{"title":"通过矩阵和张量分解无监督的基于EHR的表型","authors":"Florian Becker, A. Smilde, E. Acar","doi":"10.1002/widm.1494","DOIUrl":null,"url":null,"abstract":"Computational phenotyping allows for unsupervised discovery of subgroups of patients as well as corresponding co‐occurring medical conditions from electronic health records (EHR). Typically, EHR data contains demographic information, diagnoses and laboratory results. Discovering (novel) phenotypes has the potential to be of prognostic and therapeutic value. Providing medical practitioners with transparent and interpretable results is an important requirement and an essential part for advancing precision medicine. Low‐rank data approximation methods such as matrix (e.g., nonnegative matrix factorization) and tensor decompositions (e.g., CANDECOMP/PARAFAC) have demonstrated that they can provide such transparent and interpretable insights. Recent developments have adapted low‐rank data approximation methods by incorporating different constraints and regularizations that facilitate interpretability further. In addition, they offer solutions for common challenges within EHR data such as high dimensionality, data sparsity and incompleteness. Especially extracting temporal phenotypes from longitudinal EHR has received much attention in recent years. In this paper, we provide a comprehensive review of low‐rank approximation‐based approaches for computational phenotyping. The existing literature is categorized into temporal versus static phenotyping approaches based on matrix versus tensor decompositions. Furthermore, we outline different approaches for the validation of phenotypes, that is, the assessment of clinical significance.","PeriodicalId":48970,"journal":{"name":"Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery","volume":"5 1","pages":""},"PeriodicalIF":11.7000,"publicationDate":"2022-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"2","resultStr":"{\"title\":\"Unsupervised EHR‐based phenotyping via matrix and tensor decompositions\",\"authors\":\"Florian Becker, A. Smilde, E. Acar\",\"doi\":\"10.1002/widm.1494\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Computational phenotyping allows for unsupervised discovery of subgroups of patients as well as corresponding co‐occurring medical conditions from electronic health records (EHR). Typically, EHR data contains demographic information, diagnoses and laboratory results. Discovering (novel) phenotypes has the potential to be of prognostic and therapeutic value. Providing medical practitioners with transparent and interpretable results is an important requirement and an essential part for advancing precision medicine. Low‐rank data approximation methods such as matrix (e.g., nonnegative matrix factorization) and tensor decompositions (e.g., CANDECOMP/PARAFAC) have demonstrated that they can provide such transparent and interpretable insights. Recent developments have adapted low‐rank data approximation methods by incorporating different constraints and regularizations that facilitate interpretability further. In addition, they offer solutions for common challenges within EHR data such as high dimensionality, data sparsity and incompleteness. Especially extracting temporal phenotypes from longitudinal EHR has received much attention in recent years. In this paper, we provide a comprehensive review of low‐rank approximation‐based approaches for computational phenotyping. The existing literature is categorized into temporal versus static phenotyping approaches based on matrix versus tensor decompositions. Furthermore, we outline different approaches for the validation of phenotypes, that is, the assessment of clinical significance.\",\"PeriodicalId\":48970,\"journal\":{\"name\":\"Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery\",\"volume\":\"5 1\",\"pages\":\"\"},\"PeriodicalIF\":11.7000,\"publicationDate\":\"2022-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1002/widm.1494\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1002/widm.1494","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Unsupervised EHR‐based phenotyping via matrix and tensor decompositions
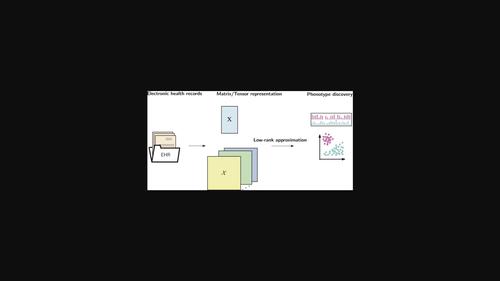
Computational phenotyping allows for unsupervised discovery of subgroups of patients as well as corresponding co‐occurring medical conditions from electronic health records (EHR). Typically, EHR data contains demographic information, diagnoses and laboratory results. Discovering (novel) phenotypes has the potential to be of prognostic and therapeutic value. Providing medical practitioners with transparent and interpretable results is an important requirement and an essential part for advancing precision medicine. Low‐rank data approximation methods such as matrix (e.g., nonnegative matrix factorization) and tensor decompositions (e.g., CANDECOMP/PARAFAC) have demonstrated that they can provide such transparent and interpretable insights. Recent developments have adapted low‐rank data approximation methods by incorporating different constraints and regularizations that facilitate interpretability further. In addition, they offer solutions for common challenges within EHR data such as high dimensionality, data sparsity and incompleteness. Especially extracting temporal phenotypes from longitudinal EHR has received much attention in recent years. In this paper, we provide a comprehensive review of low‐rank approximation‐based approaches for computational phenotyping. The existing literature is categorized into temporal versus static phenotyping approaches based on matrix versus tensor decompositions. Furthermore, we outline different approaches for the validation of phenotypes, that is, the assessment of clinical significance.
期刊介绍:
The goals of Wiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery (WIREs DMKD) are multifaceted. Firstly, the journal aims to provide a comprehensive overview of the current state of data mining and knowledge discovery by featuring ongoing reviews authored by leading researchers. Secondly, it seeks to highlight the interdisciplinary nature of the field by presenting articles from diverse perspectives, covering various application areas such as technology, business, healthcare, education, government, society, and culture. Thirdly, WIREs DMKD endeavors to keep pace with the rapid advancements in data mining and knowledge discovery through regular content updates. Lastly, the journal strives to promote active engagement in the field by presenting its accomplishments and challenges in an accessible manner to a broad audience. The content of WIREs DMKD is intended to benefit upper-level undergraduate and postgraduate students, teaching and research professors in academic programs, as well as scientists and research managers in industry.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
