identifying enriched transcriptional regulators in gene expression data or overrepresented protein domains in protein sets. To facilitate seamless analysis, mulea provides gene sets (in standardised GMT format) for 27 model organisms, covering 22 ontology types from 16 databases and various identifiers resulting in almost 900 files. Additionally, the muleaData ExperimentData Bioconductor package simplifies access to these pre-defined ontologies. Finally, mulea's architecture allows for easy integration of user-defined ontologies, or GMT files from external sources (e.g., MSigDB or Enrichr), expanding its applicability across diverse research areas. mulea is distributed as a CRAN R package downloadable from https://cran.r-project.org/web/packages/mulea/ and https://github.com/ELTEbioinformatics/mulea . It offers researchers a powerful and flexible toolkit for functional enrichment analysis, addressing limitations of traditional tools with its progressive eFDR and by supporting a variety of ontologies. Overall, mulea fosters the exploration of diverse biological questions across various model organisms.</p>\",\"PeriodicalId\":8958,\"journal\":{\"name\":\"BMC Bioinformatics\",\"volume\":\"25 1\",\"pages\":\"334\"},\"PeriodicalIF\":3.3000,\"publicationDate\":\"2024-10-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11490090/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMC Bioinformatics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s12859-024-05948-7\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s12859-024-05948-7","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
mulea: An R package for enrichment analysis using multiple ontologies and empirical false discovery rate.
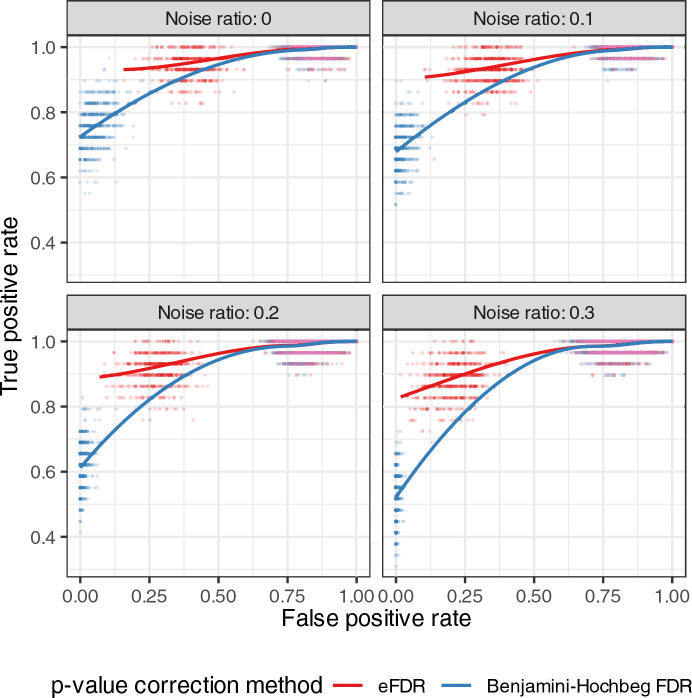
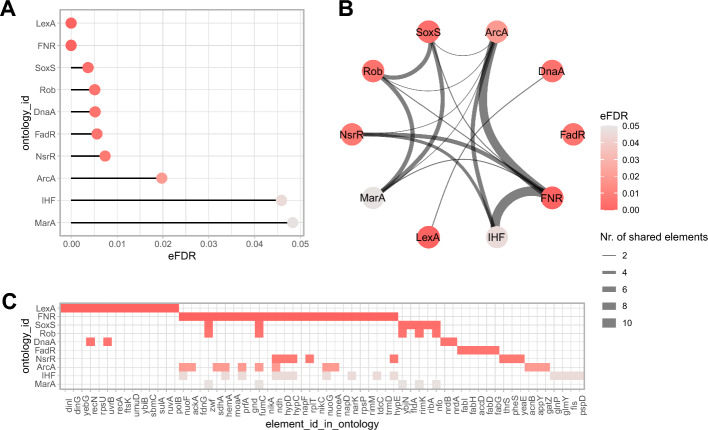
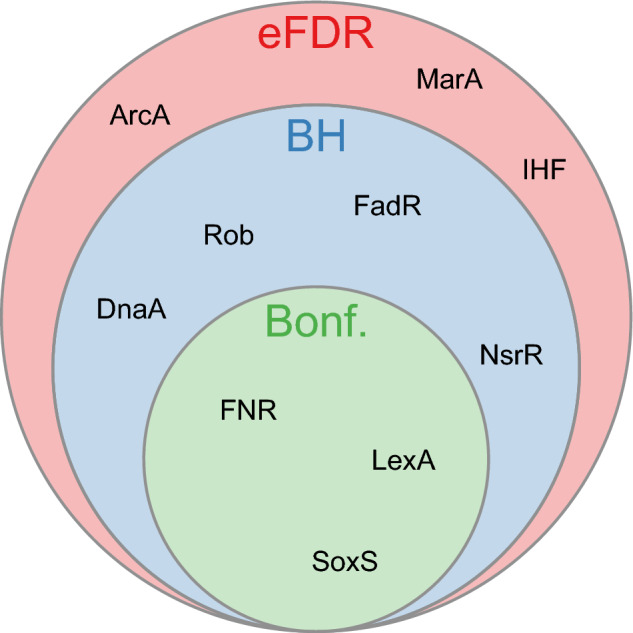
Traditional gene set enrichment analyses are typically limited to a few ontologies and do not account for the interdependence of gene sets or terms, resulting in overcorrected p-values. To address these challenges, we introduce mulea, an R package offering comprehensive overrepresentation and functional enrichment analysis. mulea employs a progressive empirical false discovery rate (eFDR) method, specifically designed for interconnected biological data, to accurately identify significant terms within diverse ontologies. mulea expands beyond traditional tools by incorporating a wide range of ontologies, encompassing Gene Ontology, pathways, regulatory elements, genomic locations, and protein domains. This flexibility enables researchers to tailor enrichment analysis to their specific questions, such as identifying enriched transcriptional regulators in gene expression data or overrepresented protein domains in protein sets. To facilitate seamless analysis, mulea provides gene sets (in standardised GMT format) for 27 model organisms, covering 22 ontology types from 16 databases and various identifiers resulting in almost 900 files. Additionally, the muleaData ExperimentData Bioconductor package simplifies access to these pre-defined ontologies. Finally, mulea's architecture allows for easy integration of user-defined ontologies, or GMT files from external sources (e.g., MSigDB or Enrichr), expanding its applicability across diverse research areas. mulea is distributed as a CRAN R package downloadable from https://cran.r-project.org/web/packages/mulea/ and https://github.com/ELTEbioinformatics/mulea . It offers researchers a powerful and flexible toolkit for functional enrichment analysis, addressing limitations of traditional tools with its progressive eFDR and by supporting a variety of ontologies. Overall, mulea fosters the exploration of diverse biological questions across various model organisms.
期刊介绍:
BMC Bioinformatics is an open access, peer-reviewed journal that considers articles on all aspects of the development, testing and novel application of computational and statistical methods for the modeling and analysis of all kinds of biological data, as well as other areas of computational biology.
BMC Bioinformatics is part of the BMC series which publishes subject-specific journals focused on the needs of individual research communities across all areas of biology and medicine. We offer an efficient, fair and friendly peer review service, and are committed to publishing all sound science, provided that there is some advance in knowledge presented by the work.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
