Eunbeen Jo, Hakje Yoo, Jong-Ho Kim, Young-Min Kim, Sanghoun Song, Hyung Joon Joo
{"title":"用于基于文本的门诊部推荐的微调变压器双向编码器表示法与 ChatGPT:比较研究。","authors":"Eunbeen Jo, Hakje Yoo, Jong-Ho Kim, Young-Min Kim, Sanghoun Song, Hyung Joon Joo","doi":"10.2196/47814","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Patients often struggle with determining which outpatient specialist to consult based on their symptoms. Natural language processing models in health care offer the potential to assist patients in making these decisions before visiting a hospital.</p><p><strong>Objective: </strong>This study aimed to evaluate the performance of ChatGPT in recommending medical specialties for medical questions.</p><p><strong>Methods: </strong>We used a dataset of 31,482 medical questions, each answered by doctors and labeled with the appropriate medical specialty from the health consultation board of NAVER (NAVER Corp), a major Korean portal. This dataset includes 27 distinct medical specialty labels. We compared the performance of the fine-tuned Korean Medical bidirectional encoder representations from transformers (KM-BERT) and ChatGPT models by analyzing their ability to accurately recommend medical specialties. We categorized responses from ChatGPT into those matching the 27 predefined specialties and those that did not. Both models were evaluated using performance metrics of accuracy, precision, recall, and F<sub>1</sub>-score.</p><p><strong>Results: </strong>ChatGPT demonstrated an answer avoidance rate of 6.2% but provided accurate medical specialty recommendations with explanations that elucidated the underlying pathophysiology of the patient's symptoms. It achieved an accuracy of 0.939, precision of 0.219, recall of 0.168, and an F<sub>1</sub>-score of 0.134. In contrast, the KM-BERT model, fine-tuned for the same task, outperformed ChatGPT with an accuracy of 0.977, precision of 0.570, recall of 0.652, and an F<sub>1</sub>-score of 0.587.</p><p><strong>Conclusions: </strong>Although ChatGPT did not surpass the fine-tuned KM-BERT model in recommending the correct medical specialties, it showcased notable advantages as a conversational artificial intelligence model. By providing detailed, contextually appropriate explanations, ChatGPT has the potential to significantly enhance patient comprehension of medical information, thereby improving the medical referral process.</p>","PeriodicalId":14841,"journal":{"name":"JMIR Formative Research","volume":"8 ","pages":"e47814"},"PeriodicalIF":2.0000,"publicationDate":"2024-10-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11530716/pdf/","citationCount":"0","resultStr":"{\"title\":\"Fine-Tuned Bidirectional Encoder Representations From Transformers Versus ChatGPT for Text-Based Outpatient Department Recommendation: Comparative Study.\",\"authors\":\"Eunbeen Jo, Hakje Yoo, Jong-Ho Kim, Young-Min Kim, Sanghoun Song, Hyung Joon Joo\",\"doi\":\"10.2196/47814\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Patients often struggle with determining which outpatient specialist to consult based on their symptoms. Natural language processing models in health care offer the potential to assist patients in making these decisions before visiting a hospital.</p><p><strong>Objective: </strong>This study aimed to evaluate the performance of ChatGPT in recommending medical specialties for medical questions.</p><p><strong>Methods: </strong>We used a dataset of 31,482 medical questions, each answered by doctors and labeled with the appropriate medical specialty from the health consultation board of NAVER (NAVER Corp), a major Korean portal. This dataset includes 27 distinct medical specialty labels. We compared the performance of the fine-tuned Korean Medical bidirectional encoder representations from transformers (KM-BERT) and ChatGPT models by analyzing their ability to accurately recommend medical specialties. We categorized responses from ChatGPT into those matching the 27 predefined specialties and those that did not. Both models were evaluated using performance metrics of accuracy, precision, recall, and F<sub>1</sub>-score.</p><p><strong>Results: </strong>ChatGPT demonstrated an answer avoidance rate of 6.2% but provided accurate medical specialty recommendations with explanations that elucidated the underlying pathophysiology of the patient's symptoms. It achieved an accuracy of 0.939, precision of 0.219, recall of 0.168, and an F<sub>1</sub>-score of 0.134. In contrast, the KM-BERT model, fine-tuned for the same task, outperformed ChatGPT with an accuracy of 0.977, precision of 0.570, recall of 0.652, and an F<sub>1</sub>-score of 0.587.</p><p><strong>Conclusions: </strong>Although ChatGPT did not surpass the fine-tuned KM-BERT model in recommending the correct medical specialties, it showcased notable advantages as a conversational artificial intelligence model. By providing detailed, contextually appropriate explanations, ChatGPT has the potential to significantly enhance patient comprehension of medical information, thereby improving the medical referral process.</p>\",\"PeriodicalId\":14841,\"journal\":{\"name\":\"JMIR Formative Research\",\"volume\":\"8 \",\"pages\":\"e47814\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2024-10-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11530716/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR Formative Research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/47814\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Formative Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/47814","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Fine-Tuned Bidirectional Encoder Representations From Transformers Versus ChatGPT for Text-Based Outpatient Department Recommendation: Comparative Study.
Background: Patients often struggle with determining which outpatient specialist to consult based on their symptoms. Natural language processing models in health care offer the potential to assist patients in making these decisions before visiting a hospital.
Objective: This study aimed to evaluate the performance of ChatGPT in recommending medical specialties for medical questions.
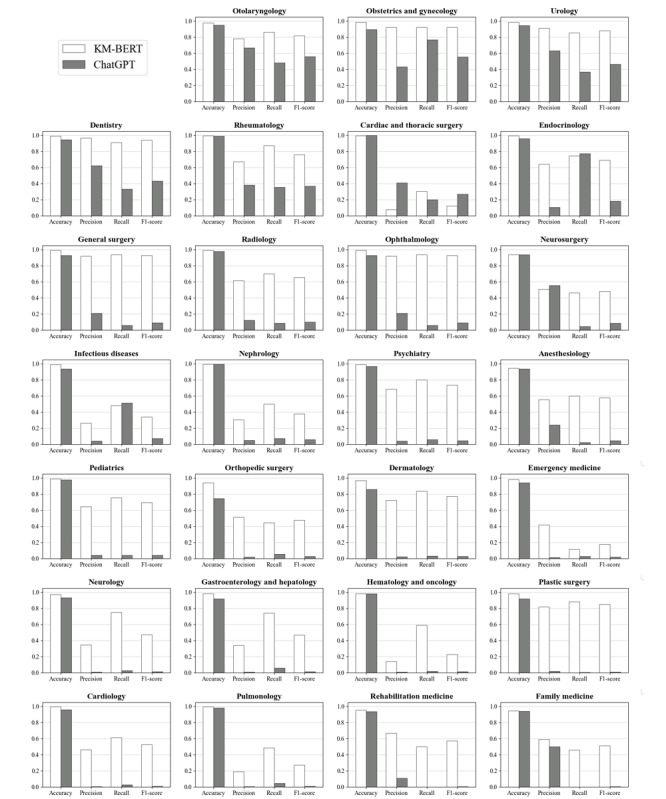
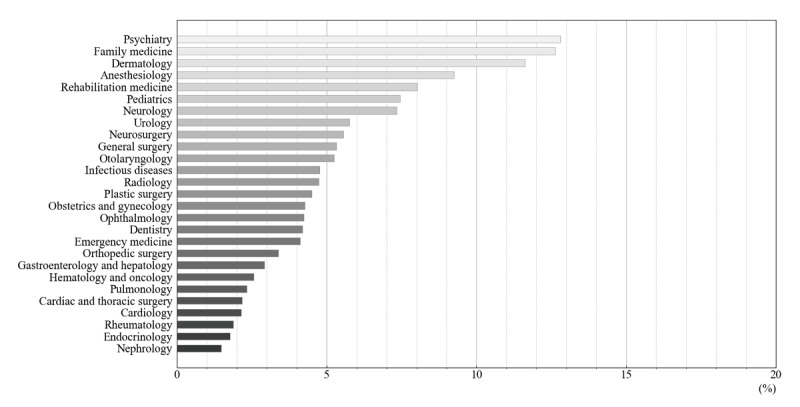
Methods: We used a dataset of 31,482 medical questions, each answered by doctors and labeled with the appropriate medical specialty from the health consultation board of NAVER (NAVER Corp), a major Korean portal. This dataset includes 27 distinct medical specialty labels. We compared the performance of the fine-tuned Korean Medical bidirectional encoder representations from transformers (KM-BERT) and ChatGPT models by analyzing their ability to accurately recommend medical specialties. We categorized responses from ChatGPT into those matching the 27 predefined specialties and those that did not. Both models were evaluated using performance metrics of accuracy, precision, recall, and F1-score.
Results: ChatGPT demonstrated an answer avoidance rate of 6.2% but provided accurate medical specialty recommendations with explanations that elucidated the underlying pathophysiology of the patient's symptoms. It achieved an accuracy of 0.939, precision of 0.219, recall of 0.168, and an F1-score of 0.134. In contrast, the KM-BERT model, fine-tuned for the same task, outperformed ChatGPT with an accuracy of 0.977, precision of 0.570, recall of 0.652, and an F1-score of 0.587.
Conclusions: Although ChatGPT did not surpass the fine-tuned KM-BERT model in recommending the correct medical specialties, it showcased notable advantages as a conversational artificial intelligence model. By providing detailed, contextually appropriate explanations, ChatGPT has the potential to significantly enhance patient comprehension of medical information, thereby improving the medical referral process.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
