{"title":"一种新的基于噪声网络和梯度并行化的异步优势因子-批评家算法","authors":"Zhengshun Fei, Yanping Wang, Jinglong Wang, Kangling Liu, Bingqiang Huang, Ping Tan","doi":"10.1049/csy2.12059","DOIUrl":null,"url":null,"abstract":"<p>Asynchronous advantage actor-critic (A3C) algorithm is a commonly used policy optimization algorithm in reinforcement learning, in which asynchronous is parallel interactive sampling and training, and advantage is a sampling multi-step reward estimation method for computing weights. In order to address the problem of low efficiency and insufficient convergence caused by the traditional heuristic exploration of A3C algorithm in reinforcement learning, an improved A3C algorithm is proposed in this paper. In this algorithm, a noise network function, which updates the noise tensor in an explicit way is constructed to train the agent. Generalised advantage estimation (GAE) is also adopted to describe the dominance function. Finally, a new mean gradient parallelisation method is designed to update the parameters in both the primary and secondary networks by summing and averaging the gradients passed from all the sub-processes to the main process. Simulation experiments were conducted in a gym environment using the PyTorch Agent Net (PTAN) advanced reinforcement learning library, and the results show that the method enables the agent to complete the learning training faster and its convergence during the training process is better. The improved A3C algorithm has a better performance than the original algorithm, which can provide new ideas for subsequent research on reinforcement learning algorithms.</p>","PeriodicalId":34110,"journal":{"name":"IET Cybersystems and Robotics","volume":"4 3","pages":"175-188"},"PeriodicalIF":1.2000,"publicationDate":"2022-09-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ietresearch.onlinelibrary.wiley.com/doi/epdf/10.1049/csy2.12059","citationCount":"2","resultStr":"{\"title\":\"A new noise network and gradient parallelisation-based asynchronous advantage actor-critic algorithm\",\"authors\":\"Zhengshun Fei, Yanping Wang, Jinglong Wang, Kangling Liu, Bingqiang Huang, Ping Tan\",\"doi\":\"10.1049/csy2.12059\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Asynchronous advantage actor-critic (A3C) algorithm is a commonly used policy optimization algorithm in reinforcement learning, in which asynchronous is parallel interactive sampling and training, and advantage is a sampling multi-step reward estimation method for computing weights. In order to address the problem of low efficiency and insufficient convergence caused by the traditional heuristic exploration of A3C algorithm in reinforcement learning, an improved A3C algorithm is proposed in this paper. In this algorithm, a noise network function, which updates the noise tensor in an explicit way is constructed to train the agent. Generalised advantage estimation (GAE) is also adopted to describe the dominance function. Finally, a new mean gradient parallelisation method is designed to update the parameters in both the primary and secondary networks by summing and averaging the gradients passed from all the sub-processes to the main process. Simulation experiments were conducted in a gym environment using the PyTorch Agent Net (PTAN) advanced reinforcement learning library, and the results show that the method enables the agent to complete the learning training faster and its convergence during the training process is better. The improved A3C algorithm has a better performance than the original algorithm, which can provide new ideas for subsequent research on reinforcement learning algorithms.</p>\",\"PeriodicalId\":34110,\"journal\":{\"name\":\"IET Cybersystems and Robotics\",\"volume\":\"4 3\",\"pages\":\"175-188\"},\"PeriodicalIF\":1.2000,\"publicationDate\":\"2022-09-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ietresearch.onlinelibrary.wiley.com/doi/epdf/10.1049/csy2.12059\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"IET Cybersystems and Robotics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1049/csy2.12059\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"AUTOMATION & CONTROL SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Cybersystems and Robotics","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/csy2.12059","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
引用次数: 2
摘要
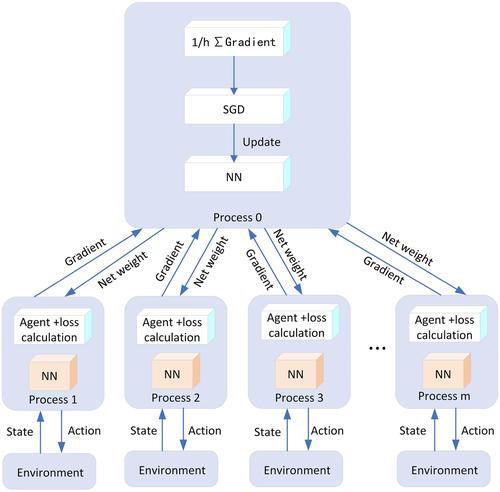
异步优势actor-critic (A3C)算法是强化学习中常用的策略优化算法,其中异步是并行交互采样和训练,优势是一种计算权重的采样多步奖励估计方法。针对传统的启发式A3C算法在强化学习中效率低、收敛性不足的问题,本文提出了一种改进的A3C算法。该算法通过构造一个噪声网络函数,以显式方式更新噪声张量来训练智能体。采用广义优势估计(GAE)来描述优势函数。最后,设计了一种新的平均梯度并行化方法,通过对所有子过程传递给主过程的梯度求和和平均,来更新主、次网络中的参数。利用PyTorch Agent Net (PTAN)高级强化学习库在体育馆环境下进行了仿真实验,结果表明该方法能够使智能体更快地完成学习训练,并且在训练过程中的收敛性更好。改进后的A3C算法性能优于原算法,可以为后续强化学习算法的研究提供新的思路。
A new noise network and gradient parallelisation-based asynchronous advantage actor-critic algorithm
Asynchronous advantage actor-critic (A3C) algorithm is a commonly used policy optimization algorithm in reinforcement learning, in which asynchronous is parallel interactive sampling and training, and advantage is a sampling multi-step reward estimation method for computing weights. In order to address the problem of low efficiency and insufficient convergence caused by the traditional heuristic exploration of A3C algorithm in reinforcement learning, an improved A3C algorithm is proposed in this paper. In this algorithm, a noise network function, which updates the noise tensor in an explicit way is constructed to train the agent. Generalised advantage estimation (GAE) is also adopted to describe the dominance function. Finally, a new mean gradient parallelisation method is designed to update the parameters in both the primary and secondary networks by summing and averaging the gradients passed from all the sub-processes to the main process. Simulation experiments were conducted in a gym environment using the PyTorch Agent Net (PTAN) advanced reinforcement learning library, and the results show that the method enables the agent to complete the learning training faster and its convergence during the training process is better. The improved A3C algorithm has a better performance than the original algorithm, which can provide new ideas for subsequent research on reinforcement learning algorithms.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
