Abdulkadir Albayrak , Yao Xiao , Piyush Mukherjee , Sarah S. Barnett , Cherisse A. Marcou , Steven N. Hart
{"title":"通过综合病例报告和基于嵌入的检索增强人类表型本体术语提取:一种改进生物医学数据注释的新方法。","authors":"Abdulkadir Albayrak , Yao Xiao , Piyush Mukherjee , Sarah S. Barnett , Cherisse A. Marcou , Steven N. Hart","doi":"10.1016/j.jpi.2024.100409","DOIUrl":null,"url":null,"abstract":"<div><div>With the increasing utilization of exome and genome sequencing in clinical and research genetics, accurate and automated extraction of human phenotype ontology (HPO) terms from clinical texts has become imperative. Traditional methods for HPO term extraction, such as PhenoTagger, often face limitations in coverage and precision. In this study, we propose a novel approach that leverages large language models (LLMs) to generate synthetic sentences with clinical context, which were semantically encoded into vector embeddings. These embeddings are linked to HPO terms, creating a robust knowledgebase that facilitates precise information retrieval. Our method circumvents the known issue of LLM hallucinations by storing and querying these embeddings within a true database, ensuring accurate context matching without the need for a predictive model. We evaluated the performance of three different embedding models, all of which demonstrated substantial improvements over PhenoTagger. Top recall (sensitivity), precision (positive-predictive value, PPV), and F1 are 0.64, 0.64, and 0.64, respectively, which were 31%, 10%, and 21% better than PhenoTagger. Furthermore, optimal performance was achieved when we combined the best performing embedding model with PhenoTagger (a.k.a. Fused model), resulting in recall (sensitivity), precision (PPV), and F1 values of 0.7, 0.7, and 0.7, respectively, which are 10%, 10%, and 10% better than the best embedding models. Our findings underscore the potential of this integrated approach to enhance the precision and reliability of HPO term extraction, offering a scalable and effective solution for biomedical data annotation.</div></div>","PeriodicalId":37769,"journal":{"name":"Journal of Pathology Informatics","volume":"16 ","pages":"Article 100409"},"PeriodicalIF":0.0000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11667693/pdf/","citationCount":"0","resultStr":"{\"title\":\"Enhancing human phenotype ontology term extraction through synthetic case reports and embedding-based retrieval: A novel approach for improved biomedical data annotation\",\"authors\":\"Abdulkadir Albayrak , Yao Xiao , Piyush Mukherjee , Sarah S. Barnett , Cherisse A. Marcou , Steven N. Hart\",\"doi\":\"10.1016/j.jpi.2024.100409\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><div>With the increasing utilization of exome and genome sequencing in clinical and research genetics, accurate and automated extraction of human phenotype ontology (HPO) terms from clinical texts has become imperative. Traditional methods for HPO term extraction, such as PhenoTagger, often face limitations in coverage and precision. In this study, we propose a novel approach that leverages large language models (LLMs) to generate synthetic sentences with clinical context, which were semantically encoded into vector embeddings. These embeddings are linked to HPO terms, creating a robust knowledgebase that facilitates precise information retrieval. Our method circumvents the known issue of LLM hallucinations by storing and querying these embeddings within a true database, ensuring accurate context matching without the need for a predictive model. We evaluated the performance of three different embedding models, all of which demonstrated substantial improvements over PhenoTagger. Top recall (sensitivity), precision (positive-predictive value, PPV), and F1 are 0.64, 0.64, and 0.64, respectively, which were 31%, 10%, and 21% better than PhenoTagger. Furthermore, optimal performance was achieved when we combined the best performing embedding model with PhenoTagger (a.k.a. Fused model), resulting in recall (sensitivity), precision (PPV), and F1 values of 0.7, 0.7, and 0.7, respectively, which are 10%, 10%, and 10% better than the best embedding models. Our findings underscore the potential of this integrated approach to enhance the precision and reliability of HPO term extraction, offering a scalable and effective solution for biomedical data annotation.</div></div>\",\"PeriodicalId\":37769,\"journal\":{\"name\":\"Journal of Pathology Informatics\",\"volume\":\"16 \",\"pages\":\"Article 100409\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2025-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11667693/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Pathology Informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2153353924000488\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/11/16 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"Medicine\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Pathology Informatics","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2153353924000488","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/16 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"Medicine","Score":null,"Total":0}
Enhancing human phenotype ontology term extraction through synthetic case reports and embedding-based retrieval: A novel approach for improved biomedical data annotation
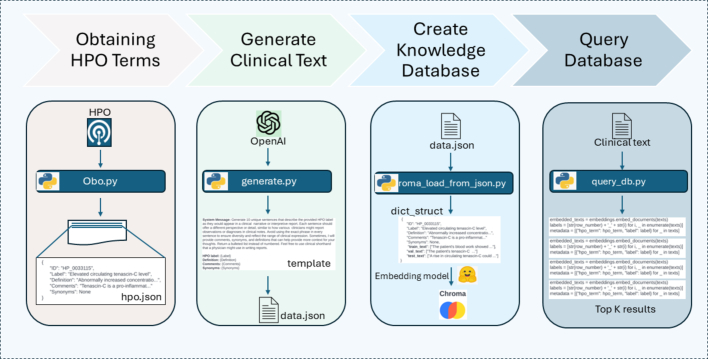
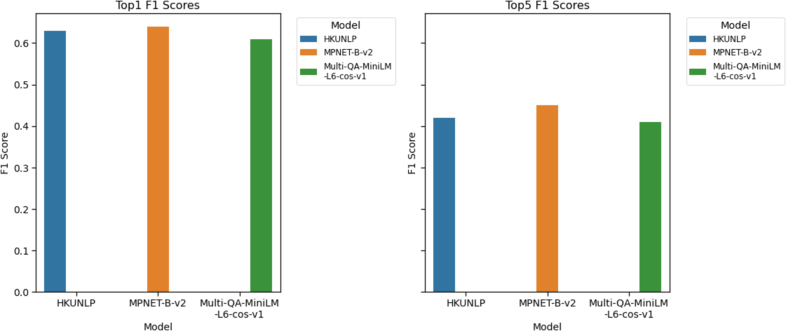
With the increasing utilization of exome and genome sequencing in clinical and research genetics, accurate and automated extraction of human phenotype ontology (HPO) terms from clinical texts has become imperative. Traditional methods for HPO term extraction, such as PhenoTagger, often face limitations in coverage and precision. In this study, we propose a novel approach that leverages large language models (LLMs) to generate synthetic sentences with clinical context, which were semantically encoded into vector embeddings. These embeddings are linked to HPO terms, creating a robust knowledgebase that facilitates precise information retrieval. Our method circumvents the known issue of LLM hallucinations by storing and querying these embeddings within a true database, ensuring accurate context matching without the need for a predictive model. We evaluated the performance of three different embedding models, all of which demonstrated substantial improvements over PhenoTagger. Top recall (sensitivity), precision (positive-predictive value, PPV), and F1 are 0.64, 0.64, and 0.64, respectively, which were 31%, 10%, and 21% better than PhenoTagger. Furthermore, optimal performance was achieved when we combined the best performing embedding model with PhenoTagger (a.k.a. Fused model), resulting in recall (sensitivity), precision (PPV), and F1 values of 0.7, 0.7, and 0.7, respectively, which are 10%, 10%, and 10% better than the best embedding models. Our findings underscore the potential of this integrated approach to enhance the precision and reliability of HPO term extraction, offering a scalable and effective solution for biomedical data annotation.
期刊介绍:
The Journal of Pathology Informatics (JPI) is an open access peer-reviewed journal dedicated to the advancement of pathology informatics. This is the official journal of the Association for Pathology Informatics (API). The journal aims to publish broadly about pathology informatics and freely disseminate all articles worldwide. This journal is of interest to pathologists, informaticians, academics, researchers, health IT specialists, information officers, IT staff, vendors, and anyone with an interest in informatics. We encourage submissions from anyone with an interest in the field of pathology informatics. We publish all types of papers related to pathology informatics including original research articles, technical notes, reviews, viewpoints, commentaries, editorials, symposia, meeting abstracts, book reviews, and correspondence to the editors. All submissions are subject to rigorous peer review by the well-regarded editorial board and by expert referees in appropriate specialties.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
