Markus Aigensberger , Christoph Bueschl , Ezequias Castillo-Lopez , Sara Ricci , Raul Rivera-Chacon , Qendrim Zebeli , Franz Berthiller , Heidi E. Schwartz-Zimmermann
{"title":"非靶向代谢组学处理步骤的模块化比较","authors":"Markus Aigensberger , Christoph Bueschl , Ezequias Castillo-Lopez , Sara Ricci , Raul Rivera-Chacon , Qendrim Zebeli , Franz Berthiller , Heidi E. Schwartz-Zimmermann","doi":"10.1016/j.aca.2024.343491","DOIUrl":null,"url":null,"abstract":"<div><h3>Background</h3><div>Untargeted metabolomics requires robust and reliable strategies for data processing to extract relevant information form the underlying raw data. Multiple platforms for data processing are available, but the choice of software tool can have an impact on the analysis. This study provides a comprehensive evaluation of four workflows based on commonly used metabolomics software tools: XCMS, Compound Discoverer, MS-DIAL, and MZmine. These tools were applied to a dataset derived from bovine saliva samples spiked with small polar molecules analyzed by anion exchange chromatography coupled to high resolution mass spectrometry.</div></div><div><h3>Results</h3><div>The analysis revealed significant differences in the number and overlap of detected features, with only approximately 8 % of the features included in all four peak tables. Among the overlapping features, MS-DIAL demonstrated the greatest similarity to manual integration, while XCMS and MZmine also performed well. In contrast, Compound Discoverer had issues to reliably integrate high baseline peaks. This study also explores various post-processing strategies, including missing value imputation, transformation, scaling, and filtering. The assessment of missing values indicated that they primarily originated from low abundance, making imputation with small values the most effective approach. No clear evidence suggested that transformation is necessary for downstream statistical analyses. Auto scaling emerged as the most suitable strategy for data scaling. Low thresholds for blank filtering were found to be the most effective in enhancing data quality. The optimization of filtering thresholds required a careful balance to remove unnecessary information while retaining vital data.</div></div><div><h3>Significance and novelty</h3><div>This work provides an overview of commonly applied strategies in untargeted metabolomics analysis, emphasizing the importance of careful workflow selection and optimization. It serves as a resource for refining data processing strategies to achieve accurate and reliable results, while also offering fresh insights into the challenges encountered throughout the untargeted metabolomics processing pipeline.</div></div>","PeriodicalId":240,"journal":{"name":"Analytica Chimica Acta","volume":"1336 ","pages":"Article 343491"},"PeriodicalIF":6.0000,"publicationDate":"2025-01-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Modular comparison of untargeted metabolomics processing steps\",\"authors\":\"Markus Aigensberger , Christoph Bueschl , Ezequias Castillo-Lopez , Sara Ricci , Raul Rivera-Chacon , Qendrim Zebeli , Franz Berthiller , Heidi E. Schwartz-Zimmermann\",\"doi\":\"10.1016/j.aca.2024.343491\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Background</h3><div>Untargeted metabolomics requires robust and reliable strategies for data processing to extract relevant information form the underlying raw data. Multiple platforms for data processing are available, but the choice of software tool can have an impact on the analysis. This study provides a comprehensive evaluation of four workflows based on commonly used metabolomics software tools: XCMS, Compound Discoverer, MS-DIAL, and MZmine. These tools were applied to a dataset derived from bovine saliva samples spiked with small polar molecules analyzed by anion exchange chromatography coupled to high resolution mass spectrometry.</div></div><div><h3>Results</h3><div>The analysis revealed significant differences in the number and overlap of detected features, with only approximately 8 % of the features included in all four peak tables. Among the overlapping features, MS-DIAL demonstrated the greatest similarity to manual integration, while XCMS and MZmine also performed well. In contrast, Compound Discoverer had issues to reliably integrate high baseline peaks. This study also explores various post-processing strategies, including missing value imputation, transformation, scaling, and filtering. The assessment of missing values indicated that they primarily originated from low abundance, making imputation with small values the most effective approach. No clear evidence suggested that transformation is necessary for downstream statistical analyses. Auto scaling emerged as the most suitable strategy for data scaling. Low thresholds for blank filtering were found to be the most effective in enhancing data quality. The optimization of filtering thresholds required a careful balance to remove unnecessary information while retaining vital data.</div></div><div><h3>Significance and novelty</h3><div>This work provides an overview of commonly applied strategies in untargeted metabolomics analysis, emphasizing the importance of careful workflow selection and optimization. It serves as a resource for refining data processing strategies to achieve accurate and reliable results, while also offering fresh insights into the challenges encountered throughout the untargeted metabolomics processing pipeline.</div></div>\",\"PeriodicalId\":240,\"journal\":{\"name\":\"Analytica Chimica Acta\",\"volume\":\"1336 \",\"pages\":\"Article 343491\"},\"PeriodicalIF\":6.0000,\"publicationDate\":\"2025-01-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Analytica Chimica Acta\",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0003267024012923\",\"RegionNum\":2,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/11/27 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, ANALYTICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Analytica Chimica Acta","FirstCategoryId":"92","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0003267024012923","RegionNum":2,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/27 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"CHEMISTRY, ANALYTICAL","Score":null,"Total":0}
Modular comparison of untargeted metabolomics processing steps
Background
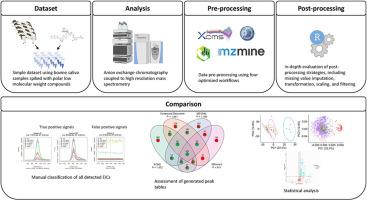
Untargeted metabolomics requires robust and reliable strategies for data processing to extract relevant information form the underlying raw data. Multiple platforms for data processing are available, but the choice of software tool can have an impact on the analysis. This study provides a comprehensive evaluation of four workflows based on commonly used metabolomics software tools: XCMS, Compound Discoverer, MS-DIAL, and MZmine. These tools were applied to a dataset derived from bovine saliva samples spiked with small polar molecules analyzed by anion exchange chromatography coupled to high resolution mass spectrometry.
Results
The analysis revealed significant differences in the number and overlap of detected features, with only approximately 8 % of the features included in all four peak tables. Among the overlapping features, MS-DIAL demonstrated the greatest similarity to manual integration, while XCMS and MZmine also performed well. In contrast, Compound Discoverer had issues to reliably integrate high baseline peaks. This study also explores various post-processing strategies, including missing value imputation, transformation, scaling, and filtering. The assessment of missing values indicated that they primarily originated from low abundance, making imputation with small values the most effective approach. No clear evidence suggested that transformation is necessary for downstream statistical analyses. Auto scaling emerged as the most suitable strategy for data scaling. Low thresholds for blank filtering were found to be the most effective in enhancing data quality. The optimization of filtering thresholds required a careful balance to remove unnecessary information while retaining vital data.
Significance and novelty
This work provides an overview of commonly applied strategies in untargeted metabolomics analysis, emphasizing the importance of careful workflow selection and optimization. It serves as a resource for refining data processing strategies to achieve accurate and reliable results, while also offering fresh insights into the challenges encountered throughout the untargeted metabolomics processing pipeline.
期刊介绍:
Analytica Chimica Acta has an open access mirror journal Analytica Chimica Acta: X, sharing the same aims and scope, editorial team, submission system and rigorous peer review.
Analytica Chimica Acta provides a forum for the rapid publication of original research, and critical, comprehensive reviews dealing with all aspects of fundamental and applied modern analytical chemistry. The journal welcomes the submission of research papers which report studies concerning the development of new and significant analytical methodologies. In determining the suitability of submitted articles for publication, particular scrutiny will be placed on the degree of novelty and impact of the research and the extent to which it adds to the existing body of knowledge in analytical chemistry.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
