Ngoc Thien Le, Thanh Le Truong, Sunchai Deelertpaiboon, Wattanasak Srisiri, Pear Ferreira Pongsachareonnont, Disorn Suwajanakorn, Apivat Mavichak, Rath Itthipanichpong, Widhyakorn Asdornwised, Watit Benjapolakul, Surachai Chaitusaney, Pasu Kaewplung
{"title":"ViT-AMD:从眼底图像诊断年龄相关性黄斑变性的新型深度学习模型","authors":"Ngoc Thien Le, Thanh Le Truong, Sunchai Deelertpaiboon, Wattanasak Srisiri, Pear Ferreira Pongsachareonnont, Disorn Suwajanakorn, Apivat Mavichak, Rath Itthipanichpong, Widhyakorn Asdornwised, Watit Benjapolakul, Surachai Chaitusaney, Pasu Kaewplung","doi":"10.1155/2024/3026500","DOIUrl":null,"url":null,"abstract":"<div>\n <p>Age-related macular degeneration (AMD) diagnosis using fundus images is one of the critical missions of the eye-care screening program in many countries. Various proposed deep learning models have been studied for this research interest, which aim to achieve the mission and outperform human-based approaches. However, research efforts are still required for the improvement of model classification accuracy, sensitivity, and specificity values. In this study, we proposed the model named as ViT-AMD, which is based on the latest Vision Transformer (ViT) structure, to diagnosis a fundus image as normal, dry AMD, or wet AMD types. Unlike convolution neural network models, ViT consists of the attention map layers, which show more effective performance for image classification task. Our training process is based on the 5-fold cross-validation and transfer learning techniques using Chula-AMD dataset at the Department of Ophthalmology, the King Chulalongkorn Memorial Hospital, Bangkok. Furthermore, we also test the performance of trained model using an independent image datasets. The results showed that for the 3-classes AMD classification (normal vs. dry AMD vs. wet AMD) on the Chula-AMD dataset, the averaged accuracy, precision, sensitivity, and specificity of our trained model are about 93.40%, 92.15%, 91.27%, and 96.57%, respectively. For result testing on independent datasets, the averaged accuracy, precision, sensitivity, and specificity of trained model are about 74, 20%, 75.35%, 74.13%, and 87.07%, respectively. Compared with the results from the baseline CNN-based model (DenseNet201), the trained ViT-AMD model has outperformed significantly. In conclusion, the ViT-AMD model have proved their usefulness to assist the ophthalmologist to diagnosis the AMD disease.</p>\n </div>","PeriodicalId":14089,"journal":{"name":"International Journal of Intelligent Systems","volume":"2024 1","pages":""},"PeriodicalIF":3.7000,"publicationDate":"2024-11-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1155/2024/3026500","citationCount":"0","resultStr":"{\"title\":\"ViT-AMD: A New Deep Learning Model for Age-Related Macular Degeneration Diagnosis From Fundus Images\",\"authors\":\"Ngoc Thien Le, Thanh Le Truong, Sunchai Deelertpaiboon, Wattanasak Srisiri, Pear Ferreira Pongsachareonnont, Disorn Suwajanakorn, Apivat Mavichak, Rath Itthipanichpong, Widhyakorn Asdornwised, Watit Benjapolakul, Surachai Chaitusaney, Pasu Kaewplung\",\"doi\":\"10.1155/2024/3026500\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div>\\n <p>Age-related macular degeneration (AMD) diagnosis using fundus images is one of the critical missions of the eye-care screening program in many countries. Various proposed deep learning models have been studied for this research interest, which aim to achieve the mission and outperform human-based approaches. However, research efforts are still required for the improvement of model classification accuracy, sensitivity, and specificity values. In this study, we proposed the model named as ViT-AMD, which is based on the latest Vision Transformer (ViT) structure, to diagnosis a fundus image as normal, dry AMD, or wet AMD types. Unlike convolution neural network models, ViT consists of the attention map layers, which show more effective performance for image classification task. Our training process is based on the 5-fold cross-validation and transfer learning techniques using Chula-AMD dataset at the Department of Ophthalmology, the King Chulalongkorn Memorial Hospital, Bangkok. Furthermore, we also test the performance of trained model using an independent image datasets. The results showed that for the 3-classes AMD classification (normal vs. dry AMD vs. wet AMD) on the Chula-AMD dataset, the averaged accuracy, precision, sensitivity, and specificity of our trained model are about 93.40%, 92.15%, 91.27%, and 96.57%, respectively. For result testing on independent datasets, the averaged accuracy, precision, sensitivity, and specificity of trained model are about 74, 20%, 75.35%, 74.13%, and 87.07%, respectively. Compared with the results from the baseline CNN-based model (DenseNet201), the trained ViT-AMD model has outperformed significantly. In conclusion, the ViT-AMD model have proved their usefulness to assist the ophthalmologist to diagnosis the AMD disease.</p>\\n </div>\",\"PeriodicalId\":14089,\"journal\":{\"name\":\"International Journal of Intelligent Systems\",\"volume\":\"2024 1\",\"pages\":\"\"},\"PeriodicalIF\":3.7000,\"publicationDate\":\"2024-11-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1155/2024/3026500\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International Journal of Intelligent Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1155/2024/3026500\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Intelligent Systems","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1155/2024/3026500","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
ViT-AMD: A New Deep Learning Model for Age-Related Macular Degeneration Diagnosis From Fundus Images
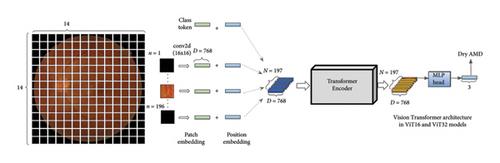
Age-related macular degeneration (AMD) diagnosis using fundus images is one of the critical missions of the eye-care screening program in many countries. Various proposed deep learning models have been studied for this research interest, which aim to achieve the mission and outperform human-based approaches. However, research efforts are still required for the improvement of model classification accuracy, sensitivity, and specificity values. In this study, we proposed the model named as ViT-AMD, which is based on the latest Vision Transformer (ViT) structure, to diagnosis a fundus image as normal, dry AMD, or wet AMD types. Unlike convolution neural network models, ViT consists of the attention map layers, which show more effective performance for image classification task. Our training process is based on the 5-fold cross-validation and transfer learning techniques using Chula-AMD dataset at the Department of Ophthalmology, the King Chulalongkorn Memorial Hospital, Bangkok. Furthermore, we also test the performance of trained model using an independent image datasets. The results showed that for the 3-classes AMD classification (normal vs. dry AMD vs. wet AMD) on the Chula-AMD dataset, the averaged accuracy, precision, sensitivity, and specificity of our trained model are about 93.40%, 92.15%, 91.27%, and 96.57%, respectively. For result testing on independent datasets, the averaged accuracy, precision, sensitivity, and specificity of trained model are about 74, 20%, 75.35%, 74.13%, and 87.07%, respectively. Compared with the results from the baseline CNN-based model (DenseNet201), the trained ViT-AMD model has outperformed significantly. In conclusion, the ViT-AMD model have proved their usefulness to assist the ophthalmologist to diagnosis the AMD disease.
期刊介绍:
The International Journal of Intelligent Systems serves as a forum for individuals interested in tapping into the vast theories based on intelligent systems construction. With its peer-reviewed format, the journal explores several fascinating editorials written by today''s experts in the field. Because new developments are being introduced each day, there''s much to be learned — examination, analysis creation, information retrieval, man–computer interactions, and more. The International Journal of Intelligent Systems uses charts and illustrations to demonstrate these ground-breaking issues, and encourages readers to share their thoughts and experiences.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
