{"title":"面对面:比较 ChatGPT 与人类在人脸匹配方面的表现。","authors":"Robin S S Kramer","doi":"10.1177/03010066241295992","DOIUrl":null,"url":null,"abstract":"<p><p>ChatGPT's large language model, GPT-4V, has been trained on vast numbers of image-text pairs and is therefore capable of processing visual input. This model operates very differently from current state-of-the-art neural networks designed specifically for face perception and so I chose to investigate whether ChatGPT could also be applied to this domain. With this aim, I focussed on the task of face matching, that is, deciding whether two photographs showed the same person or not. Across six different tests, ChatGPT demonstrated performance that was comparable with human accuracies despite being a domain-general 'virtual assistant' rather than a specialised tool for face processing. This perhaps surprising result identifies a new avenue for exploration in this field, while further research should explore the boundaries of ChatGPT's ability, along with how its errors may relate to those made by humans.</p>","PeriodicalId":49708,"journal":{"name":"Perception","volume":" ","pages":"65-68"},"PeriodicalIF":1.5000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11646356/pdf/","citationCount":"0","resultStr":"{\"title\":\"Face to face: Comparing ChatGPT with human performance on face matching.\",\"authors\":\"Robin S S Kramer\",\"doi\":\"10.1177/03010066241295992\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>ChatGPT's large language model, GPT-4V, has been trained on vast numbers of image-text pairs and is therefore capable of processing visual input. This model operates very differently from current state-of-the-art neural networks designed specifically for face perception and so I chose to investigate whether ChatGPT could also be applied to this domain. With this aim, I focussed on the task of face matching, that is, deciding whether two photographs showed the same person or not. Across six different tests, ChatGPT demonstrated performance that was comparable with human accuracies despite being a domain-general 'virtual assistant' rather than a specialised tool for face processing. This perhaps surprising result identifies a new avenue for exploration in this field, while further research should explore the boundaries of ChatGPT's ability, along with how its errors may relate to those made by humans.</p>\",\"PeriodicalId\":49708,\"journal\":{\"name\":\"Perception\",\"volume\":\" \",\"pages\":\"65-68\"},\"PeriodicalIF\":1.5000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11646356/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Perception\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://doi.org/10.1177/03010066241295992\",\"RegionNum\":4,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/11/5 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"OPHTHALMOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Perception","FirstCategoryId":"102","ListUrlMain":"https://doi.org/10.1177/03010066241295992","RegionNum":4,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/5 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"OPHTHALMOLOGY","Score":null,"Total":0}
Face to face: Comparing ChatGPT with human performance on face matching.
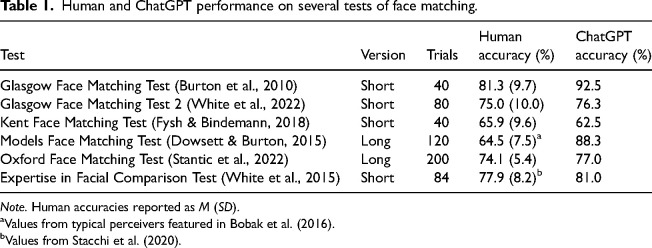
ChatGPT's large language model, GPT-4V, has been trained on vast numbers of image-text pairs and is therefore capable of processing visual input. This model operates very differently from current state-of-the-art neural networks designed specifically for face perception and so I chose to investigate whether ChatGPT could also be applied to this domain. With this aim, I focussed on the task of face matching, that is, deciding whether two photographs showed the same person or not. Across six different tests, ChatGPT demonstrated performance that was comparable with human accuracies despite being a domain-general 'virtual assistant' rather than a specialised tool for face processing. This perhaps surprising result identifies a new avenue for exploration in this field, while further research should explore the boundaries of ChatGPT's ability, along with how its errors may relate to those made by humans.
期刊介绍:
Perception is a traditional print journal covering all areas of the perceptual sciences, but with a strong historical emphasis on perceptual illusions. Perception is a subscription journal, free for authors to publish their research as a Standard Article, Short Report or Short & Sweet. The journal also publishes Editorials and Book Reviews.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
