Chia-Hung Lin, Hsiang-Yueh Lai, Ping-Tzan Huang, Pi-Yun Chen, Chien-Ming Li
{"title":"结合音高检测和基于一维卷积神经网络的性别识别分类器的元音分类","authors":"Chia-Hung Lin, Hsiang-Yueh Lai, Ping-Tzan Huang, Pi-Yun Chen, Chien-Ming Li","doi":"10.1049/sil2.12216","DOIUrl":null,"url":null,"abstract":"<p>Human speech signals may contain specific information regarding a speaker's characteristics, and these signals can be very useful in applications involving interactive voice response (IVR) and automatic speech recognition (ASR). For IVR and ASR applications, speaker classification into different ages and gender groups can be applied in human–machine interaction or computer-based interaction systems for customised advertisement, translation (text generation), machine dialog systems, or self-service applications. Hence, an IVR-based system dictates that ASR should function through users' voices (specific voice-frequency bands) to identify customers' age and gender and interact with a host system. In the present study, we intended to combine a pitch detection (PD)-based extractor and a voice classifier for gender identification. The Yet Another Algorithm for Pitch Tracking (YAAPT)-based PD method was designed to extract the voice fundamental frequency (F<sub>0</sub>) from non-stationary speaker's voice signals, allowing us to achieve gender identification, by distinguishing differences in F<sub>0</sub> between adult females and males, and classify voices into adult and children groups. Then, in vowel voice signal classification, a one-dimensional (1D) convolutional neural network (CNN), consisted of a multi-round 1D kernel convolutional layer, a 1D pooling process, and a vowel classifier that could preliminary divide feature patterns into three level ranges of F<sub>0</sub>, including adult and children groups. Consequently, a classifier was used in the classification layer to identify the speakers' gender. The proposed PD-based extractor and voice classifier could reduce complexity and improve classification efficiency. Acoustic datasets were selected from the Hillenbrand database for experimental tests on 12 vowels classifications, and K-fold cross-validations were performed. The experimental results demonstrated that our approach is a very promising method to quantify the proposed classifier's performance in terms of recall (%), precision (%), accuracy (%), and F1 score.</p>","PeriodicalId":56301,"journal":{"name":"IET Signal Processing","volume":"17 5","pages":""},"PeriodicalIF":1.4000,"publicationDate":"2023-05-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/sil2.12216","citationCount":"0","resultStr":"{\"title\":\"Vowel classification with combining pitch detection and one-dimensional convolutional neural network based classifier for gender identification\",\"authors\":\"Chia-Hung Lin, Hsiang-Yueh Lai, Ping-Tzan Huang, Pi-Yun Chen, Chien-Ming Li\",\"doi\":\"10.1049/sil2.12216\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Human speech signals may contain specific information regarding a speaker's characteristics, and these signals can be very useful in applications involving interactive voice response (IVR) and automatic speech recognition (ASR). For IVR and ASR applications, speaker classification into different ages and gender groups can be applied in human–machine interaction or computer-based interaction systems for customised advertisement, translation (text generation), machine dialog systems, or self-service applications. Hence, an IVR-based system dictates that ASR should function through users' voices (specific voice-frequency bands) to identify customers' age and gender and interact with a host system. In the present study, we intended to combine a pitch detection (PD)-based extractor and a voice classifier for gender identification. The Yet Another Algorithm for Pitch Tracking (YAAPT)-based PD method was designed to extract the voice fundamental frequency (F<sub>0</sub>) from non-stationary speaker's voice signals, allowing us to achieve gender identification, by distinguishing differences in F<sub>0</sub> between adult females and males, and classify voices into adult and children groups. Then, in vowel voice signal classification, a one-dimensional (1D) convolutional neural network (CNN), consisted of a multi-round 1D kernel convolutional layer, a 1D pooling process, and a vowel classifier that could preliminary divide feature patterns into three level ranges of F<sub>0</sub>, including adult and children groups. Consequently, a classifier was used in the classification layer to identify the speakers' gender. The proposed PD-based extractor and voice classifier could reduce complexity and improve classification efficiency. Acoustic datasets were selected from the Hillenbrand database for experimental tests on 12 vowels classifications, and K-fold cross-validations were performed. The experimental results demonstrated that our approach is a very promising method to quantify the proposed classifier's performance in terms of recall (%), precision (%), accuracy (%), and F1 score.</p>\",\"PeriodicalId\":56301,\"journal\":{\"name\":\"IET Signal Processing\",\"volume\":\"17 5\",\"pages\":\"\"},\"PeriodicalIF\":1.4000,\"publicationDate\":\"2023-05-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1049/sil2.12216\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"IET Signal Processing\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1049/sil2.12216\",\"RegionNum\":4,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"ENGINEERING, ELECTRICAL & ELECTRONIC\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Signal Processing","FirstCategoryId":"5","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/sil2.12216","RegionNum":4,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"ENGINEERING, ELECTRICAL & ELECTRONIC","Score":null,"Total":0}
引用次数: 0
摘要
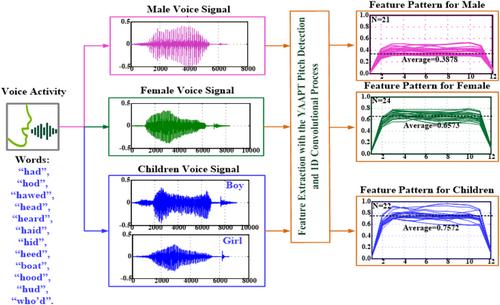
人类语音信号可能包含有关说话人特征的特定信息,这些信号在涉及交互式语音应答(IVR)和自动语音识别(ASR)的应用中非常有用。对于IVR和ASR应用,不同年龄和性别的说话人分类可以应用于人机交互或基于计算机的交互系统中,用于定制广告、翻译(文本生成)、机器对话系统或自助服务应用。因此,基于ivr的系统要求ASR应该通过用户的声音(特定的语音频段)来识别客户的年龄和性别,并与主机系统进行交互。在本研究中,我们打算结合一个基于音高检测(PD)的提取器和一个用于性别识别的语音分类器。基于YAAPT (Yet Another Algorithm for Pitch Tracking)的PD方法从非静止说话人的语音信号中提取语音基频(F0),通过区分成年女性和男性的F0差异实现性别识别,并将声音分为成人和儿童两类。然后,在元音语音信号分类中,一维(1D)卷积神经网络(CNN)由多轮一维卷积核层、一维池化过程和元音分类器组成,该分类器可以初步将特征模式划分为F0三个级别范围,包括成人和儿童组。因此,在分类层中使用分类器来识别说话人的性别。提出的基于pd的提取器和语音分类器可以降低复杂度,提高分类效率。从Hillenbrand数据库中选择声学数据集对12个元音分类进行实验测试,并进行K-fold交叉验证。实验结果表明,我们的方法是一种非常有前途的方法,可以从召回率(%)、精度(%)、准确度(%)和F1分数等方面量化所提出的分类器的性能。
Vowel classification with combining pitch detection and one-dimensional convolutional neural network based classifier for gender identification
Human speech signals may contain specific information regarding a speaker's characteristics, and these signals can be very useful in applications involving interactive voice response (IVR) and automatic speech recognition (ASR). For IVR and ASR applications, speaker classification into different ages and gender groups can be applied in human–machine interaction or computer-based interaction systems for customised advertisement, translation (text generation), machine dialog systems, or self-service applications. Hence, an IVR-based system dictates that ASR should function through users' voices (specific voice-frequency bands) to identify customers' age and gender and interact with a host system. In the present study, we intended to combine a pitch detection (PD)-based extractor and a voice classifier for gender identification. The Yet Another Algorithm for Pitch Tracking (YAAPT)-based PD method was designed to extract the voice fundamental frequency (F0) from non-stationary speaker's voice signals, allowing us to achieve gender identification, by distinguishing differences in F0 between adult females and males, and classify voices into adult and children groups. Then, in vowel voice signal classification, a one-dimensional (1D) convolutional neural network (CNN), consisted of a multi-round 1D kernel convolutional layer, a 1D pooling process, and a vowel classifier that could preliminary divide feature patterns into three level ranges of F0, including adult and children groups. Consequently, a classifier was used in the classification layer to identify the speakers' gender. The proposed PD-based extractor and voice classifier could reduce complexity and improve classification efficiency. Acoustic datasets were selected from the Hillenbrand database for experimental tests on 12 vowels classifications, and K-fold cross-validations were performed. The experimental results demonstrated that our approach is a very promising method to quantify the proposed classifier's performance in terms of recall (%), precision (%), accuracy (%), and F1 score.
期刊介绍:
IET Signal Processing publishes research on a diverse range of signal processing and machine learning topics, covering a variety of applications, disciplines, modalities, and techniques in detection, estimation, inference, and classification problems. The research published includes advances in algorithm design for the analysis of single and high-multi-dimensional data, sparsity, linear and non-linear systems, recursive and non-recursive digital filters and multi-rate filter banks, as well a range of topics that span from sensor array processing, deep convolutional neural network based approaches to the application of chaos theory, and far more.
Topics covered by scope include, but are not limited to:
advances in single and multi-dimensional filter design and implementation
linear and nonlinear, fixed and adaptive digital filters and multirate filter banks
statistical signal processing techniques and analysis
classical, parametric and higher order spectral analysis
signal transformation and compression techniques, including time-frequency analysis
system modelling and adaptive identification techniques
machine learning based approaches to signal processing
Bayesian methods for signal processing, including Monte-Carlo Markov-chain and particle filtering techniques
theory and application of blind and semi-blind signal separation techniques
signal processing techniques for analysis, enhancement, coding, synthesis and recognition of speech signals
direction-finding and beamforming techniques for audio and electromagnetic signals
analysis techniques for biomedical signals
baseband signal processing techniques for transmission and reception of communication signals
signal processing techniques for data hiding and audio watermarking
sparse signal processing and compressive sensing
Special Issue Call for Papers:
Intelligent Deep Fuzzy Model for Signal Processing - https://digital-library.theiet.org/files/IET_SPR_CFP_IDFMSP.pdf



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
