Gloria Geine Paendong, Soualihou Ngnamsie Njimbouom, Candra Zonyfar, Jeong-Dong Kim
{"title":"ERL-ProLiGraph:用于结合亲和力预测的蛋白质配体图结构数据的增强表示学习。","authors":"Gloria Geine Paendong, Soualihou Ngnamsie Njimbouom, Candra Zonyfar, Jeong-Dong Kim","doi":"10.1002/minf.202400044","DOIUrl":null,"url":null,"abstract":"<p><p>Predicting Protein-Ligand Binding Affinity (PLBA) is pivotal in drug development, as accurate estimations of PLBA expedite the identification of promising drug candidates for specific targets, thereby accelerating the drug discovery process. Despite substantial advancements in PLBA prediction, developing an efficient and more accurate method remains non-trivial. Unlike previous computer-aid PLBA studies which primarily using ligand SMILES and protein sequences represented as strings, this research introduces a Deep Learning-based method, the Enhanced Representation Learning on Protein-Ligand Graph Structured data for Binding Affinity Prediction (ERL-ProLiGraph). The unique aspect of this method is the use of graph representations for both proteins and ligands, intending to learn structural information continued from both to enhance the accuracy of PLBA predictions. In these graphs, nodes represent atomic structures, while edges depict chemical bonds and spatial relationship. The proposed model, leveraging deep-learning algorithms, effectively learns to correlate these graphical representations with binding affinities. This graph-based representations approach enhances the model's ability to capture the complex molecular interactions critical in PLBA. This work represents a promising advancement in computational techniques for protein-ligand binding prediction, offering a potential path toward more efficient and accurate predictions in drug development. Comparative analysis indicates that the proposed ERL-ProLiGraph outperforms previous models, showcasing notable efficacy and providing a more suitable approach for accurate PLBA predictions.</p>","PeriodicalId":18853,"journal":{"name":"Molecular Informatics","volume":" ","pages":"e202400044"},"PeriodicalIF":3.1000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11639045/pdf/","citationCount":"0","resultStr":"{\"title\":\"ERL-ProLiGraph: Enhanced representation learning on protein-ligand graph structured data for binding affinity prediction.\",\"authors\":\"Gloria Geine Paendong, Soualihou Ngnamsie Njimbouom, Candra Zonyfar, Jeong-Dong Kim\",\"doi\":\"10.1002/minf.202400044\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Predicting Protein-Ligand Binding Affinity (PLBA) is pivotal in drug development, as accurate estimations of PLBA expedite the identification of promising drug candidates for specific targets, thereby accelerating the drug discovery process. Despite substantial advancements in PLBA prediction, developing an efficient and more accurate method remains non-trivial. Unlike previous computer-aid PLBA studies which primarily using ligand SMILES and protein sequences represented as strings, this research introduces a Deep Learning-based method, the Enhanced Representation Learning on Protein-Ligand Graph Structured data for Binding Affinity Prediction (ERL-ProLiGraph). The unique aspect of this method is the use of graph representations for both proteins and ligands, intending to learn structural information continued from both to enhance the accuracy of PLBA predictions. In these graphs, nodes represent atomic structures, while edges depict chemical bonds and spatial relationship. The proposed model, leveraging deep-learning algorithms, effectively learns to correlate these graphical representations with binding affinities. This graph-based representations approach enhances the model's ability to capture the complex molecular interactions critical in PLBA. This work represents a promising advancement in computational techniques for protein-ligand binding prediction, offering a potential path toward more efficient and accurate predictions in drug development. Comparative analysis indicates that the proposed ERL-ProLiGraph outperforms previous models, showcasing notable efficacy and providing a more suitable approach for accurate PLBA predictions.</p>\",\"PeriodicalId\":18853,\"journal\":{\"name\":\"Molecular Informatics\",\"volume\":\" \",\"pages\":\"e202400044\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11639045/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Molecular Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1002/minf.202400044\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/10/15 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"CHEMISTRY, MEDICINAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Molecular Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1002/minf.202400044","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/10/15 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"CHEMISTRY, MEDICINAL","Score":null,"Total":0}
ERL-ProLiGraph: Enhanced representation learning on protein-ligand graph structured data for binding affinity prediction.
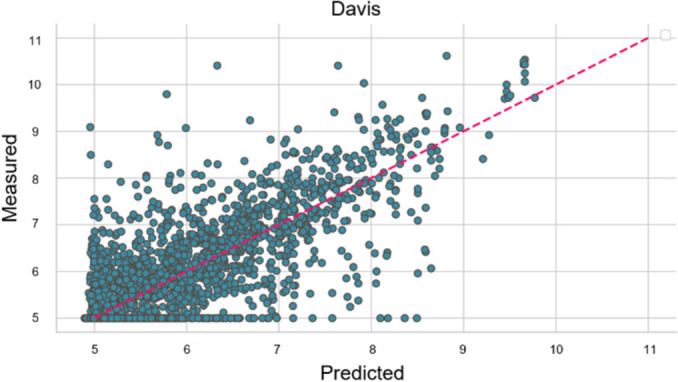
Predicting Protein-Ligand Binding Affinity (PLBA) is pivotal in drug development, as accurate estimations of PLBA expedite the identification of promising drug candidates for specific targets, thereby accelerating the drug discovery process. Despite substantial advancements in PLBA prediction, developing an efficient and more accurate method remains non-trivial. Unlike previous computer-aid PLBA studies which primarily using ligand SMILES and protein sequences represented as strings, this research introduces a Deep Learning-based method, the Enhanced Representation Learning on Protein-Ligand Graph Structured data for Binding Affinity Prediction (ERL-ProLiGraph). The unique aspect of this method is the use of graph representations for both proteins and ligands, intending to learn structural information continued from both to enhance the accuracy of PLBA predictions. In these graphs, nodes represent atomic structures, while edges depict chemical bonds and spatial relationship. The proposed model, leveraging deep-learning algorithms, effectively learns to correlate these graphical representations with binding affinities. This graph-based representations approach enhances the model's ability to capture the complex molecular interactions critical in PLBA. This work represents a promising advancement in computational techniques for protein-ligand binding prediction, offering a potential path toward more efficient and accurate predictions in drug development. Comparative analysis indicates that the proposed ERL-ProLiGraph outperforms previous models, showcasing notable efficacy and providing a more suitable approach for accurate PLBA predictions.
期刊介绍:
Molecular Informatics is a peer-reviewed, international forum for publication of high-quality, interdisciplinary research on all molecular aspects of bio/cheminformatics and computer-assisted molecular design. Molecular Informatics succeeded QSAR & Combinatorial Science in 2010.
Molecular Informatics presents methodological innovations that will lead to a deeper understanding of ligand-receptor interactions, macromolecular complexes, molecular networks, design concepts and processes that demonstrate how ideas and design concepts lead to molecules with a desired structure or function, preferably including experimental validation.
The journal''s scope includes but is not limited to the fields of drug discovery and chemical biology, protein and nucleic acid engineering and design, the design of nanomolecular structures, strategies for modeling of macromolecular assemblies, molecular networks and systems, pharmaco- and chemogenomics, computer-assisted screening strategies, as well as novel technologies for the de novo design of biologically active molecules. As a unique feature Molecular Informatics publishes so-called "Methods Corner" review-type articles which feature important technological concepts and advances within the scope of the journal.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
