Eugeniu Strelet, Zhenyu Wang, You Peng, Ivan Castillo, Ricardo Rendall, Marco S. Reis
{"title":"用于工业流程中多模态数据整合的正则化贝叶斯融合技术","authors":"Eugeniu Strelet, Zhenyu Wang, You Peng, Ivan Castillo, Ricardo Rendall, Marco S. Reis","doi":"10.1021/acs.iecr.4c02956","DOIUrl":null,"url":null,"abstract":"The collection of data from multiple sources with distinct modalities and varying levels of quality is pervasive in modern industry. Furthermore, associated with each source are often different sampling rates, and some sources may not even have a regular acquisition pattern. These aspects pose significant challenges when developing machine learning (ML) models for predicting target variables, such as product properties, or process key performance indicators (KPIs). Data imputation schemes are a common solution but often require case-by-case analysis to mitigate the risk of introducing unrealistic artifacts, complicating the analysis pipeline and making the process more complex and less scalable. This work introduces a flexible solution for combining redundant sources of information with respect to a target response, considering their associated quality, while accommodating for different sampling rates and information quality. The proposed Regularized Bayesian Fusion (RegBF) approach aims to produce estimates of the target variable with an expected smoothness level, being at the same time compatible with the dominant dynamic mode of the industrial process. The methodology is scalable and flexible, as it can incorporate new data sources, at any time, in the form of either dynamic first-principle models, data-driven ML models, or instrumental information sources (e.g., online or laboratory analytical instruments). The proposed approach is tested in two case studies: one from a Kamyr digester process and the other from a wastewater treatment plant operation.","PeriodicalId":39,"journal":{"name":"Industrial & Engineering Chemistry Research","volume":"128 1","pages":""},"PeriodicalIF":3.9000,"publicationDate":"2024-11-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Regularized Bayesian Fusion for Multimodal Data Integration in Industrial Processes\",\"authors\":\"Eugeniu Strelet, Zhenyu Wang, You Peng, Ivan Castillo, Ricardo Rendall, Marco S. Reis\",\"doi\":\"10.1021/acs.iecr.4c02956\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"The collection of data from multiple sources with distinct modalities and varying levels of quality is pervasive in modern industry. Furthermore, associated with each source are often different sampling rates, and some sources may not even have a regular acquisition pattern. These aspects pose significant challenges when developing machine learning (ML) models for predicting target variables, such as product properties, or process key performance indicators (KPIs). Data imputation schemes are a common solution but often require case-by-case analysis to mitigate the risk of introducing unrealistic artifacts, complicating the analysis pipeline and making the process more complex and less scalable. This work introduces a flexible solution for combining redundant sources of information with respect to a target response, considering their associated quality, while accommodating for different sampling rates and information quality. The proposed Regularized Bayesian Fusion (RegBF) approach aims to produce estimates of the target variable with an expected smoothness level, being at the same time compatible with the dominant dynamic mode of the industrial process. The methodology is scalable and flexible, as it can incorporate new data sources, at any time, in the form of either dynamic first-principle models, data-driven ML models, or instrumental information sources (e.g., online or laboratory analytical instruments). The proposed approach is tested in two case studies: one from a Kamyr digester process and the other from a wastewater treatment plant operation.\",\"PeriodicalId\":39,\"journal\":{\"name\":\"Industrial & Engineering Chemistry Research\",\"volume\":\"128 1\",\"pages\":\"\"},\"PeriodicalIF\":3.9000,\"publicationDate\":\"2024-11-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Industrial & Engineering Chemistry Research\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1021/acs.iecr.4c02956\",\"RegionNum\":3,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"ENGINEERING, CHEMICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Industrial & Engineering Chemistry Research","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1021/acs.iecr.4c02956","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"ENGINEERING, CHEMICAL","Score":null,"Total":0}
引用次数: 0
摘要
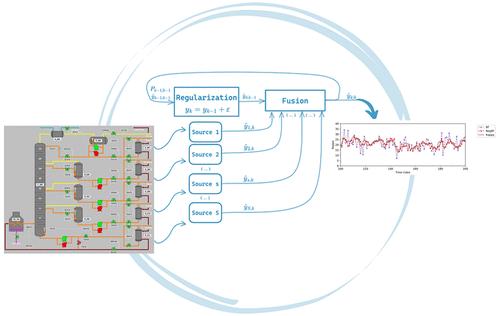
现代工业普遍采用不同模式和不同质量水平的多种来源收集数据。此外,与每个数据源相关的采样率往往不同,有些数据源甚至可能没有固定的采集模式。在开发用于预测目标变量(如产品属性或流程关键性能指标 (KPI))的机器学习 (ML) 模型时,这些方面会带来巨大挑战。数据估算方案是一种常见的解决方案,但通常需要逐案分析,以降低引入不切实际的人工智能的风险,从而使分析管道复杂化,并使流程变得更加复杂,可扩展性降低。这项工作引入了一种灵活的解决方案,用于结合与目标响应相关的冗余信息源,同时考虑到它们的相关质量,并适应不同的采样率和信息质量。所提出的正则化贝叶斯融合(RegBF)方法旨在产生具有预期平滑度的目标变量估计值,同时与工业流程的主导动态模式相兼容。该方法具有可扩展性和灵活性,因为它可以随时以动态第一原理模型、数据驱动的 ML 模型或工具信息源(如在线或实验室分析仪器)的形式纳入新的数据源。所提出的方法在两个案例研究中进行了测试:一个来自卡米尔消化器工艺,另一个来自污水处理厂运行。
Regularized Bayesian Fusion for Multimodal Data Integration in Industrial Processes
The collection of data from multiple sources with distinct modalities and varying levels of quality is pervasive in modern industry. Furthermore, associated with each source are often different sampling rates, and some sources may not even have a regular acquisition pattern. These aspects pose significant challenges when developing machine learning (ML) models for predicting target variables, such as product properties, or process key performance indicators (KPIs). Data imputation schemes are a common solution but often require case-by-case analysis to mitigate the risk of introducing unrealistic artifacts, complicating the analysis pipeline and making the process more complex and less scalable. This work introduces a flexible solution for combining redundant sources of information with respect to a target response, considering their associated quality, while accommodating for different sampling rates and information quality. The proposed Regularized Bayesian Fusion (RegBF) approach aims to produce estimates of the target variable with an expected smoothness level, being at the same time compatible with the dominant dynamic mode of the industrial process. The methodology is scalable and flexible, as it can incorporate new data sources, at any time, in the form of either dynamic first-principle models, data-driven ML models, or instrumental information sources (e.g., online or laboratory analytical instruments). The proposed approach is tested in two case studies: one from a Kamyr digester process and the other from a wastewater treatment plant operation.
期刊介绍:
ndustrial & Engineering Chemistry, with variations in title and format, has been published since 1909 by the American Chemical Society. Industrial & Engineering Chemistry Research is a weekly publication that reports industrial and academic research in the broad fields of applied chemistry and chemical engineering with special focus on fundamentals, processes, and products.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
