Michael Heinzinger, Konstantin Weissenow, Joaquin Gomez Sanchez, Adrian Henkel, Milot Mirdita, Martin Steinegger, Burkhard Rost
{"title":"蛋白质序列和结构的双语语言模型。","authors":"Michael Heinzinger, Konstantin Weissenow, Joaquin Gomez Sanchez, Adrian Henkel, Milot Mirdita, Martin Steinegger, Burkhard Rost","doi":"10.1093/nargab/lqae150","DOIUrl":null,"url":null,"abstract":"<p><p>Adapting language models to protein sequences spawned the development of powerful protein language models (pLMs). Concurrently, AlphaFold2 broke through in protein structure prediction. Now we can systematically and comprehensively explore the dual nature of proteins that act and exist as three-dimensional (3D) machines and evolve as linear strings of one-dimensional (1D) sequences. Here, we leverage pLMs to simultaneously model both modalities in a single model. We encode protein structures as token sequences using the 3Di-alphabet introduced by the 3D-alignment method <i>Foldseek</i>. For training, we built a non-redundant dataset from AlphaFoldDB and fine-tuned an existing pLM (ProtT5) to translate between 3Di and amino acid sequences. As a proof-of-concept for our novel approach, dubbed Protein 'structure-sequence' T5 (<i>ProstT5</i>), we showed improved performance for subsequent, structure-related prediction tasks, leading to three orders of magnitude speedup for deriving 3Di. This will be crucial for future applications trying to search metagenomic sequence databases at the sensitivity of structure comparisons. Our work showcased the potential of pLMs to tap into the information-rich protein structure revolution fueled by AlphaFold2. <i>ProstT5</i> paves the way to develop new tools integrating the vast resource of 3D predictions and opens new research avenues in the post-AlphaFold2 era.</p>","PeriodicalId":33994,"journal":{"name":"NAR Genomics and Bioinformatics","volume":"6 4","pages":"lqae150"},"PeriodicalIF":3.0000,"publicationDate":"2024-11-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11616678/pdf/","citationCount":"0","resultStr":"{\"title\":\"Bilingual language model for protein sequence and structure.\",\"authors\":\"Michael Heinzinger, Konstantin Weissenow, Joaquin Gomez Sanchez, Adrian Henkel, Milot Mirdita, Martin Steinegger, Burkhard Rost\",\"doi\":\"10.1093/nargab/lqae150\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Adapting language models to protein sequences spawned the development of powerful protein language models (pLMs). Concurrently, AlphaFold2 broke through in protein structure prediction. Now we can systematically and comprehensively explore the dual nature of proteins that act and exist as three-dimensional (3D) machines and evolve as linear strings of one-dimensional (1D) sequences. Here, we leverage pLMs to simultaneously model both modalities in a single model. We encode protein structures as token sequences using the 3Di-alphabet introduced by the 3D-alignment method <i>Foldseek</i>. For training, we built a non-redundant dataset from AlphaFoldDB and fine-tuned an existing pLM (ProtT5) to translate between 3Di and amino acid sequences. As a proof-of-concept for our novel approach, dubbed Protein 'structure-sequence' T5 (<i>ProstT5</i>), we showed improved performance for subsequent, structure-related prediction tasks, leading to three orders of magnitude speedup for deriving 3Di. This will be crucial for future applications trying to search metagenomic sequence databases at the sensitivity of structure comparisons. Our work showcased the potential of pLMs to tap into the information-rich protein structure revolution fueled by AlphaFold2. <i>ProstT5</i> paves the way to develop new tools integrating the vast resource of 3D predictions and opens new research avenues in the post-AlphaFold2 era.</p>\",\"PeriodicalId\":33994,\"journal\":{\"name\":\"NAR Genomics and Bioinformatics\",\"volume\":\"6 4\",\"pages\":\"lqae150\"},\"PeriodicalIF\":3.0000,\"publicationDate\":\"2024-11-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11616678/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"NAR Genomics and Bioinformatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/nargab/lqae150\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/12/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"GENETICS & HEREDITY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"NAR Genomics and Bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/nargab/lqae150","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/12/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
Bilingual language model for protein sequence and structure.
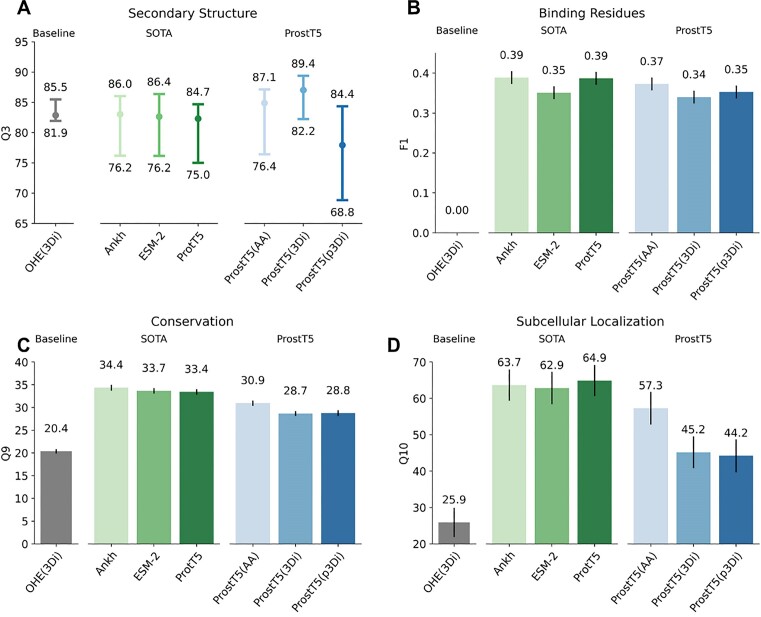
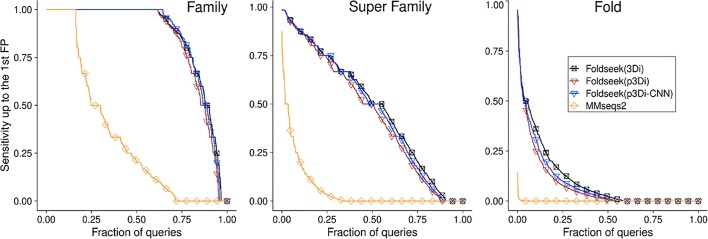
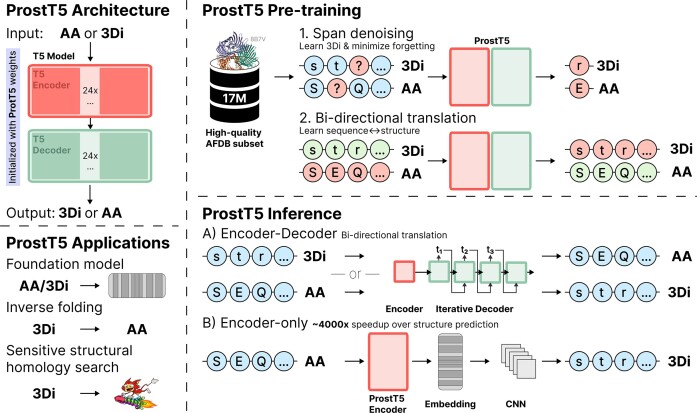
Adapting language models to protein sequences spawned the development of powerful protein language models (pLMs). Concurrently, AlphaFold2 broke through in protein structure prediction. Now we can systematically and comprehensively explore the dual nature of proteins that act and exist as three-dimensional (3D) machines and evolve as linear strings of one-dimensional (1D) sequences. Here, we leverage pLMs to simultaneously model both modalities in a single model. We encode protein structures as token sequences using the 3Di-alphabet introduced by the 3D-alignment method Foldseek. For training, we built a non-redundant dataset from AlphaFoldDB and fine-tuned an existing pLM (ProtT5) to translate between 3Di and amino acid sequences. As a proof-of-concept for our novel approach, dubbed Protein 'structure-sequence' T5 (ProstT5), we showed improved performance for subsequent, structure-related prediction tasks, leading to three orders of magnitude speedup for deriving 3Di. This will be crucial for future applications trying to search metagenomic sequence databases at the sensitivity of structure comparisons. Our work showcased the potential of pLMs to tap into the information-rich protein structure revolution fueled by AlphaFold2. ProstT5 paves the way to develop new tools integrating the vast resource of 3D predictions and opens new research avenues in the post-AlphaFold2 era.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
