Harrison C Gottlich, Panagiotis Korfiatis, Adriana V Gregory, Timothy L Kline
{"title":"AI in the Loop:功能化折叠性能差异,以监控自动医学图像分割工作流程。","authors":"Harrison C Gottlich, Panagiotis Korfiatis, Adriana V Gregory, Timothy L Kline","doi":"10.3389/fradi.2023.1223294","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Methods that automatically flag poor performing predictions are drastically needed to safely implement machine learning workflows into clinical practice as well as to identify difficult cases during model training.</p><p><strong>Methods: </strong>Disagreement between the fivefold cross-validation sub-models was quantified using dice scores between folds and summarized as a surrogate for model confidence. The summarized Interfold Dices were compared with thresholds informed by human interobserver values to determine whether final ensemble model performance should be manually reviewed.</p><p><strong>Results: </strong>The method on all tasks efficiently flagged poor segmented images without consulting a reference standard. Using the median Interfold Dice for comparison, substantial dice score improvements after excluding flagged images was noted for the in-domain CT (0.85 ± 0.20 to 0.91 ± 0.08, 8/50 images flagged) and MR (0.76 ± 0.27 to 0.85 ± 0.09, 8/50 images flagged). Most impressively, there were dramatic dice score improvements in the simulated out-of-distribution task where the model was trained on a radical nephrectomy dataset with different contrast phases predicting a partial nephrectomy all cortico-medullary phase dataset (0.67 ± 0.36 to 0.89 ± 0.10, 122/300 images flagged).</p><p><strong>Discussion: </strong>Comparing interfold sub-model disagreement against human interobserver values is an effective and efficient way to assess automated predictions when a reference standard is not available. This functionality provides a necessary safeguard to patient care important to safely implement automated medical image segmentation workflows.</p>","PeriodicalId":73101,"journal":{"name":"Frontiers in radiology","volume":"3 ","pages":"1223294"},"PeriodicalIF":0.0000,"publicationDate":"2023-09-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10540615/pdf/","citationCount":"0","resultStr":"{\"title\":\"AI in the Loop: functionalizing fold performance disagreement to monitor automated medical image segmentation workflows.\",\"authors\":\"Harrison C Gottlich, Panagiotis Korfiatis, Adriana V Gregory, Timothy L Kline\",\"doi\":\"10.3389/fradi.2023.1223294\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Methods that automatically flag poor performing predictions are drastically needed to safely implement machine learning workflows into clinical practice as well as to identify difficult cases during model training.</p><p><strong>Methods: </strong>Disagreement between the fivefold cross-validation sub-models was quantified using dice scores between folds and summarized as a surrogate for model confidence. The summarized Interfold Dices were compared with thresholds informed by human interobserver values to determine whether final ensemble model performance should be manually reviewed.</p><p><strong>Results: </strong>The method on all tasks efficiently flagged poor segmented images without consulting a reference standard. Using the median Interfold Dice for comparison, substantial dice score improvements after excluding flagged images was noted for the in-domain CT (0.85 ± 0.20 to 0.91 ± 0.08, 8/50 images flagged) and MR (0.76 ± 0.27 to 0.85 ± 0.09, 8/50 images flagged). Most impressively, there were dramatic dice score improvements in the simulated out-of-distribution task where the model was trained on a radical nephrectomy dataset with different contrast phases predicting a partial nephrectomy all cortico-medullary phase dataset (0.67 ± 0.36 to 0.89 ± 0.10, 122/300 images flagged).</p><p><strong>Discussion: </strong>Comparing interfold sub-model disagreement against human interobserver values is an effective and efficient way to assess automated predictions when a reference standard is not available. This functionality provides a necessary safeguard to patient care important to safely implement automated medical image segmentation workflows.</p>\",\"PeriodicalId\":73101,\"journal\":{\"name\":\"Frontiers in radiology\",\"volume\":\"3 \",\"pages\":\"1223294\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-09-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10540615/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in radiology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3389/fradi.2023.1223294\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in radiology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fradi.2023.1223294","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/1 0:00:00","PubModel":"eCollection","JCR":"","JCRName":"","Score":null,"Total":0}
AI in the Loop: functionalizing fold performance disagreement to monitor automated medical image segmentation workflows.
Introduction: Methods that automatically flag poor performing predictions are drastically needed to safely implement machine learning workflows into clinical practice as well as to identify difficult cases during model training.
Methods: Disagreement between the fivefold cross-validation sub-models was quantified using dice scores between folds and summarized as a surrogate for model confidence. The summarized Interfold Dices were compared with thresholds informed by human interobserver values to determine whether final ensemble model performance should be manually reviewed.
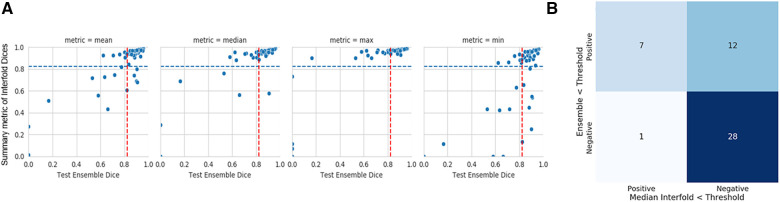
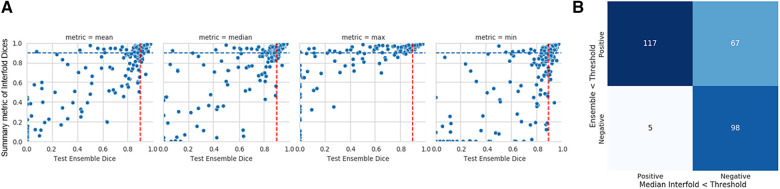
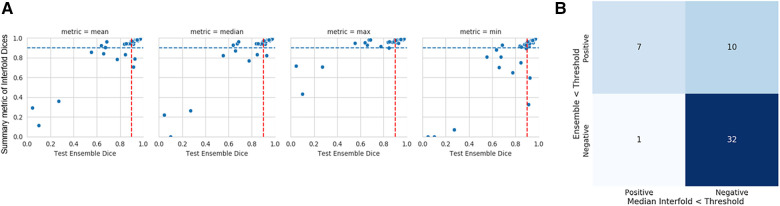
Results: The method on all tasks efficiently flagged poor segmented images without consulting a reference standard. Using the median Interfold Dice for comparison, substantial dice score improvements after excluding flagged images was noted for the in-domain CT (0.85 ± 0.20 to 0.91 ± 0.08, 8/50 images flagged) and MR (0.76 ± 0.27 to 0.85 ± 0.09, 8/50 images flagged). Most impressively, there were dramatic dice score improvements in the simulated out-of-distribution task where the model was trained on a radical nephrectomy dataset with different contrast phases predicting a partial nephrectomy all cortico-medullary phase dataset (0.67 ± 0.36 to 0.89 ± 0.10, 122/300 images flagged).
Discussion: Comparing interfold sub-model disagreement against human interobserver values is an effective and efficient way to assess automated predictions when a reference standard is not available. This functionality provides a necessary safeguard to patient care important to safely implement automated medical image segmentation workflows.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
