{"title":"公共云中编码存储系统的全球共享资源范式","authors":"Zhiyue Li , Guangyan Zhang","doi":"10.1016/j.fmre.2022.12.011","DOIUrl":null,"url":null,"abstract":"<div><p>Public clouds favor sharing of storage resources, in which many tenants acquire bandwidth and storage capacity from a shared storage pool. To provide high availability, data are often encoded to provide fault tolerance with low storage costs. Regarding this, efficiently organizing an encoded storage system for shared I/Os is critical for application performance. This is usually hard to achieve as different applications have different stripe configurations and fault tolerance levels. In this paper, we first study the block trace from the Alibaba cloud, and find that I/O patterns of modern applications prefer the resource sharing scheme. Based on this, we propose a globally shared resource paradigm for encoded storage system in the public cloud. The globally shared resource paradigm can provide balanced load and fault tolerance for numerous disk pool sizes and arbitrary application stripe configurations. Furthermore, we demonstrate with two case studies that our theory can help address the device-specific problems of HDD and SSD RAID arrays with slight modifications: comparing the existing resource partition and resource sharing methods, our theory can promote the rebuild speed of the HDD RAID arrays by 2.5<span><math><mo>×</mo></math></span>, and reduce the P99 tail latency of the SSD arrays by up to two orders of magnitude.</p></div>","PeriodicalId":34602,"journal":{"name":"Fundamental Research","volume":"4 3","pages":"Pages 642-650"},"PeriodicalIF":6.3000,"publicationDate":"2024-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2667325822004630/pdfft?md5=5ee0f68e8fb31061424cefa81c24eee3&pid=1-s2.0-S2667325822004630-main.pdf","citationCount":"0","resultStr":"{\"title\":\"A globally shared resource paradigm for encoded storage systems in the public cloud\",\"authors\":\"Zhiyue Li , Guangyan Zhang\",\"doi\":\"10.1016/j.fmre.2022.12.011\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Public clouds favor sharing of storage resources, in which many tenants acquire bandwidth and storage capacity from a shared storage pool. To provide high availability, data are often encoded to provide fault tolerance with low storage costs. Regarding this, efficiently organizing an encoded storage system for shared I/Os is critical for application performance. This is usually hard to achieve as different applications have different stripe configurations and fault tolerance levels. In this paper, we first study the block trace from the Alibaba cloud, and find that I/O patterns of modern applications prefer the resource sharing scheme. Based on this, we propose a globally shared resource paradigm for encoded storage system in the public cloud. The globally shared resource paradigm can provide balanced load and fault tolerance for numerous disk pool sizes and arbitrary application stripe configurations. Furthermore, we demonstrate with two case studies that our theory can help address the device-specific problems of HDD and SSD RAID arrays with slight modifications: comparing the existing resource partition and resource sharing methods, our theory can promote the rebuild speed of the HDD RAID arrays by 2.5<span><math><mo>×</mo></math></span>, and reduce the P99 tail latency of the SSD arrays by up to two orders of magnitude.</p></div>\",\"PeriodicalId\":34602,\"journal\":{\"name\":\"Fundamental Research\",\"volume\":\"4 3\",\"pages\":\"Pages 642-650\"},\"PeriodicalIF\":6.3000,\"publicationDate\":\"2024-05-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S2667325822004630/pdfft?md5=5ee0f68e8fb31061424cefa81c24eee3&pid=1-s2.0-S2667325822004630-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Fundamental Research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2667325822004630\",\"RegionNum\":3,\"RegionCategory\":\"综合性期刊\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/1/5 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"Multidisciplinary\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Fundamental Research","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2667325822004630","RegionNum":3,"RegionCategory":"综合性期刊","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/5 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"Multidisciplinary","Score":null,"Total":0}
A globally shared resource paradigm for encoded storage systems in the public cloud
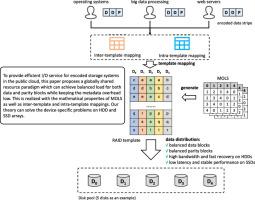
Public clouds favor sharing of storage resources, in which many tenants acquire bandwidth and storage capacity from a shared storage pool. To provide high availability, data are often encoded to provide fault tolerance with low storage costs. Regarding this, efficiently organizing an encoded storage system for shared I/Os is critical for application performance. This is usually hard to achieve as different applications have different stripe configurations and fault tolerance levels. In this paper, we first study the block trace from the Alibaba cloud, and find that I/O patterns of modern applications prefer the resource sharing scheme. Based on this, we propose a globally shared resource paradigm for encoded storage system in the public cloud. The globally shared resource paradigm can provide balanced load and fault tolerance for numerous disk pool sizes and arbitrary application stripe configurations. Furthermore, we demonstrate with two case studies that our theory can help address the device-specific problems of HDD and SSD RAID arrays with slight modifications: comparing the existing resource partition and resource sharing methods, our theory can promote the rebuild speed of the HDD RAID arrays by 2.5, and reduce the P99 tail latency of the SSD arrays by up to two orders of magnitude.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
