{"title":"小区域贫困指标估计的多元混合模型","authors":"Agne Bikauskaite, Isabel Molina, Domingo Morales","doi":"10.1111/rssa.12965","DOIUrl":null,"url":null,"abstract":"<p>When disaggregation of national estimates in several domains or areas is required, direct survey estimators, which use only the domain-specific survey data, are usually design-unbiased even under complex survey designs (at least approximately) and require no model assumptions. Nevertheless, they are appropriate only for domains or areas with sufficiently large sample size. For example, when estimating poverty in a domain with a small sample size (small area), the volatility of a direct estimator might make that area seems like very poor in one period and very rich in the next one. Small area (or indirect) estimators have been developed in order to avoid such undesired instability. Small area estimators borrow strength from the other areas so as to improve the precision and therefore obtain much more stable estimators. However, the usual model-based assumptions, which include some kind of area homogeneity, may not hold in real applications. A more flexible model based on multivariate mixtures of normal distributions that generalises the usual nested error linear regression model is proposed for estimation of general parameters in small areas. This flexibility makes the model adaptable to more general situations, where there may be areas with a different behaviour from the other ones, making the model less restrictive (hence, more close to nonparametric) and more robust to outlying areas. An expectation-maximisation (E-M) method is designed for fitting the proposed mixture model. Under the proposed mixture model, two different new predictors of general small area indicators are proposed. A parametric bootstrap method is used to estimate the mean squared errors of the proposed predictors. Small sample properties of the new predictors and of the bootstrap procedure are analysed by simulation studies and the new methodology is illustrated with an application to poverty mapping in Palestine.</p>","PeriodicalId":49983,"journal":{"name":"Journal of the Royal Statistical Society Series A-Statistics in Society","volume":"185 S2","pages":"S724-S755"},"PeriodicalIF":1.6000,"publicationDate":"2022-12-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://rss.onlinelibrary.wiley.com/doi/epdf/10.1111/rssa.12965","citationCount":"1","resultStr":"{\"title\":\"Multivariate mixture model for small area estimation of poverty indicators\",\"authors\":\"Agne Bikauskaite, Isabel Molina, Domingo Morales\",\"doi\":\"10.1111/rssa.12965\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>When disaggregation of national estimates in several domains or areas is required, direct survey estimators, which use only the domain-specific survey data, are usually design-unbiased even under complex survey designs (at least approximately) and require no model assumptions. Nevertheless, they are appropriate only for domains or areas with sufficiently large sample size. For example, when estimating poverty in a domain with a small sample size (small area), the volatility of a direct estimator might make that area seems like very poor in one period and very rich in the next one. Small area (or indirect) estimators have been developed in order to avoid such undesired instability. Small area estimators borrow strength from the other areas so as to improve the precision and therefore obtain much more stable estimators. However, the usual model-based assumptions, which include some kind of area homogeneity, may not hold in real applications. A more flexible model based on multivariate mixtures of normal distributions that generalises the usual nested error linear regression model is proposed for estimation of general parameters in small areas. This flexibility makes the model adaptable to more general situations, where there may be areas with a different behaviour from the other ones, making the model less restrictive (hence, more close to nonparametric) and more robust to outlying areas. An expectation-maximisation (E-M) method is designed for fitting the proposed mixture model. Under the proposed mixture model, two different new predictors of general small area indicators are proposed. A parametric bootstrap method is used to estimate the mean squared errors of the proposed predictors. Small sample properties of the new predictors and of the bootstrap procedure are analysed by simulation studies and the new methodology is illustrated with an application to poverty mapping in Palestine.</p>\",\"PeriodicalId\":49983,\"journal\":{\"name\":\"Journal of the Royal Statistical Society Series A-Statistics in Society\",\"volume\":\"185 S2\",\"pages\":\"S724-S755\"},\"PeriodicalIF\":1.6000,\"publicationDate\":\"2022-12-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://rss.onlinelibrary.wiley.com/doi/epdf/10.1111/rssa.12965\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of the Royal Statistical Society Series A-Statistics in Society\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/rssa.12965\",\"RegionNum\":3,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"SOCIAL SCIENCES, MATHEMATICAL METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of the Royal Statistical Society Series A-Statistics in Society","FirstCategoryId":"100","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/rssa.12965","RegionNum":3,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"SOCIAL SCIENCES, MATHEMATICAL METHODS","Score":null,"Total":0}
Multivariate mixture model for small area estimation of poverty indicators
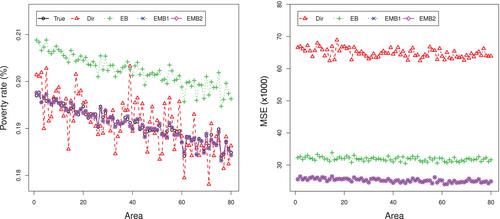
When disaggregation of national estimates in several domains or areas is required, direct survey estimators, which use only the domain-specific survey data, are usually design-unbiased even under complex survey designs (at least approximately) and require no model assumptions. Nevertheless, they are appropriate only for domains or areas with sufficiently large sample size. For example, when estimating poverty in a domain with a small sample size (small area), the volatility of a direct estimator might make that area seems like very poor in one period and very rich in the next one. Small area (or indirect) estimators have been developed in order to avoid such undesired instability. Small area estimators borrow strength from the other areas so as to improve the precision and therefore obtain much more stable estimators. However, the usual model-based assumptions, which include some kind of area homogeneity, may not hold in real applications. A more flexible model based on multivariate mixtures of normal distributions that generalises the usual nested error linear regression model is proposed for estimation of general parameters in small areas. This flexibility makes the model adaptable to more general situations, where there may be areas with a different behaviour from the other ones, making the model less restrictive (hence, more close to nonparametric) and more robust to outlying areas. An expectation-maximisation (E-M) method is designed for fitting the proposed mixture model. Under the proposed mixture model, two different new predictors of general small area indicators are proposed. A parametric bootstrap method is used to estimate the mean squared errors of the proposed predictors. Small sample properties of the new predictors and of the bootstrap procedure are analysed by simulation studies and the new methodology is illustrated with an application to poverty mapping in Palestine.
期刊介绍:
Series A (Statistics in Society) publishes high quality papers that demonstrate how statistical thinking, design and analyses play a vital role in all walks of life and benefit society in general. There is no restriction on subject-matter: any interesting, topical and revelatory applications of statistics are welcome. For example, important applications of statistical and related data science methodology in medicine, business and commerce, industry, economics and finance, education and teaching, physical and biomedical sciences, the environment, the law, government and politics, demography, psychology, sociology and sport all fall within the journal''s remit. The journal is therefore aimed at a wide statistical audience and at professional statisticians in particular. Its emphasis is on well-written and clearly reasoned quantitative approaches to problems in the real world rather than the exposition of technical detail. Thus, although the methodological basis of papers must be sound and adequately explained, methodology per se should not be the main focus of a Series A paper. Of particular interest are papers on topical or contentious statistical issues, papers which give reviews or exposés of current statistical concerns and papers which demonstrate how appropriate statistical thinking has contributed to our understanding of important substantive questions. Historical, professional and biographical contributions are also welcome, as are discussions of methods of data collection and of ethical issues, provided that all such papers have substantial statistical relevance.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
