Cindy N Ho, Tiffany Tian, Alessandra T Ayers, Rachel E Aaron, Vidith Phillips, Risa M Wolf, Nestoras Mathioudakis, Tinglong Dai, David C Klonoff
{"title":"生物医学文献中用于评估临床决策中大型语言模型的定性指标:叙述性综述。","authors":"Cindy N Ho, Tiffany Tian, Alessandra T Ayers, Rachel E Aaron, Vidith Phillips, Risa M Wolf, Nestoras Mathioudakis, Tinglong Dai, David C Klonoff","doi":"10.1186/s12911-024-02757-z","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The large language models (LLMs), most notably ChatGPT, released since November 30, 2022, have prompted shifting attention to their use in medicine, particularly for supporting clinical decision-making. However, there is little consensus in the medical community on how LLM performance in clinical contexts should be evaluated.</p><p><strong>Methods: </strong>We performed a literature review of PubMed to identify publications between December 1, 2022, and April 1, 2024, that discussed assessments of LLM-generated diagnoses or treatment plans.</p><p><strong>Results: </strong>We selected 108 relevant articles from PubMed for analysis. The most frequently used LLMs were GPT-3.5, GPT-4, Bard, LLaMa/Alpaca-based models, and Bing Chat. The five most frequently used criteria for scoring LLM outputs were \"accuracy\", \"completeness\", \"appropriateness\", \"insight\", and \"consistency\".</p><p><strong>Conclusions: </strong>The most frequently used criteria for defining high-quality LLMs have been consistently selected by researchers over the past 1.5 years. We identified a high degree of variation in how studies reported their findings and assessed LLM performance. Standardized reporting of qualitative evaluation metrics that assess the quality of LLM outputs can be developed to facilitate research studies on LLMs in healthcare.</p>","PeriodicalId":9340,"journal":{"name":"BMC Medical Informatics and Decision Making","volume":"24 1","pages":"357"},"PeriodicalIF":3.8000,"publicationDate":"2024-11-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11590327/pdf/","citationCount":"0","resultStr":"{\"title\":\"Qualitative metrics from the biomedical literature for evaluating large language models in clinical decision-making: a narrative review.\",\"authors\":\"Cindy N Ho, Tiffany Tian, Alessandra T Ayers, Rachel E Aaron, Vidith Phillips, Risa M Wolf, Nestoras Mathioudakis, Tinglong Dai, David C Klonoff\",\"doi\":\"10.1186/s12911-024-02757-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The large language models (LLMs), most notably ChatGPT, released since November 30, 2022, have prompted shifting attention to their use in medicine, particularly for supporting clinical decision-making. However, there is little consensus in the medical community on how LLM performance in clinical contexts should be evaluated.</p><p><strong>Methods: </strong>We performed a literature review of PubMed to identify publications between December 1, 2022, and April 1, 2024, that discussed assessments of LLM-generated diagnoses or treatment plans.</p><p><strong>Results: </strong>We selected 108 relevant articles from PubMed for analysis. The most frequently used LLMs were GPT-3.5, GPT-4, Bard, LLaMa/Alpaca-based models, and Bing Chat. The five most frequently used criteria for scoring LLM outputs were \\\"accuracy\\\", \\\"completeness\\\", \\\"appropriateness\\\", \\\"insight\\\", and \\\"consistency\\\".</p><p><strong>Conclusions: </strong>The most frequently used criteria for defining high-quality LLMs have been consistently selected by researchers over the past 1.5 years. We identified a high degree of variation in how studies reported their findings and assessed LLM performance. Standardized reporting of qualitative evaluation metrics that assess the quality of LLM outputs can be developed to facilitate research studies on LLMs in healthcare.</p>\",\"PeriodicalId\":9340,\"journal\":{\"name\":\"BMC Medical Informatics and Decision Making\",\"volume\":\"24 1\",\"pages\":\"357\"},\"PeriodicalIF\":3.8000,\"publicationDate\":\"2024-11-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11590327/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMC Medical Informatics and Decision Making\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1186/s12911-024-02757-z\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Medical Informatics and Decision Making","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12911-024-02757-z","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
Qualitative metrics from the biomedical literature for evaluating large language models in clinical decision-making: a narrative review.
Background: The large language models (LLMs), most notably ChatGPT, released since November 30, 2022, have prompted shifting attention to their use in medicine, particularly for supporting clinical decision-making. However, there is little consensus in the medical community on how LLM performance in clinical contexts should be evaluated.
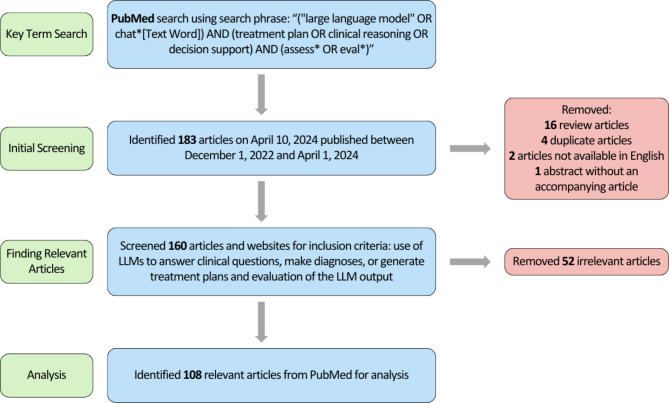
Methods: We performed a literature review of PubMed to identify publications between December 1, 2022, and April 1, 2024, that discussed assessments of LLM-generated diagnoses or treatment plans.
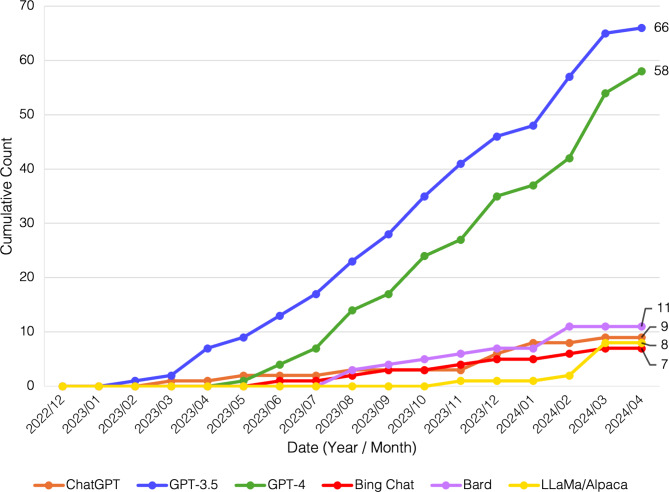
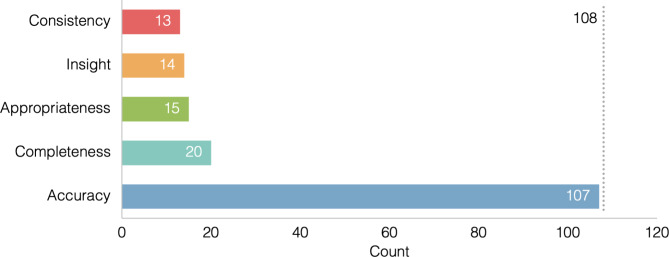
Results: We selected 108 relevant articles from PubMed for analysis. The most frequently used LLMs were GPT-3.5, GPT-4, Bard, LLaMa/Alpaca-based models, and Bing Chat. The five most frequently used criteria for scoring LLM outputs were "accuracy", "completeness", "appropriateness", "insight", and "consistency".
Conclusions: The most frequently used criteria for defining high-quality LLMs have been consistently selected by researchers over the past 1.5 years. We identified a high degree of variation in how studies reported their findings and assessed LLM performance. Standardized reporting of qualitative evaluation metrics that assess the quality of LLM outputs can be developed to facilitate research studies on LLMs in healthcare.
期刊介绍:
BMC Medical Informatics and Decision Making is an open access journal publishing original peer-reviewed research articles in relation to the design, development, implementation, use, and evaluation of health information technologies and decision-making for human health.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
