{"title":"交叉验证的排列特征重要性考虑特征之间的相关性","authors":"Hiromasa Kaneko","doi":"10.1002/ansa.202200018","DOIUrl":null,"url":null,"abstract":"<p>In molecular design, material design, process design, and process control, it is important not only to construct a model with high predictive ability between explanatory features x and objective features y using a dataset but also to interpret the constructed model. An index of feature importance in x is permutation feature importance (PFI), which can be combined with any regressors and classifiers. However, the PFI becomes unstable when the number of samples is low because it is necessary to divide a dataset into training and validation data when calculating it. Additionally, when there are strongly correlated features in x, the PFI of these features is estimated to be low. Hence, a cross-validated PFI (CVPFI) method is proposed. CVPFI can be calculated stably, even with a small number of samples, because model construction and feature evaluation are repeated based on cross-validation. Furthermore, by considering the absolute correlation coefficients between the features, the feature importance can be evaluated appropriately even when there are strongly correlated features in x. Case studies using numerical simulation data and actual compound data showed that the feature importance can be evaluated appropriately using CVPFI compared to PFI. This is possible when the number of samples is low, when linear and nonlinear relationships are mixed between x and y when there are strong correlations between features in x, and when quantised and biased features exist in x. Python codes for CVPFI are available at https://github.com/hkaneko1985/dcekit.</p>","PeriodicalId":93411,"journal":{"name":"Analytical science advances","volume":"3 9-10","pages":"278-287"},"PeriodicalIF":4.1000,"publicationDate":"2022-09-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://chemistry-europe.onlinelibrary.wiley.com/doi/epdf/10.1002/ansa.202200018","citationCount":"13","resultStr":"{\"title\":\"Cross-validated permutation feature importance considering correlation between features\",\"authors\":\"Hiromasa Kaneko\",\"doi\":\"10.1002/ansa.202200018\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>In molecular design, material design, process design, and process control, it is important not only to construct a model with high predictive ability between explanatory features x and objective features y using a dataset but also to interpret the constructed model. An index of feature importance in x is permutation feature importance (PFI), which can be combined with any regressors and classifiers. However, the PFI becomes unstable when the number of samples is low because it is necessary to divide a dataset into training and validation data when calculating it. Additionally, when there are strongly correlated features in x, the PFI of these features is estimated to be low. Hence, a cross-validated PFI (CVPFI) method is proposed. CVPFI can be calculated stably, even with a small number of samples, because model construction and feature evaluation are repeated based on cross-validation. Furthermore, by considering the absolute correlation coefficients between the features, the feature importance can be evaluated appropriately even when there are strongly correlated features in x. Case studies using numerical simulation data and actual compound data showed that the feature importance can be evaluated appropriately using CVPFI compared to PFI. This is possible when the number of samples is low, when linear and nonlinear relationships are mixed between x and y when there are strong correlations between features in x, and when quantised and biased features exist in x. Python codes for CVPFI are available at https://github.com/hkaneko1985/dcekit.</p>\",\"PeriodicalId\":93411,\"journal\":{\"name\":\"Analytical science advances\",\"volume\":\"3 9-10\",\"pages\":\"278-287\"},\"PeriodicalIF\":4.1000,\"publicationDate\":\"2022-09-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://chemistry-europe.onlinelibrary.wiley.com/doi/epdf/10.1002/ansa.202200018\",\"citationCount\":\"13\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Analytical science advances\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/ansa.202200018\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"CHEMISTRY, ANALYTICAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Analytical science advances","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/ansa.202200018","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"CHEMISTRY, ANALYTICAL","Score":null,"Total":0}
Cross-validated permutation feature importance considering correlation between features
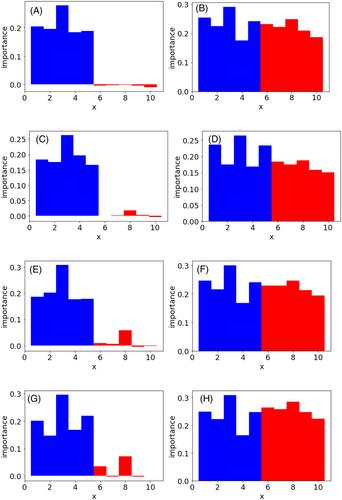
In molecular design, material design, process design, and process control, it is important not only to construct a model with high predictive ability between explanatory features x and objective features y using a dataset but also to interpret the constructed model. An index of feature importance in x is permutation feature importance (PFI), which can be combined with any regressors and classifiers. However, the PFI becomes unstable when the number of samples is low because it is necessary to divide a dataset into training and validation data when calculating it. Additionally, when there are strongly correlated features in x, the PFI of these features is estimated to be low. Hence, a cross-validated PFI (CVPFI) method is proposed. CVPFI can be calculated stably, even with a small number of samples, because model construction and feature evaluation are repeated based on cross-validation. Furthermore, by considering the absolute correlation coefficients between the features, the feature importance can be evaluated appropriately even when there are strongly correlated features in x. Case studies using numerical simulation data and actual compound data showed that the feature importance can be evaluated appropriately using CVPFI compared to PFI. This is possible when the number of samples is low, when linear and nonlinear relationships are mixed between x and y when there are strong correlations between features in x, and when quantised and biased features exist in x. Python codes for CVPFI are available at https://github.com/hkaneko1985/dcekit.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
