{"title":"眶额叶皮层的元强化学习。","authors":"Ryoma Hattori, Nathan G. Hedrick, Anant Jain, Shuqi Chen, Hanjia You, Mariko Hattori, Jun-Hyeok Choi, Byung Kook Lim, Ryohei Yasuda, Takaki Komiyama","doi":"10.1038/s41593-023-01485-3","DOIUrl":null,"url":null,"abstract":"The meta-reinforcement learning (meta-RL) framework, which involves RL over multiple timescales, has been successful in training deep RL models that generalize to new environments. It has been hypothesized that the prefrontal cortex may mediate meta-RL in the brain, but the evidence is scarce. Here we show that the orbitofrontal cortex (OFC) mediates meta-RL. We trained mice and deep RL models on a probabilistic reversal learning task across sessions during which they improved their trial-by-trial RL policy through meta-learning. Ca2+/calmodulin-dependent protein kinase II-dependent synaptic plasticity in OFC was necessary for this meta-learning but not for the within-session trial-by-trial RL in experts. After meta-learning, OFC activity robustly encoded value signals, and OFC inactivation impaired the RL behaviors. Longitudinal tracking of OFC activity revealed that meta-learning gradually shapes population value coding to guide the ongoing behavioral policy. Our results indicate that two distinct RL algorithms with distinct neural mechanisms and timescales coexist in OFC to support adaptive decision-making. The authors show that neural activity and synaptic plasticity in the orbitofrontal cortex mediate multiple timescales of reinforcement learning (RL) for meta-RL, which parallels a form of meta-RL in artificial intelligence.","PeriodicalId":19076,"journal":{"name":"Nature neuroscience","volume":"26 12","pages":"2182-2191"},"PeriodicalIF":20.0000,"publicationDate":"2023-11-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10689244/pdf/","citationCount":"0","resultStr":"{\"title\":\"Meta-reinforcement learning via orbitofrontal cortex\",\"authors\":\"Ryoma Hattori, Nathan G. Hedrick, Anant Jain, Shuqi Chen, Hanjia You, Mariko Hattori, Jun-Hyeok Choi, Byung Kook Lim, Ryohei Yasuda, Takaki Komiyama\",\"doi\":\"10.1038/s41593-023-01485-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"The meta-reinforcement learning (meta-RL) framework, which involves RL over multiple timescales, has been successful in training deep RL models that generalize to new environments. It has been hypothesized that the prefrontal cortex may mediate meta-RL in the brain, but the evidence is scarce. Here we show that the orbitofrontal cortex (OFC) mediates meta-RL. We trained mice and deep RL models on a probabilistic reversal learning task across sessions during which they improved their trial-by-trial RL policy through meta-learning. Ca2+/calmodulin-dependent protein kinase II-dependent synaptic plasticity in OFC was necessary for this meta-learning but not for the within-session trial-by-trial RL in experts. After meta-learning, OFC activity robustly encoded value signals, and OFC inactivation impaired the RL behaviors. Longitudinal tracking of OFC activity revealed that meta-learning gradually shapes population value coding to guide the ongoing behavioral policy. Our results indicate that two distinct RL algorithms with distinct neural mechanisms and timescales coexist in OFC to support adaptive decision-making. The authors show that neural activity and synaptic plasticity in the orbitofrontal cortex mediate multiple timescales of reinforcement learning (RL) for meta-RL, which parallels a form of meta-RL in artificial intelligence.\",\"PeriodicalId\":19076,\"journal\":{\"name\":\"Nature neuroscience\",\"volume\":\"26 12\",\"pages\":\"2182-2191\"},\"PeriodicalIF\":20.0000,\"publicationDate\":\"2023-11-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10689244/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature neuroscience\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.nature.com/articles/s41593-023-01485-3\",\"RegionNum\":1,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"NEUROSCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature neuroscience","FirstCategoryId":"3","ListUrlMain":"https://www.nature.com/articles/s41593-023-01485-3","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"NEUROSCIENCES","Score":null,"Total":0}
Meta-reinforcement learning via orbitofrontal cortex
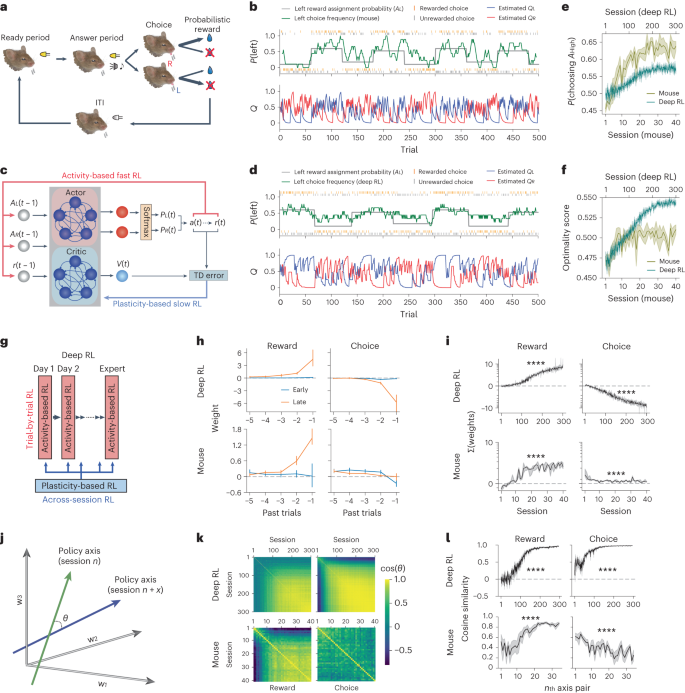
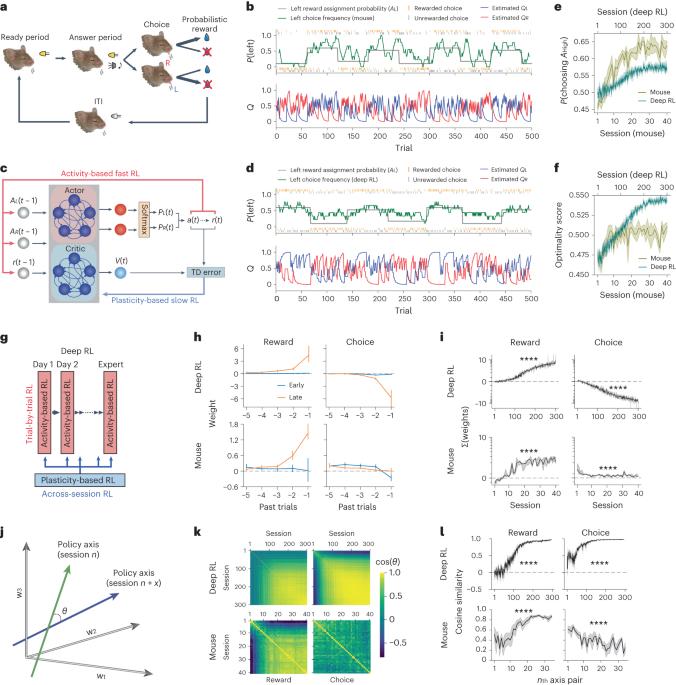
The meta-reinforcement learning (meta-RL) framework, which involves RL over multiple timescales, has been successful in training deep RL models that generalize to new environments. It has been hypothesized that the prefrontal cortex may mediate meta-RL in the brain, but the evidence is scarce. Here we show that the orbitofrontal cortex (OFC) mediates meta-RL. We trained mice and deep RL models on a probabilistic reversal learning task across sessions during which they improved their trial-by-trial RL policy through meta-learning. Ca2+/calmodulin-dependent protein kinase II-dependent synaptic plasticity in OFC was necessary for this meta-learning but not for the within-session trial-by-trial RL in experts. After meta-learning, OFC activity robustly encoded value signals, and OFC inactivation impaired the RL behaviors. Longitudinal tracking of OFC activity revealed that meta-learning gradually shapes population value coding to guide the ongoing behavioral policy. Our results indicate that two distinct RL algorithms with distinct neural mechanisms and timescales coexist in OFC to support adaptive decision-making. The authors show that neural activity and synaptic plasticity in the orbitofrontal cortex mediate multiple timescales of reinforcement learning (RL) for meta-RL, which parallels a form of meta-RL in artificial intelligence.
期刊介绍:
Nature Neuroscience, a multidisciplinary journal, publishes papers of the utmost quality and significance across all realms of neuroscience. The editors welcome contributions spanning molecular, cellular, systems, and cognitive neuroscience, along with psychophysics, computational modeling, and nervous system disorders. While no area is off-limits, studies offering fundamental insights into nervous system function receive priority.
The journal offers high visibility to both readers and authors, fostering interdisciplinary communication and accessibility to a broad audience. It maintains high standards of copy editing and production, rigorous peer review, rapid publication, and operates independently from academic societies and other vested interests.
In addition to primary research, Nature Neuroscience features news and views, reviews, editorials, commentaries, perspectives, book reviews, and correspondence, aiming to serve as the voice of the global neuroscience community.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
