{"title":"连接数据管理平台和可视化工具,实现生命科学领域的临时和智能分析。","authors":"Christian Panse, Christian Trachsel, Can Türker","doi":"10.1515/jib-2022-0031","DOIUrl":null,"url":null,"abstract":"<p><p>Core facilities have to offer technologies that best serve the needs of their users and provide them a competitive advantage in research. They have to set up and maintain instruments in the range of ten to a hundred, which produce large amounts of data and serve thousands of active projects and customers. Particular emphasis has to be given to the reproducibility of the results. More and more, the entire process from building the research hypothesis, conducting the experiments, doing the measurements, through the data explorations and analysis is solely driven by very few experts in various scientific fields. Still, the ability to perform the entire data exploration in real-time on a personal computer is often hampered by the heterogeneity of software, the data structure formats of the output, and the enormous data sizes. These impact the design and architecture of the implemented software stack. At the Functional Genomics Center Zurich (FGCZ), a joint state-of-the-art research and training facility of ETH Zurich and the University of Zurich, we have developed the B-Fabric system, which has served for more than a decade, an entire life sciences community with fundamental data science support. In this paper, we sketch how such a system can be used to glue together data (including metadata), computing infrastructures (clusters and clouds), and visualization software to support instant data exploration and visual analysis. We illustrate our in-daily life implemented approach using visualization applications of mass spectrometry data.</p>","PeriodicalId":53625,"journal":{"name":"Journal of Integrative Bioinformatics","volume":"19 4","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2022-09-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9800043/pdf/","citationCount":"5","resultStr":"{\"title\":\"Bridging data management platforms and visualization tools to enable ad-hoc and smart analytics in life sciences.\",\"authors\":\"Christian Panse, Christian Trachsel, Can Türker\",\"doi\":\"10.1515/jib-2022-0031\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Core facilities have to offer technologies that best serve the needs of their users and provide them a competitive advantage in research. They have to set up and maintain instruments in the range of ten to a hundred, which produce large amounts of data and serve thousands of active projects and customers. Particular emphasis has to be given to the reproducibility of the results. More and more, the entire process from building the research hypothesis, conducting the experiments, doing the measurements, through the data explorations and analysis is solely driven by very few experts in various scientific fields. Still, the ability to perform the entire data exploration in real-time on a personal computer is often hampered by the heterogeneity of software, the data structure formats of the output, and the enormous data sizes. These impact the design and architecture of the implemented software stack. At the Functional Genomics Center Zurich (FGCZ), a joint state-of-the-art research and training facility of ETH Zurich and the University of Zurich, we have developed the B-Fabric system, which has served for more than a decade, an entire life sciences community with fundamental data science support. In this paper, we sketch how such a system can be used to glue together data (including metadata), computing infrastructures (clusters and clouds), and visualization software to support instant data exploration and visual analysis. We illustrate our in-daily life implemented approach using visualization applications of mass spectrometry data.</p>\",\"PeriodicalId\":53625,\"journal\":{\"name\":\"Journal of Integrative Bioinformatics\",\"volume\":\"19 4\",\"pages\":\"\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2022-09-08\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9800043/pdf/\",\"citationCount\":\"5\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Integrative Bioinformatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1515/jib-2022-0031\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/12/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Integrative Bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1515/jib-2022-0031","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/12/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 5
摘要
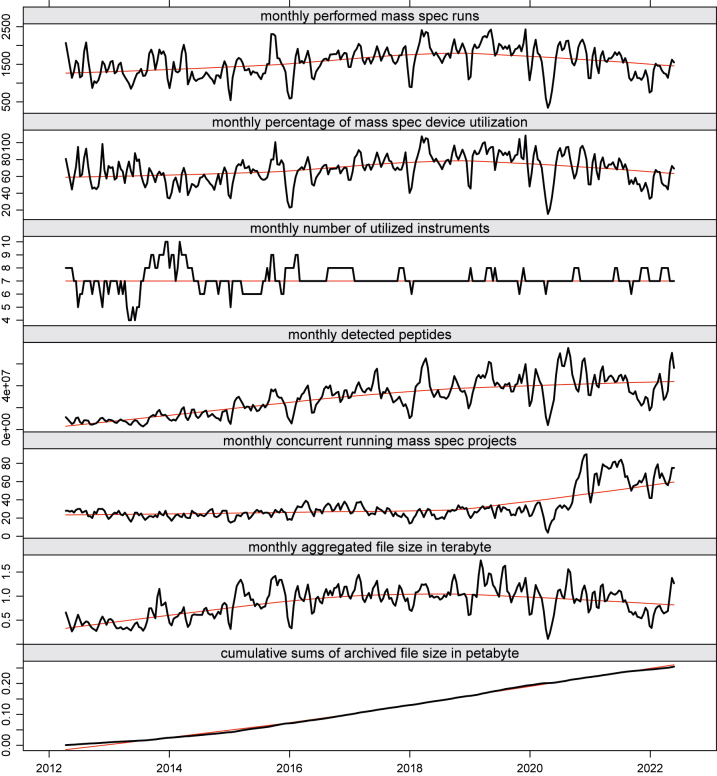
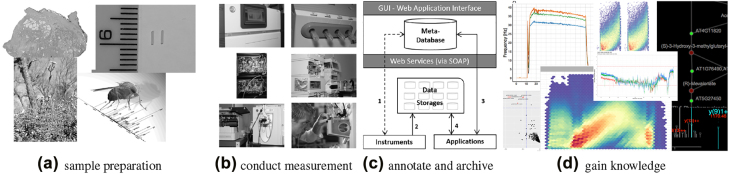
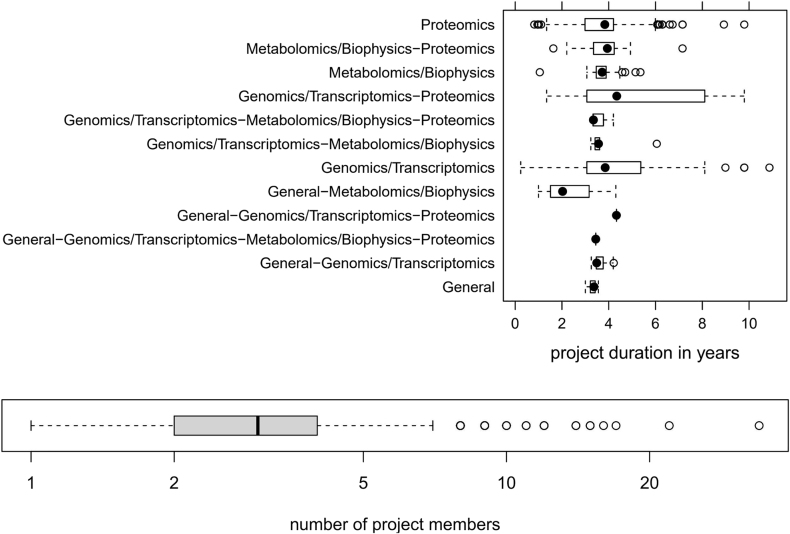
核心设施必须提供最能满足用户需求的技术,并为其提供研究方面的竞争优势。它们必须建立和维护十到一百台仪器,这些仪器产生大量数据,为成千上万个活跃的项目和客户服务。必须特别强调结果的可重复性。从提出研究假设、开展实验、进行测量到数据探索和分析的整个过程,越来越多地由各科学领域的极少数专家独自完成。然而,在个人电脑上实时进行整个数据探索的能力往往受到软件的异构性、输出的数据结构格式和巨大数据量的阻碍。这些都会影响软件栈的设计和架构。苏黎世功能基因组学中心(FGCZ)是苏黎世联邦理工学院(ETH)和苏黎世大学(University of Zurich)联合建立的最先进的研究和培训机构,我们在该中心开发了 B-Fabric 系统,十多年来为整个生命科学界提供了基础数据科学支持。在本文中,我们将简要介绍如何利用这种系统将数据(包括元数据)、计算基础设施(集群和云)以及可视化软件粘合在一起,以支持即时数据探索和可视化分析。我们利用质谱数据的可视化应用来说明我们在日常生活中实施的方法。
Bridging data management platforms and visualization tools to enable ad-hoc and smart analytics in life sciences.
Core facilities have to offer technologies that best serve the needs of their users and provide them a competitive advantage in research. They have to set up and maintain instruments in the range of ten to a hundred, which produce large amounts of data and serve thousands of active projects and customers. Particular emphasis has to be given to the reproducibility of the results. More and more, the entire process from building the research hypothesis, conducting the experiments, doing the measurements, through the data explorations and analysis is solely driven by very few experts in various scientific fields. Still, the ability to perform the entire data exploration in real-time on a personal computer is often hampered by the heterogeneity of software, the data structure formats of the output, and the enormous data sizes. These impact the design and architecture of the implemented software stack. At the Functional Genomics Center Zurich (FGCZ), a joint state-of-the-art research and training facility of ETH Zurich and the University of Zurich, we have developed the B-Fabric system, which has served for more than a decade, an entire life sciences community with fundamental data science support. In this paper, we sketch how such a system can be used to glue together data (including metadata), computing infrastructures (clusters and clouds), and visualization software to support instant data exploration and visual analysis. We illustrate our in-daily life implemented approach using visualization applications of mass spectrometry data.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
