{"title":"E2VIDX:传统视觉和仿生视觉之间的桥梁。","authors":"Xujia Hou, Feihu Zhang, Dhiraj Gulati, Tingfeng Tan, Wei Zhang","doi":"10.3389/fnbot.2023.1277160","DOIUrl":null,"url":null,"abstract":"<p><p>Common RGBD, CMOS, and CCD-based cameras produce motion blur and incorrect exposure under high-speed and improper lighting conditions. According to the bionic principle, the event camera developed has the advantages of low delay, high dynamic range, and no motion blur. However, due to its unique data representation, it encounters significant obstacles in practical applications. The image reconstruction algorithm based on an event camera solves the problem by converting a series of \"events\" into common frames to apply existing vision algorithms. Due to the rapid development of neural networks, this field has made significant breakthroughs in past few years. Based on the most popular Events-to-Video (E2VID) method, this study designs a new network called E2VIDX. The proposed network includes group convolution and sub-pixel convolution, which not only achieves better feature fusion but also the network model size is reduced by 25%. Futhermore, we propose a new loss function. The loss function is divided into two parts, first part calculates the high level features and the second part calculates the low level features of the reconstructed image. The experimental results clearly outperform against the state-of-the-art method. Compared with the original method, Structural Similarity (SSIM) increases by 1.3%, Learned Perceptual Image Patch Similarity (LPIPS) decreases by 1.7%, Mean Squared Error (MSE) decreases by 2.5%, and it runs faster on GPU and CPU. Additionally, we evaluate the results of E2VIDX with application to image classification, object detection, and instance segmentation. The experiments show that conversions using our method can help event cameras directly apply existing vision algorithms in most scenarios.</p>","PeriodicalId":12628,"journal":{"name":"Frontiers in Neurorobotics","volume":"17 ","pages":"1277160"},"PeriodicalIF":2.8000,"publicationDate":"2023-10-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10639115/pdf/","citationCount":"0","resultStr":"{\"title\":\"E2VIDX: improved bridge between conventional vision and bionic vision.\",\"authors\":\"Xujia Hou, Feihu Zhang, Dhiraj Gulati, Tingfeng Tan, Wei Zhang\",\"doi\":\"10.3389/fnbot.2023.1277160\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Common RGBD, CMOS, and CCD-based cameras produce motion blur and incorrect exposure under high-speed and improper lighting conditions. According to the bionic principle, the event camera developed has the advantages of low delay, high dynamic range, and no motion blur. However, due to its unique data representation, it encounters significant obstacles in practical applications. The image reconstruction algorithm based on an event camera solves the problem by converting a series of \\\"events\\\" into common frames to apply existing vision algorithms. Due to the rapid development of neural networks, this field has made significant breakthroughs in past few years. Based on the most popular Events-to-Video (E2VID) method, this study designs a new network called E2VIDX. The proposed network includes group convolution and sub-pixel convolution, which not only achieves better feature fusion but also the network model size is reduced by 25%. Futhermore, we propose a new loss function. The loss function is divided into two parts, first part calculates the high level features and the second part calculates the low level features of the reconstructed image. The experimental results clearly outperform against the state-of-the-art method. Compared with the original method, Structural Similarity (SSIM) increases by 1.3%, Learned Perceptual Image Patch Similarity (LPIPS) decreases by 1.7%, Mean Squared Error (MSE) decreases by 2.5%, and it runs faster on GPU and CPU. Additionally, we evaluate the results of E2VIDX with application to image classification, object detection, and instance segmentation. The experiments show that conversions using our method can help event cameras directly apply existing vision algorithms in most scenarios.</p>\",\"PeriodicalId\":12628,\"journal\":{\"name\":\"Frontiers in Neurorobotics\",\"volume\":\"17 \",\"pages\":\"1277160\"},\"PeriodicalIF\":2.8000,\"publicationDate\":\"2023-10-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10639115/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Frontiers in Neurorobotics\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.3389/fnbot.2023.1277160\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Neurorobotics","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.3389/fnbot.2023.1277160","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
E2VIDX: improved bridge between conventional vision and bionic vision.
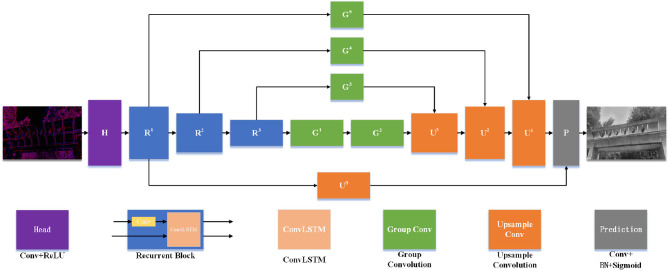
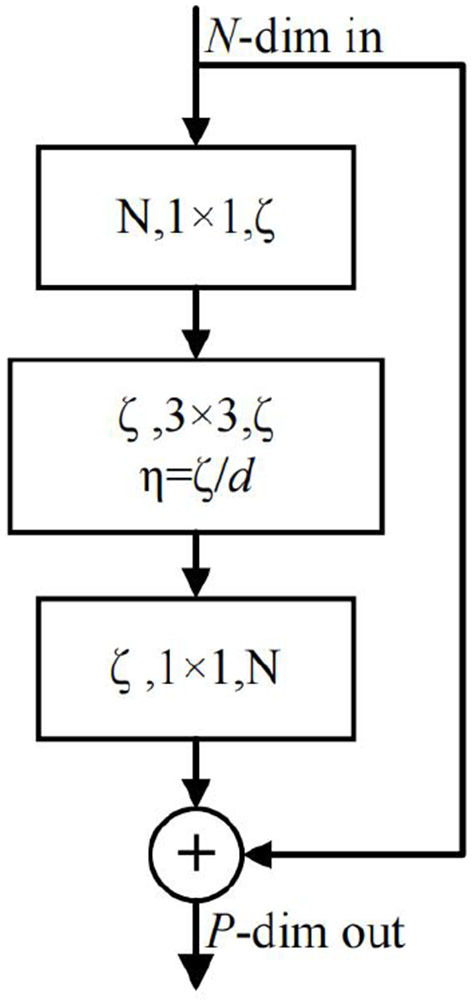
Common RGBD, CMOS, and CCD-based cameras produce motion blur and incorrect exposure under high-speed and improper lighting conditions. According to the bionic principle, the event camera developed has the advantages of low delay, high dynamic range, and no motion blur. However, due to its unique data representation, it encounters significant obstacles in practical applications. The image reconstruction algorithm based on an event camera solves the problem by converting a series of "events" into common frames to apply existing vision algorithms. Due to the rapid development of neural networks, this field has made significant breakthroughs in past few years. Based on the most popular Events-to-Video (E2VID) method, this study designs a new network called E2VIDX. The proposed network includes group convolution and sub-pixel convolution, which not only achieves better feature fusion but also the network model size is reduced by 25%. Futhermore, we propose a new loss function. The loss function is divided into two parts, first part calculates the high level features and the second part calculates the low level features of the reconstructed image. The experimental results clearly outperform against the state-of-the-art method. Compared with the original method, Structural Similarity (SSIM) increases by 1.3%, Learned Perceptual Image Patch Similarity (LPIPS) decreases by 1.7%, Mean Squared Error (MSE) decreases by 2.5%, and it runs faster on GPU and CPU. Additionally, we evaluate the results of E2VIDX with application to image classification, object detection, and instance segmentation. The experiments show that conversions using our method can help event cameras directly apply existing vision algorithms in most scenarios.
期刊介绍:
Frontiers in Neurorobotics publishes rigorously peer-reviewed research in the science and technology of embodied autonomous neural systems. Specialty Chief Editors Alois C. Knoll and Florian Röhrbein at the Technische Universität München are supported by an outstanding Editorial Board of international experts. This multidisciplinary open-access journal is at the forefront of disseminating and communicating scientific knowledge and impactful discoveries to researchers, academics and the public worldwide.
Neural systems include brain-inspired algorithms (e.g. connectionist networks), computational models of biological neural networks (e.g. artificial spiking neural nets, large-scale simulations of neural microcircuits) and actual biological systems (e.g. in vivo and in vitro neural nets). The focus of the journal is the embodiment of such neural systems in artificial software and hardware devices, machines, robots or any other form of physical actuation. This also includes prosthetic devices, brain machine interfaces, wearable systems, micro-machines, furniture, home appliances, as well as systems for managing micro and macro infrastructures. Frontiers in Neurorobotics also aims to publish radically new tools and methods to study plasticity and development of autonomous self-learning systems that are capable of acquiring knowledge in an open-ended manner. Models complemented with experimental studies revealing self-organizing principles of embodied neural systems are welcome. Our journal also publishes on the micro and macro engineering and mechatronics of robotic devices driven by neural systems, as well as studies on the impact that such systems will have on our daily life.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
