Lun-Hsiang Yuan, Shi-Wei Huang, Dean Chou, Chung-You Tsai
{"title":"深入对比分析四种大语言人工智能模型,从多模式前列腺癌工作报告中进行风险评估和信息检索。","authors":"Lun-Hsiang Yuan, Shi-Wei Huang, Dean Chou, Chung-You Tsai","doi":"10.5534/wjmh.240173","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>Information retrieval (IR) and risk assessment (RA) from multi-modality imaging and pathology reports are critical to prostate cancer (PC) treatment. This study aims to evaluate the performance of four general-purpose large language model (LLMs) in IR and RA tasks.</p><p><strong>Materials and methods: </strong>We conducted a study using simulated text reports from computed tomography, magnetic resonance imaging, bone scans, and biopsy pathology on stage IV PC patients. We assessed four LLMs (ChatGPT-4-turbo, Claude-3-opus, Gemini-Pro-1.0, ChatGPT-3.5-turbo) on three RA tasks (LATITUDE, CHAARTED, TwNHI) and seven IR tasks. It included TNM staging, and the detection and quantification of bone and visceral metastases, providing a broad evaluation of their capabilities in handling diverse clinical data. We queried LLMs with multi-modality reports using zero-shot chain-of-thought prompting via application programming interface. With three adjudicators' consensus as the gold standard, these models' performances were assessed through repeated single-round queries and ensemble voting methods, using 6 outcome metrics.</p><p><strong>Results: </strong>Among 350 stage IV PC patients with simulated reports, 115 (32.9%), 128 (36.6%), and 94 (26.9%) belonged to LATITUDE, CHAARTED, and TwNHI high-risk, respectively. Ensemble voting, based on three repeated single-round queries, consistently enhances accuracy with a higher likelihood of achieving non-inferior results compared to a single query. Four models showed minimal differences in IR tasks with high accuracy (87.4%-94.2%) and consistency (ICC>0.8) in TNM staging. However, there were significant differences in RA performance, with the ranking as follows: ChatGPT-4-turbo, Claude-3-opus, Gemini-Pro-1.0, and ChatGPT-3.5-turbo, respectively. ChatGPT-4-turbo achieved the highest accuracy (90.1%, 90.7%,91.6%), and consistency (ICC 0.86, 0.93, 0.76) across 3 RA tasks.</p><p><strong>Conclusions: </strong>ChatGPT-4-turbo demonstrated satisfactory accuracy and outcomes in RA and IR for stage IV PC, suggesting its potential for clinical decision support. However, the risks of misinterpretation impacting decision-making cannot be overlooked. Further research is necessary to validate these findings in other cancers.</p>","PeriodicalId":54261,"journal":{"name":"World Journal of Mens Health","volume":" ","pages":"918-933"},"PeriodicalIF":4.3000,"publicationDate":"2025-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12505481/pdf/","citationCount":"0","resultStr":"{\"title\":\"The In-depth Comparative Analysis of Four Large Language AI Models for Risk Assessment and Information Retrieval from Multi-Modality Prostate Cancer Work-up Reports.\",\"authors\":\"Lun-Hsiang Yuan, Shi-Wei Huang, Dean Chou, Chung-You Tsai\",\"doi\":\"10.5534/wjmh.240173\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Purpose: </strong>Information retrieval (IR) and risk assessment (RA) from multi-modality imaging and pathology reports are critical to prostate cancer (PC) treatment. This study aims to evaluate the performance of four general-purpose large language model (LLMs) in IR and RA tasks.</p><p><strong>Materials and methods: </strong>We conducted a study using simulated text reports from computed tomography, magnetic resonance imaging, bone scans, and biopsy pathology on stage IV PC patients. We assessed four LLMs (ChatGPT-4-turbo, Claude-3-opus, Gemini-Pro-1.0, ChatGPT-3.5-turbo) on three RA tasks (LATITUDE, CHAARTED, TwNHI) and seven IR tasks. It included TNM staging, and the detection and quantification of bone and visceral metastases, providing a broad evaluation of their capabilities in handling diverse clinical data. We queried LLMs with multi-modality reports using zero-shot chain-of-thought prompting via application programming interface. With three adjudicators' consensus as the gold standard, these models' performances were assessed through repeated single-round queries and ensemble voting methods, using 6 outcome metrics.</p><p><strong>Results: </strong>Among 350 stage IV PC patients with simulated reports, 115 (32.9%), 128 (36.6%), and 94 (26.9%) belonged to LATITUDE, CHAARTED, and TwNHI high-risk, respectively. Ensemble voting, based on three repeated single-round queries, consistently enhances accuracy with a higher likelihood of achieving non-inferior results compared to a single query. Four models showed minimal differences in IR tasks with high accuracy (87.4%-94.2%) and consistency (ICC>0.8) in TNM staging. However, there were significant differences in RA performance, with the ranking as follows: ChatGPT-4-turbo, Claude-3-opus, Gemini-Pro-1.0, and ChatGPT-3.5-turbo, respectively. ChatGPT-4-turbo achieved the highest accuracy (90.1%, 90.7%,91.6%), and consistency (ICC 0.86, 0.93, 0.76) across 3 RA tasks.</p><p><strong>Conclusions: </strong>ChatGPT-4-turbo demonstrated satisfactory accuracy and outcomes in RA and IR for stage IV PC, suggesting its potential for clinical decision support. However, the risks of misinterpretation impacting decision-making cannot be overlooked. Further research is necessary to validate these findings in other cancers.</p>\",\"PeriodicalId\":54261,\"journal\":{\"name\":\"World Journal of Mens Health\",\"volume\":\" \",\"pages\":\"918-933\"},\"PeriodicalIF\":4.3000,\"publicationDate\":\"2025-10-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12505481/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"World Journal of Mens Health\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.5534/wjmh.240173\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/12/2 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"ANDROLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"World Journal of Mens Health","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.5534/wjmh.240173","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/12/2 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"ANDROLOGY","Score":null,"Total":0}
The In-depth Comparative Analysis of Four Large Language AI Models for Risk Assessment and Information Retrieval from Multi-Modality Prostate Cancer Work-up Reports.
Purpose: Information retrieval (IR) and risk assessment (RA) from multi-modality imaging and pathology reports are critical to prostate cancer (PC) treatment. This study aims to evaluate the performance of four general-purpose large language model (LLMs) in IR and RA tasks.
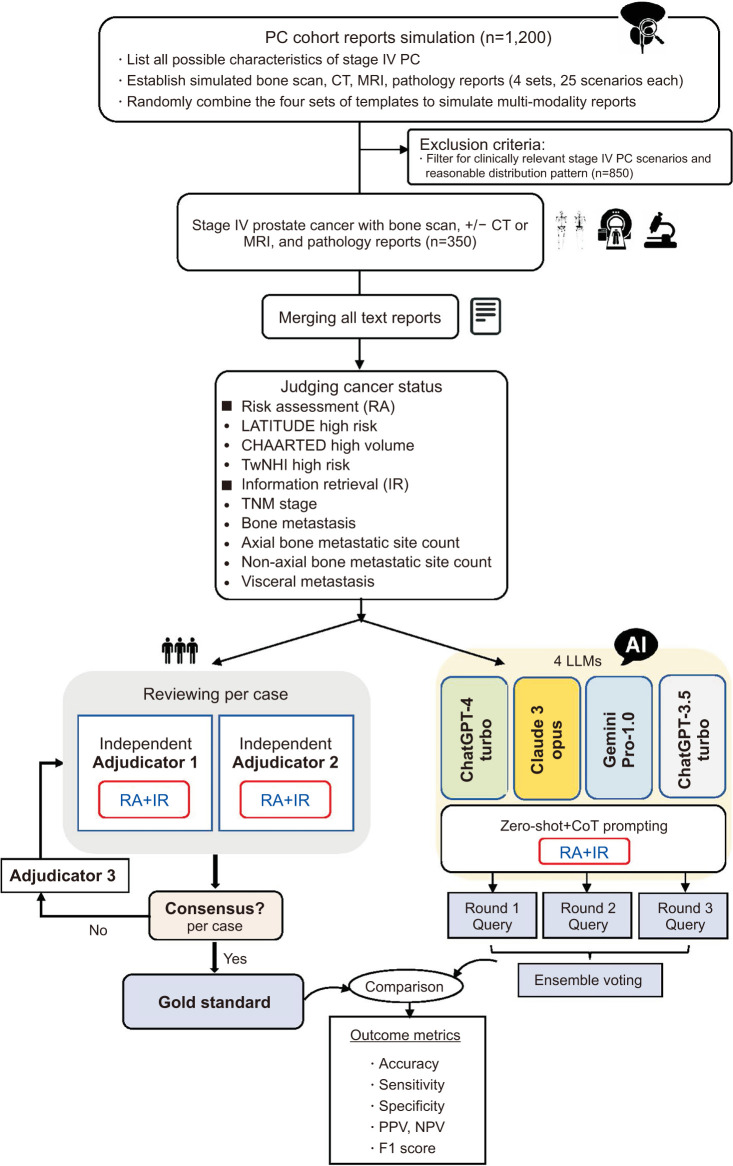
Materials and methods: We conducted a study using simulated text reports from computed tomography, magnetic resonance imaging, bone scans, and biopsy pathology on stage IV PC patients. We assessed four LLMs (ChatGPT-4-turbo, Claude-3-opus, Gemini-Pro-1.0, ChatGPT-3.5-turbo) on three RA tasks (LATITUDE, CHAARTED, TwNHI) and seven IR tasks. It included TNM staging, and the detection and quantification of bone and visceral metastases, providing a broad evaluation of their capabilities in handling diverse clinical data. We queried LLMs with multi-modality reports using zero-shot chain-of-thought prompting via application programming interface. With three adjudicators' consensus as the gold standard, these models' performances were assessed through repeated single-round queries and ensemble voting methods, using 6 outcome metrics.
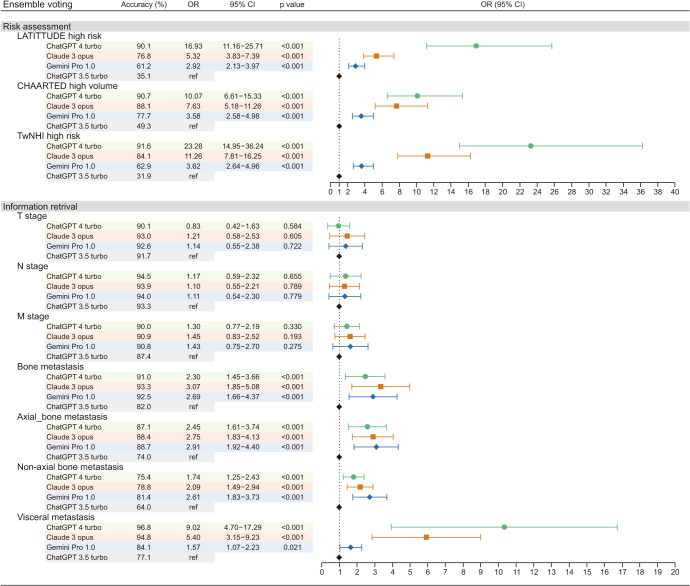
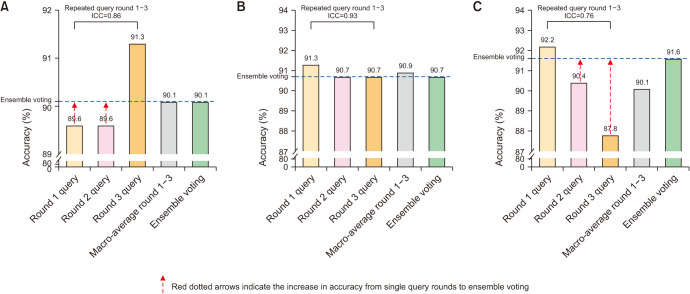
Results: Among 350 stage IV PC patients with simulated reports, 115 (32.9%), 128 (36.6%), and 94 (26.9%) belonged to LATITUDE, CHAARTED, and TwNHI high-risk, respectively. Ensemble voting, based on three repeated single-round queries, consistently enhances accuracy with a higher likelihood of achieving non-inferior results compared to a single query. Four models showed minimal differences in IR tasks with high accuracy (87.4%-94.2%) and consistency (ICC>0.8) in TNM staging. However, there were significant differences in RA performance, with the ranking as follows: ChatGPT-4-turbo, Claude-3-opus, Gemini-Pro-1.0, and ChatGPT-3.5-turbo, respectively. ChatGPT-4-turbo achieved the highest accuracy (90.1%, 90.7%,91.6%), and consistency (ICC 0.86, 0.93, 0.76) across 3 RA tasks.
Conclusions: ChatGPT-4-turbo demonstrated satisfactory accuracy and outcomes in RA and IR for stage IV PC, suggesting its potential for clinical decision support. However, the risks of misinterpretation impacting decision-making cannot be overlooked. Further research is necessary to validate these findings in other cancers.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
