Jessica B. Hopson;Anthime Flaus;Colm J. McGinnity;Radhouene Neji;Andrew J. Reader;Alexander Hammers
{"title":"用于 PET 图像质量自动评估的深度卷积骨干比较。","authors":"Jessica B. Hopson;Anthime Flaus;Colm J. McGinnity;Radhouene Neji;Andrew J. Reader;Alexander Hammers","doi":"10.1109/TRPMS.2024.3436697","DOIUrl":null,"url":null,"abstract":"Pretraining deep convolutional network mappings using natural images helps with medical imaging analysis tasks; this is important given the limited number of clinically annotated medical images. Many 2-D pretrained backbone networks, however, are currently available. This work compared 18 different backbones from 5 architecture groups (pretrained on ImageNet) for the task of assessing [18F]FDG brain positron emission tomography (PET) image quality (reconstructed at seven simulated doses), based on three clinical image quality metrics (global quality rating, pattern recognition, and diagnostic confidence). Using 2-D randomly sampled patches, up to eight patients (at three dose levels each) were used for training, with three separate patient datasets used for testing. Each backbone was trained five times with the same training and validation sets, and with six cross-folds. Training only the final fully connected layer (with ~6000–20000 trainable parameters) achieved a test mean-absolute-error (MAE) of ~0.5 (which was within the intrinsic uncertainty of clinical scoring). To compare “classical” and over-parameterized regimes, the pretrained weights of the last 40% of the network layers were then unfrozen. The MAE fell below 0.5 for 14 out of the 18 backbones assessed, including two that previously failed to train. Generally, backbones with residual units (e.g., DenseNets and ResNetV2s), were suited to this task, in terms of achieving the lowest MAE at test time (~0.45–0.5). This proof-of-concept study shows that over-parameterization may also be important for automated PET image quality assessments.","PeriodicalId":46807,"journal":{"name":"IEEE Transactions on Radiation and Plasma Medical Sciences","volume":"8 8","pages":"893-901"},"PeriodicalIF":3.8000,"publicationDate":"2024-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Deep Convolutional Backbone Comparison for Automated PET Image Quality Assessment\",\"authors\":\"Jessica B. Hopson;Anthime Flaus;Colm J. McGinnity;Radhouene Neji;Andrew J. Reader;Alexander Hammers\",\"doi\":\"10.1109/TRPMS.2024.3436697\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Pretraining deep convolutional network mappings using natural images helps with medical imaging analysis tasks; this is important given the limited number of clinically annotated medical images. Many 2-D pretrained backbone networks, however, are currently available. This work compared 18 different backbones from 5 architecture groups (pretrained on ImageNet) for the task of assessing [18F]FDG brain positron emission tomography (PET) image quality (reconstructed at seven simulated doses), based on three clinical image quality metrics (global quality rating, pattern recognition, and diagnostic confidence). Using 2-D randomly sampled patches, up to eight patients (at three dose levels each) were used for training, with three separate patient datasets used for testing. Each backbone was trained five times with the same training and validation sets, and with six cross-folds. Training only the final fully connected layer (with ~6000–20000 trainable parameters) achieved a test mean-absolute-error (MAE) of ~0.5 (which was within the intrinsic uncertainty of clinical scoring). To compare “classical” and over-parameterized regimes, the pretrained weights of the last 40% of the network layers were then unfrozen. The MAE fell below 0.5 for 14 out of the 18 backbones assessed, including two that previously failed to train. Generally, backbones with residual units (e.g., DenseNets and ResNetV2s), were suited to this task, in terms of achieving the lowest MAE at test time (~0.45–0.5). This proof-of-concept study shows that over-parameterization may also be important for automated PET image quality assessments.\",\"PeriodicalId\":46807,\"journal\":{\"name\":\"IEEE Transactions on Radiation and Plasma Medical Sciences\",\"volume\":\"8 8\",\"pages\":\"893-901\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2024-08-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"IEEE Transactions on Radiation and Plasma Medical Sciences\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://ieeexplore.ieee.org/document/10620309/\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"IEEE Transactions on Radiation and Plasma Medical Sciences","FirstCategoryId":"1085","ListUrlMain":"https://ieeexplore.ieee.org/document/10620309/","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"RADIOLOGY, NUCLEAR MEDICINE & MEDICAL IMAGING","Score":null,"Total":0}
Deep Convolutional Backbone Comparison for Automated PET Image Quality Assessment
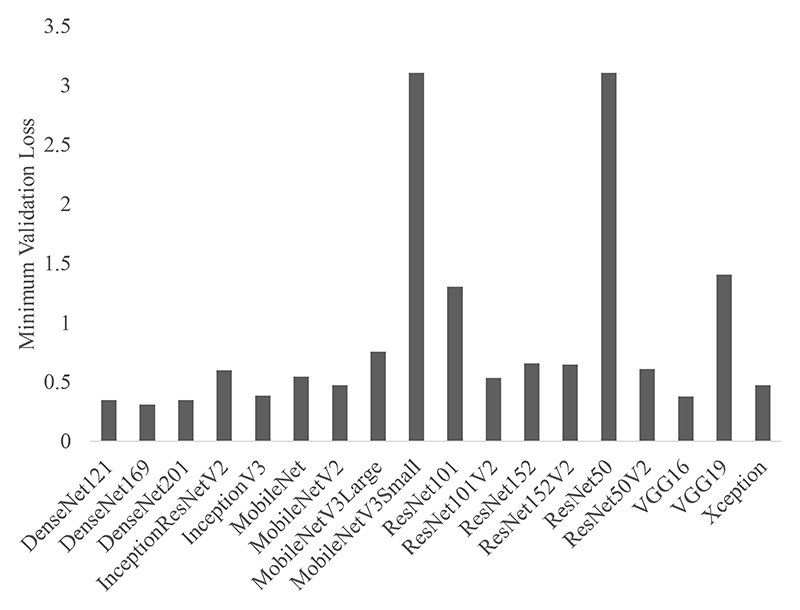
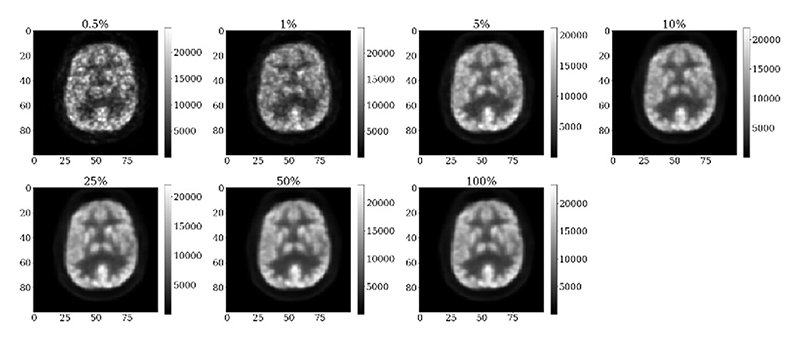
Pretraining deep convolutional network mappings using natural images helps with medical imaging analysis tasks; this is important given the limited number of clinically annotated medical images. Many 2-D pretrained backbone networks, however, are currently available. This work compared 18 different backbones from 5 architecture groups (pretrained on ImageNet) for the task of assessing [18F]FDG brain positron emission tomography (PET) image quality (reconstructed at seven simulated doses), based on three clinical image quality metrics (global quality rating, pattern recognition, and diagnostic confidence). Using 2-D randomly sampled patches, up to eight patients (at three dose levels each) were used for training, with three separate patient datasets used for testing. Each backbone was trained five times with the same training and validation sets, and with six cross-folds. Training only the final fully connected layer (with ~6000–20000 trainable parameters) achieved a test mean-absolute-error (MAE) of ~0.5 (which was within the intrinsic uncertainty of clinical scoring). To compare “classical” and over-parameterized regimes, the pretrained weights of the last 40% of the network layers were then unfrozen. The MAE fell below 0.5 for 14 out of the 18 backbones assessed, including two that previously failed to train. Generally, backbones with residual units (e.g., DenseNets and ResNetV2s), were suited to this task, in terms of achieving the lowest MAE at test time (~0.45–0.5). This proof-of-concept study shows that over-parameterization may also be important for automated PET image quality assessments.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
