{"title":"讨论:在可靠性应用中指定先验分布","authors":"Richard Arnold","doi":"10.1002/asmb.2791","DOIUrl":null,"url":null,"abstract":"<p>This interesting paper by Tian et al. presents a comprehensive investigation of non-informative and weakly informative priors for two parameter (log-location and scale) failure distributions. They provide helpful and practical advice to the Bayesian analyst on the selection of appropriate priors and specifically on the avoidance of posterior estimates that are unrealistic, particularly where data are sparse.</p><p>The motivating examples provide challenging settings where the information provided by the data is extremely slight. These settings are typical of systems engineered to be very high reliable, where failure data are minimal by design, but where inferences about failure risk are critical. These are also precisely the settings where default choices for noninformative priors may be unexpectedly influential,<span><sup>1</sup></span> leading either to improper posteriors, or to posteriors which place significant mass in regions which are implausible. The authors' fundamental principle (§5.4) of ensuring that the priors always be constructed to avoid this consequence is very well stated, and one which will bear much repetition in other forums.</p><p>We have only one main point to make. It relates to their statement in the abstract that ‘for Bayesian inference, there is only one method of constructing equal-tailed credible intervals—but it is necesssary to provide a prior distribution to full specify the model.’ We agree, but our view is that the statement is incomplete: the <b>model</b> must have been chosen to begin with. Although this is not the main point of the paper, the consequences of model choice can be considerable, particularly when all of the inferential action is being carried out on the tails of the distribution, where only a few percent of failures may ever be observed to occur.</p><p>In this spirit we have reproduced in our Figure 1 the authors' Weibull probability plot (their Figure 1) of the Bearing Cage failure data.<span><sup>2</sup></span> The estimated parameters of the original Weibull fit are <math>\n <semantics>\n <mrow>\n <mo>(</mo>\n <mover>\n <mrow>\n <mi>β</mi>\n </mrow>\n <mo>^</mo>\n </mover>\n <mo>,</mo>\n <mover>\n <mrow>\n <mi>η</mi>\n </mrow>\n <mo>^</mo>\n </mover>\n <mo>)</mo>\n <mo>=</mo>\n <mo>(</mo>\n <mn>2</mn>\n <mo>.</mo>\n <mn>035</mn>\n <mo>,</mo>\n <mn>11792</mn>\n <mo>)</mo>\n </mrow>\n <annotation>$$ \\left(\\hat{\\beta},\\hat{\\eta}\\right)=\\left(2.035,11792\\right) $$</annotation>\n </semantics></math>, and we show that fitted cumulative distribution function with a solid line. Choosing the tail areas <math>\n <semantics>\n <mrow>\n <mi>p</mi>\n <mo>=</mo>\n <mn>0</mn>\n <mo>.</mo>\n <mn>1</mn>\n </mrow>\n <annotation>$$ p=0.1 $$</annotation>\n </semantics></math> and <math>\n <semantics>\n <mrow>\n <mi>q</mi>\n <mo>=</mo>\n <mn>0</mn>\n <mo>.</mo>\n <mn>005</mn>\n </mrow>\n <annotation>$$ q=0.005 $$</annotation>\n </semantics></math> these correspond to the parameter values <math>\n <semantics>\n <mrow>\n <mo>(</mo>\n <msub>\n <mrow>\n <mover>\n <mrow>\n <mi>t</mi>\n </mrow>\n <mo>^</mo>\n </mover>\n </mrow>\n <mrow>\n <mi>p</mi>\n </mrow>\n </msub>\n <mo>,</mo>\n <msub>\n <mrow>\n <mover>\n <mrow>\n <mi>λ</mi>\n </mrow>\n <mo>^</mo>\n </mover>\n </mrow>\n <mrow>\n <mi>q</mi>\n </mrow>\n </msub>\n <mo>)</mo>\n <mo>=</mo>\n <mo>(</mo>\n <mn>3902</mn>\n <mo>,</mo>\n <mn>0</mn>\n <mo>.</mo>\n <mn>224</mn>\n <mo>)</mo>\n </mrow>\n <annotation>$$ \\left({\\hat{t}}_p,{\\hat{\\lambda}}_q\\right)=\\left(3902,0.224\\right) $$</annotation>\n </semantics></math>, and we have drawn horizontal dashed lines corresponding to <math>\n <semantics>\n <mrow>\n <mi>p</mi>\n </mrow>\n <annotation>$$ p $$</annotation>\n </semantics></math> and <math>\n <semantics>\n <mrow>\n <mi>q</mi>\n </mrow>\n <annotation>$$ q $$</annotation>\n </semantics></math>. A vertical line at <math>\n <semantics>\n <mrow>\n <mi>t</mi>\n <mo>=</mo>\n <mn>8000</mn>\n </mrow>\n <annotation>$$ t=8000 $$</annotation>\n </semantics></math> h marks a key point of inferential interest. We have also shown cumulative distributions of a log Normal and a Gamma distribution with matching values of <math>\n <semantics>\n <mrow>\n <mo>(</mo>\n <msub>\n <mrow>\n <mi>t</mi>\n </mrow>\n <mrow>\n <mi>p</mi>\n </mrow>\n </msub>\n <mo>,</mo>\n <msub>\n <mrow>\n <mi>λ</mi>\n </mrow>\n <mrow>\n <mi>q</mi>\n </mrow>\n </msub>\n <mo>)</mo>\n </mrow>\n <annotation>$$ \\left({t}_p,{\\lambda}_q\\right) $$</annotation>\n </semantics></math>.</p><p>The tail shapes do of course differ somewhat from one another, the log Normal most markedly. Inference about the 8000 hour point is necessarily affected not only by the choice of prior but also by the choice of model.</p><p>A paper discussing model selection would have been a rather different one than the current work by Tian et al. Nevertheless we raise the question of whether, if the focus is predominantly on the lower tail of the distribution, a suitable choice of prior on top of a single assumed likelihood be able to do some of the same heavy lifting as a prior on the space of models. Moreover, a prior on <math>\n <semantics>\n <mrow>\n <mo>(</mo>\n <msub>\n <mrow>\n <mi>t</mi>\n </mrow>\n <mrow>\n <mi>p</mi>\n </mrow>\n </msub>\n <mo>,</mo>\n <msub>\n <mrow>\n <mi>λ</mi>\n </mrow>\n <mrow>\n <mi>q</mi>\n </mrow>\n </msub>\n <mo>)</mo>\n </mrow>\n <annotation>$$ \\left({t}_p,{\\lambda}_q\\right) $$</annotation>\n </semantics></math> might yield further advantages in elicitation – given that the large scale parameter <math>\n <semantics>\n <mrow>\n <mi>σ</mi>\n </mrow>\n <annotation>$$ \\sigma $$</annotation>\n </semantics></math> is presumably harder to characterise then a second quantile <math>\n <semantics>\n <mrow>\n <mi>q</mi>\n </mrow>\n <annotation>$$ q $$</annotation>\n </semantics></math> would be. Even if this proves difficult, future work might helpfully incorporate comments and guidance on model selection.</p><p>In conclusion, we thank the authors for their comprehensive treatment of the question of prior specification, and the practical guidance they provide.</p>","PeriodicalId":55495,"journal":{"name":"Applied Stochastic Models in Business and Industry","volume":"40 1","pages":"89-91"},"PeriodicalIF":1.5000,"publicationDate":"2023-06-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/asmb.2791","citationCount":"0","resultStr":"{\"title\":\"Discussion of: Specifying prior distributions in reliability applications\",\"authors\":\"Richard Arnold\",\"doi\":\"10.1002/asmb.2791\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>This interesting paper by Tian et al. presents a comprehensive investigation of non-informative and weakly informative priors for two parameter (log-location and scale) failure distributions. They provide helpful and practical advice to the Bayesian analyst on the selection of appropriate priors and specifically on the avoidance of posterior estimates that are unrealistic, particularly where data are sparse.</p><p>The motivating examples provide challenging settings where the information provided by the data is extremely slight. These settings are typical of systems engineered to be very high reliable, where failure data are minimal by design, but where inferences about failure risk are critical. These are also precisely the settings where default choices for noninformative priors may be unexpectedly influential,<span><sup>1</sup></span> leading either to improper posteriors, or to posteriors which place significant mass in regions which are implausible. The authors' fundamental principle (§5.4) of ensuring that the priors always be constructed to avoid this consequence is very well stated, and one which will bear much repetition in other forums.</p><p>We have only one main point to make. It relates to their statement in the abstract that ‘for Bayesian inference, there is only one method of constructing equal-tailed credible intervals—but it is necesssary to provide a prior distribution to full specify the model.’ We agree, but our view is that the statement is incomplete: the <b>model</b> must have been chosen to begin with. Although this is not the main point of the paper, the consequences of model choice can be considerable, particularly when all of the inferential action is being carried out on the tails of the distribution, where only a few percent of failures may ever be observed to occur.</p><p>In this spirit we have reproduced in our Figure 1 the authors' Weibull probability plot (their Figure 1) of the Bearing Cage failure data.<span><sup>2</sup></span> The estimated parameters of the original Weibull fit are <math>\\n <semantics>\\n <mrow>\\n <mo>(</mo>\\n <mover>\\n <mrow>\\n <mi>β</mi>\\n </mrow>\\n <mo>^</mo>\\n </mover>\\n <mo>,</mo>\\n <mover>\\n <mrow>\\n <mi>η</mi>\\n </mrow>\\n <mo>^</mo>\\n </mover>\\n <mo>)</mo>\\n <mo>=</mo>\\n <mo>(</mo>\\n <mn>2</mn>\\n <mo>.</mo>\\n <mn>035</mn>\\n <mo>,</mo>\\n <mn>11792</mn>\\n <mo>)</mo>\\n </mrow>\\n <annotation>$$ \\\\left(\\\\hat{\\\\beta},\\\\hat{\\\\eta}\\\\right)=\\\\left(2.035,11792\\\\right) $$</annotation>\\n </semantics></math>, and we show that fitted cumulative distribution function with a solid line. Choosing the tail areas <math>\\n <semantics>\\n <mrow>\\n <mi>p</mi>\\n <mo>=</mo>\\n <mn>0</mn>\\n <mo>.</mo>\\n <mn>1</mn>\\n </mrow>\\n <annotation>$$ p=0.1 $$</annotation>\\n </semantics></math> and <math>\\n <semantics>\\n <mrow>\\n <mi>q</mi>\\n <mo>=</mo>\\n <mn>0</mn>\\n <mo>.</mo>\\n <mn>005</mn>\\n </mrow>\\n <annotation>$$ q=0.005 $$</annotation>\\n </semantics></math> these correspond to the parameter values <math>\\n <semantics>\\n <mrow>\\n <mo>(</mo>\\n <msub>\\n <mrow>\\n <mover>\\n <mrow>\\n <mi>t</mi>\\n </mrow>\\n <mo>^</mo>\\n </mover>\\n </mrow>\\n <mrow>\\n <mi>p</mi>\\n </mrow>\\n </msub>\\n <mo>,</mo>\\n <msub>\\n <mrow>\\n <mover>\\n <mrow>\\n <mi>λ</mi>\\n </mrow>\\n <mo>^</mo>\\n </mover>\\n </mrow>\\n <mrow>\\n <mi>q</mi>\\n </mrow>\\n </msub>\\n <mo>)</mo>\\n <mo>=</mo>\\n <mo>(</mo>\\n <mn>3902</mn>\\n <mo>,</mo>\\n <mn>0</mn>\\n <mo>.</mo>\\n <mn>224</mn>\\n <mo>)</mo>\\n </mrow>\\n <annotation>$$ \\\\left({\\\\hat{t}}_p,{\\\\hat{\\\\lambda}}_q\\\\right)=\\\\left(3902,0.224\\\\right) $$</annotation>\\n </semantics></math>, and we have drawn horizontal dashed lines corresponding to <math>\\n <semantics>\\n <mrow>\\n <mi>p</mi>\\n </mrow>\\n <annotation>$$ p $$</annotation>\\n </semantics></math> and <math>\\n <semantics>\\n <mrow>\\n <mi>q</mi>\\n </mrow>\\n <annotation>$$ q $$</annotation>\\n </semantics></math>. A vertical line at <math>\\n <semantics>\\n <mrow>\\n <mi>t</mi>\\n <mo>=</mo>\\n <mn>8000</mn>\\n </mrow>\\n <annotation>$$ t=8000 $$</annotation>\\n </semantics></math> h marks a key point of inferential interest. We have also shown cumulative distributions of a log Normal and a Gamma distribution with matching values of <math>\\n <semantics>\\n <mrow>\\n <mo>(</mo>\\n <msub>\\n <mrow>\\n <mi>t</mi>\\n </mrow>\\n <mrow>\\n <mi>p</mi>\\n </mrow>\\n </msub>\\n <mo>,</mo>\\n <msub>\\n <mrow>\\n <mi>λ</mi>\\n </mrow>\\n <mrow>\\n <mi>q</mi>\\n </mrow>\\n </msub>\\n <mo>)</mo>\\n </mrow>\\n <annotation>$$ \\\\left({t}_p,{\\\\lambda}_q\\\\right) $$</annotation>\\n </semantics></math>.</p><p>The tail shapes do of course differ somewhat from one another, the log Normal most markedly. Inference about the 8000 hour point is necessarily affected not only by the choice of prior but also by the choice of model.</p><p>A paper discussing model selection would have been a rather different one than the current work by Tian et al. Nevertheless we raise the question of whether, if the focus is predominantly on the lower tail of the distribution, a suitable choice of prior on top of a single assumed likelihood be able to do some of the same heavy lifting as a prior on the space of models. Moreover, a prior on <math>\\n <semantics>\\n <mrow>\\n <mo>(</mo>\\n <msub>\\n <mrow>\\n <mi>t</mi>\\n </mrow>\\n <mrow>\\n <mi>p</mi>\\n </mrow>\\n </msub>\\n <mo>,</mo>\\n <msub>\\n <mrow>\\n <mi>λ</mi>\\n </mrow>\\n <mrow>\\n <mi>q</mi>\\n </mrow>\\n </msub>\\n <mo>)</mo>\\n </mrow>\\n <annotation>$$ \\\\left({t}_p,{\\\\lambda}_q\\\\right) $$</annotation>\\n </semantics></math> might yield further advantages in elicitation – given that the large scale parameter <math>\\n <semantics>\\n <mrow>\\n <mi>σ</mi>\\n </mrow>\\n <annotation>$$ \\\\sigma $$</annotation>\\n </semantics></math> is presumably harder to characterise then a second quantile <math>\\n <semantics>\\n <mrow>\\n <mi>q</mi>\\n </mrow>\\n <annotation>$$ q $$</annotation>\\n </semantics></math> would be. Even if this proves difficult, future work might helpfully incorporate comments and guidance on model selection.</p><p>In conclusion, we thank the authors for their comprehensive treatment of the question of prior specification, and the practical guidance they provide.</p>\",\"PeriodicalId\":55495,\"journal\":{\"name\":\"Applied Stochastic Models in Business and Industry\",\"volume\":\"40 1\",\"pages\":\"89-91\"},\"PeriodicalIF\":1.5000,\"publicationDate\":\"2023-06-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/asmb.2791\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Applied Stochastic Models in Business and Industry\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/asmb.2791\",\"RegionNum\":4,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applied Stochastic Models in Business and Industry","FirstCategoryId":"100","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/asmb.2791","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
摘要
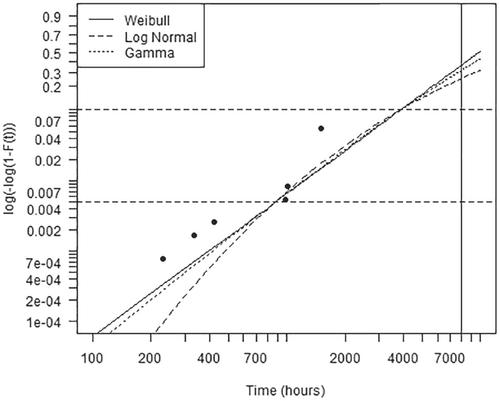
我们还展示了对数正态分布和伽马分布的累积分布,它们的匹配值为 ( t p , λ q ) $$ \left({t}_p,{\lambda}_q\right) $$。当然,它们的尾部形状有些不同,对数正态分布的尾部形状最为明显。尽管如此,我们还是提出了这样一个问题:如果重点主要放在分布的低尾部,那么在单一假定可能性的基础上选择一个合适的先验值,是否能够像在模型空间上选择先验值一样,完成一些繁重的工作?此外,关于 ( t p , λ q ) $$ \left({t}_p,{\lambda}_q\right) $$ 的先验值可能会在诱导中产生进一步的优势--考虑到大尺度参数 σ $$ \sigma $$ 可能比第二量级 q $$ q $$ 更难描述。总之,我们感谢作者们对先验规范问题的全面处理,以及他们提供的实际指导。
Discussion of: Specifying prior distributions in reliability applications
This interesting paper by Tian et al. presents a comprehensive investigation of non-informative and weakly informative priors for two parameter (log-location and scale) failure distributions. They provide helpful and practical advice to the Bayesian analyst on the selection of appropriate priors and specifically on the avoidance of posterior estimates that are unrealistic, particularly where data are sparse.
The motivating examples provide challenging settings where the information provided by the data is extremely slight. These settings are typical of systems engineered to be very high reliable, where failure data are minimal by design, but where inferences about failure risk are critical. These are also precisely the settings where default choices for noninformative priors may be unexpectedly influential,1 leading either to improper posteriors, or to posteriors which place significant mass in regions which are implausible. The authors' fundamental principle (§5.4) of ensuring that the priors always be constructed to avoid this consequence is very well stated, and one which will bear much repetition in other forums.
We have only one main point to make. It relates to their statement in the abstract that ‘for Bayesian inference, there is only one method of constructing equal-tailed credible intervals—but it is necesssary to provide a prior distribution to full specify the model.’ We agree, but our view is that the statement is incomplete: the model must have been chosen to begin with. Although this is not the main point of the paper, the consequences of model choice can be considerable, particularly when all of the inferential action is being carried out on the tails of the distribution, where only a few percent of failures may ever be observed to occur.
In this spirit we have reproduced in our Figure 1 the authors' Weibull probability plot (their Figure 1) of the Bearing Cage failure data.2 The estimated parameters of the original Weibull fit are , and we show that fitted cumulative distribution function with a solid line. Choosing the tail areas and these correspond to the parameter values , and we have drawn horizontal dashed lines corresponding to and . A vertical line at h marks a key point of inferential interest. We have also shown cumulative distributions of a log Normal and a Gamma distribution with matching values of .
The tail shapes do of course differ somewhat from one another, the log Normal most markedly. Inference about the 8000 hour point is necessarily affected not only by the choice of prior but also by the choice of model.
A paper discussing model selection would have been a rather different one than the current work by Tian et al. Nevertheless we raise the question of whether, if the focus is predominantly on the lower tail of the distribution, a suitable choice of prior on top of a single assumed likelihood be able to do some of the same heavy lifting as a prior on the space of models. Moreover, a prior on might yield further advantages in elicitation – given that the large scale parameter is presumably harder to characterise then a second quantile would be. Even if this proves difficult, future work might helpfully incorporate comments and guidance on model selection.
In conclusion, we thank the authors for their comprehensive treatment of the question of prior specification, and the practical guidance they provide.
期刊介绍:
ASMBI - Applied Stochastic Models in Business and Industry (formerly Applied Stochastic Models and Data Analysis) was first published in 1985, publishing contributions in the interface between stochastic modelling, data analysis and their applications in business, finance, insurance, management and production. In 2007 ASMBI became the official journal of the International Society for Business and Industrial Statistics (www.isbis.org). The main objective is to publish papers, both technical and practical, presenting new results which solve real-life problems or have great potential in doing so. Mathematical rigour, innovative stochastic modelling and sound applications are the key ingredients of papers to be published, after a very selective review process.
The journal is very open to new ideas, like Data Science and Big Data stemming from problems in business and industry or uncertainty quantification in engineering, as well as more traditional ones, like reliability, quality control, design of experiments, managerial processes, supply chains and inventories, insurance, econometrics, financial modelling (provided the papers are related to real problems). The journal is interested also in papers addressing the effects of business and industrial decisions on the environment, healthcare, social life. State-of-the art computational methods are very welcome as well, when combined with sound applications and innovative models.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
