Ahmed Elsayed , Sarah Rixon , Jana Levison , Andrew Binns , Pradeep Goel
{"title":"用于预测农业流域地表水中营养物质浓度的机器学习模型。","authors":"Ahmed Elsayed , Sarah Rixon , Jana Levison , Andrew Binns , Pradeep Goel","doi":"10.1016/j.jenvman.2024.123305","DOIUrl":null,"url":null,"abstract":"<div><div>Prediction and quantification of nutrient concentrations in surface water has gained substantial attention during recent decades because excess nutrients released from agricultural and urban watersheds can significantly deteriorate surface water quality. Machine learning (ML) models are considered an effective tool for better understanding and characterization of nutrient release from agricultural fields to surface water. However, to date, no systematic investigations have examined the implementation of different classification and regression ML models in agricultural settings to predict nutrient concentrations in surface water using a group of input variables including climatological (e.g., precipitation), hydrological (e.g., stream flow) and field characteristics (i.e., land and crop use). In the current study, multiple classification (e.g., decision trees) and regression (e.g., regression trees) ML models were applied on a dataset pertaining to surface water quality in an agricultural watershed in southern Ontario, Canada (i.e., Upper Parkhill watershed). The target variables of these models were the nutrient concentrations in surface water including nitrate, total phosphorus, soluble reactive phosphorus, and total dissolved phosphorus. These target variables were predicted using physical and chemical water parameters of surface water (e.g., temperature and DO), climatological, hydrological, and field conditions as the input variables. The performance of these different models was assessed using various evaluation metrics such as classification accuracy (CA) and coefficient of determination (R<sup>2</sup>) for classification and regression models, respectively. In general, both the ensemble bagged trees and logistic regression (CA <span><math><mrow><mo>≥</mo></mrow></math></span> 0.72), and exponential Gaussian process regression (R<sup>2</sup> <span><math><mrow><mo>≥</mo></mrow></math></span> 0.93) models were the optimal classification and regression ML algorithms, respectively, where they resulted in the highest prediction accuracy of the target variables. The insights and outcomes of the current study demonstrates that ML models can be employed to effectively predict and quantify the nutrient concentrations in surface waters to supplement field-collected monitoring data in agricultural watersheds, assisting in maintaining high quality of the available surface water resources.</div></div>","PeriodicalId":356,"journal":{"name":"Journal of Environmental Management","volume":"372 ","pages":"Article 123305"},"PeriodicalIF":8.4000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Machine learning models for prediction of nutrient concentrations in surface water in an agricultural watershed\",\"authors\":\"Ahmed Elsayed , Sarah Rixon , Jana Levison , Andrew Binns , Pradeep Goel\",\"doi\":\"10.1016/j.jenvman.2024.123305\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>Prediction and quantification of nutrient concentrations in surface water has gained substantial attention during recent decades because excess nutrients released from agricultural and urban watersheds can significantly deteriorate surface water quality. Machine learning (ML) models are considered an effective tool for better understanding and characterization of nutrient release from agricultural fields to surface water. However, to date, no systematic investigations have examined the implementation of different classification and regression ML models in agricultural settings to predict nutrient concentrations in surface water using a group of input variables including climatological (e.g., precipitation), hydrological (e.g., stream flow) and field characteristics (i.e., land and crop use). In the current study, multiple classification (e.g., decision trees) and regression (e.g., regression trees) ML models were applied on a dataset pertaining to surface water quality in an agricultural watershed in southern Ontario, Canada (i.e., Upper Parkhill watershed). The target variables of these models were the nutrient concentrations in surface water including nitrate, total phosphorus, soluble reactive phosphorus, and total dissolved phosphorus. These target variables were predicted using physical and chemical water parameters of surface water (e.g., temperature and DO), climatological, hydrological, and field conditions as the input variables. The performance of these different models was assessed using various evaluation metrics such as classification accuracy (CA) and coefficient of determination (R<sup>2</sup>) for classification and regression models, respectively. In general, both the ensemble bagged trees and logistic regression (CA <span><math><mrow><mo>≥</mo></mrow></math></span> 0.72), and exponential Gaussian process regression (R<sup>2</sup> <span><math><mrow><mo>≥</mo></mrow></math></span> 0.93) models were the optimal classification and regression ML algorithms, respectively, where they resulted in the highest prediction accuracy of the target variables. The insights and outcomes of the current study demonstrates that ML models can be employed to effectively predict and quantify the nutrient concentrations in surface waters to supplement field-collected monitoring data in agricultural watersheds, assisting in maintaining high quality of the available surface water resources.</div></div>\",\"PeriodicalId\":356,\"journal\":{\"name\":\"Journal of Environmental Management\",\"volume\":\"372 \",\"pages\":\"Article 123305\"},\"PeriodicalIF\":8.4000,\"publicationDate\":\"2024-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Environmental Management\",\"FirstCategoryId\":\"93\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0301479724032912\",\"RegionNum\":2,\"RegionCategory\":\"环境科学与生态学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/11/19 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"ENVIRONMENTAL SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Environmental Management","FirstCategoryId":"93","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0301479724032912","RegionNum":2,"RegionCategory":"环境科学与生态学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/19 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"ENVIRONMENTAL SCIENCES","Score":null,"Total":0}
引用次数: 0
摘要
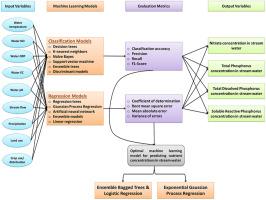
近几十年来,地表水中营养物质浓度的预测和量化受到了广泛关注,因为农业和城市流域释放的过量营养物质会严重恶化地表水水质。机器学习(ML)模型被认为是更好地理解和描述农田向地表水释放营养物质的有效工具。然而,迄今为止,还没有系统的研究考察过在农业环境中使用不同的分类和回归 ML 模型来预测地表水中的营养物浓度,这些模型使用了一组输入变量,包括气候变量(如降水)、水文变量(如溪流)和田地特征变量(如土地和作物用途)。在当前的研究中,多重分类(如决策树)和回归(如回归树)ML 模型被应用于加拿大安大略省南部一个农业流域(即上帕克希尔流域)的地表水质相关数据集。这些模型的目标变量是地表水中的营养浓度,包括硝酸盐、总磷、可溶性活性磷和总溶解磷。这些目标变量是利用地表水的物理和化学水参数(如温度和溶解氧)、气候、水文和实地条件作为输入变量进行预测的。这些不同模型的性能分别采用分类准确度(CA)和分类与回归模型的判定系数(R2)等各种评价指标进行评估。总体而言,集合袋装树和逻辑回归(CA ≥ 0.72)以及指数高斯过程回归(R2≥ 0.93)模型分别是最佳的分类和回归 ML 算法,它们对目标变量的预测准确率最高。本研究的见解和结果表明,可以利用 ML 模型有效地预测和量化地表水中的营养物质浓度,以补充农业流域实地采集的监测数据,帮助保持现有地表水资源的高质量。
Machine learning models for prediction of nutrient concentrations in surface water in an agricultural watershed
Prediction and quantification of nutrient concentrations in surface water has gained substantial attention during recent decades because excess nutrients released from agricultural and urban watersheds can significantly deteriorate surface water quality. Machine learning (ML) models are considered an effective tool for better understanding and characterization of nutrient release from agricultural fields to surface water. However, to date, no systematic investigations have examined the implementation of different classification and regression ML models in agricultural settings to predict nutrient concentrations in surface water using a group of input variables including climatological (e.g., precipitation), hydrological (e.g., stream flow) and field characteristics (i.e., land and crop use). In the current study, multiple classification (e.g., decision trees) and regression (e.g., regression trees) ML models were applied on a dataset pertaining to surface water quality in an agricultural watershed in southern Ontario, Canada (i.e., Upper Parkhill watershed). The target variables of these models were the nutrient concentrations in surface water including nitrate, total phosphorus, soluble reactive phosphorus, and total dissolved phosphorus. These target variables were predicted using physical and chemical water parameters of surface water (e.g., temperature and DO), climatological, hydrological, and field conditions as the input variables. The performance of these different models was assessed using various evaluation metrics such as classification accuracy (CA) and coefficient of determination (R2) for classification and regression models, respectively. In general, both the ensemble bagged trees and logistic regression (CA 0.72), and exponential Gaussian process regression (R2 0.93) models were the optimal classification and regression ML algorithms, respectively, where they resulted in the highest prediction accuracy of the target variables. The insights and outcomes of the current study demonstrates that ML models can be employed to effectively predict and quantify the nutrient concentrations in surface waters to supplement field-collected monitoring data in agricultural watersheds, assisting in maintaining high quality of the available surface water resources.
期刊介绍:
The Journal of Environmental Management is a journal for the publication of peer reviewed, original research for all aspects of management and the managed use of the environment, both natural and man-made.Critical review articles are also welcome; submission of these is strongly encouraged.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
