Elliot A Martin, Adam G D'Souza, Seungwon Lee, Chelsea Doktorchik, Cathy A Eastwood, Hude Quan
{"title":"利用电子医疗记录中的住院病人临床记录识别高血压:一项可解释的、数据驱动的算法研究。","authors":"Elliot A Martin, Adam G D'Souza, Seungwon Lee, Chelsea Doktorchik, Cathy A Eastwood, Hude Quan","doi":"10.9778/cmajo.20210170","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Case identification is important for health services research, measuring health system performance and risk adjustment, but existing methods based on manual chart review or diagnosis codes can be expensive, time consuming or of limited validity. We aimed to develop a hypertension case definition in electronic medical records (EMRs) for inpatient clinical notes using machine learning.</p><p><strong>Methods: </strong>A cohort of patients 18 years of age or older who were discharged from 1 of 3 Calgary acute care facilities (1 academic hospital and 2 community hospitals) between Jan. 1 and June 30, 2015, were randomly selected, and we compared the performance of EMR phenotype algorithms developed using machine learning with an algorithm based on the Canadian version of the <i>International Statistical Classification of Diseases and Related Health Problems</i>, <i>10th Revision</i> (ICD), in identifying patients with hypertension. Hypertension status was determined by chart review, the machine-learning algorithms used EMR notes and the ICD algorithm used the Discharge Abstract Database (Canadian Institute for Health Information).</p><p><strong>Results: </strong>Of our study sample (<i>n</i> = 3040), 1475 (48.5%) patients had hypertension. The group with hypertension was older (median age of 71.0 yr v. 52.5 yr for those patients without hypertension) and had fewer females (710 [48.2%] v. 764 [52.3%]). Our final EMR-based models had higher sensitivity than the ICD algorithm (> 90% v. 47%), while maintaining high positive predictive values (> 90% v. 97%).</p><p><strong>Interpretation: </strong>We found that hypertension tends to have clear documentation in EMRs and is well classified by concept search on free text. Machine learning can provide insights into how and where conditions are documented in EMRs and suggest nonmachine-learning phenotypes to implement.</p>","PeriodicalId":10432,"journal":{"name":"CMAJ open","volume":"11 1","pages":"E131-E139"},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/a5/0b/cmajo.20210170.PMC9933992.pdf","citationCount":"2","resultStr":"{\"title\":\"Hypertension identification using inpatient clinical notes from electronic medical records: an explainable, data-driven algorithm study.\",\"authors\":\"Elliot A Martin, Adam G D'Souza, Seungwon Lee, Chelsea Doktorchik, Cathy A Eastwood, Hude Quan\",\"doi\":\"10.9778/cmajo.20210170\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Case identification is important for health services research, measuring health system performance and risk adjustment, but existing methods based on manual chart review or diagnosis codes can be expensive, time consuming or of limited validity. We aimed to develop a hypertension case definition in electronic medical records (EMRs) for inpatient clinical notes using machine learning.</p><p><strong>Methods: </strong>A cohort of patients 18 years of age or older who were discharged from 1 of 3 Calgary acute care facilities (1 academic hospital and 2 community hospitals) between Jan. 1 and June 30, 2015, were randomly selected, and we compared the performance of EMR phenotype algorithms developed using machine learning with an algorithm based on the Canadian version of the <i>International Statistical Classification of Diseases and Related Health Problems</i>, <i>10th Revision</i> (ICD), in identifying patients with hypertension. Hypertension status was determined by chart review, the machine-learning algorithms used EMR notes and the ICD algorithm used the Discharge Abstract Database (Canadian Institute for Health Information).</p><p><strong>Results: </strong>Of our study sample (<i>n</i> = 3040), 1475 (48.5%) patients had hypertension. The group with hypertension was older (median age of 71.0 yr v. 52.5 yr for those patients without hypertension) and had fewer females (710 [48.2%] v. 764 [52.3%]). Our final EMR-based models had higher sensitivity than the ICD algorithm (> 90% v. 47%), while maintaining high positive predictive values (> 90% v. 97%).</p><p><strong>Interpretation: </strong>We found that hypertension tends to have clear documentation in EMRs and is well classified by concept search on free text. Machine learning can provide insights into how and where conditions are documented in EMRs and suggest nonmachine-learning phenotypes to implement.</p>\",\"PeriodicalId\":10432,\"journal\":{\"name\":\"CMAJ open\",\"volume\":\"11 1\",\"pages\":\"E131-E139\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/a5/0b/cmajo.20210170.PMC9933992.pdf\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"CMAJ open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.9778/cmajo.20210170\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"CMAJ open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.9778/cmajo.20210170","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 2
摘要
背景:病例识别对于卫生服务研究、衡量卫生系统绩效和风险调整非常重要,但现有的基于手工图表审查或诊断代码的方法可能昂贵、耗时或有效性有限。我们的目标是利用机器学习为住院病人的临床记录开发电子病历(emr)中的高血压病例定义。方法:随机选择2015年1月1日至6月30日期间从卡尔加里3家急性护理机构(1家学术医院和2家社区医院)中的1家出院的18岁或以上患者,我们比较了使用机器学习开发的EMR表型算法与基于加拿大版国际疾病和相关健康问题统计分类第10版(ICD)的算法的性能。在识别高血压患者。通过图表回顾确定高血压状态,机器学习算法使用EMR记录,ICD算法使用出院摘要数据库(加拿大卫生信息研究所)。结果:在我们的研究样本(n = 3040)中,1475例(48.5%)患者患有高血压。高血压组年龄较大(中位年龄为71.0岁,无高血压组为52.5岁),女性较少(710例[48.2%]对764例[52.3%])。我们最终的基于emr的模型比ICD算法具有更高的灵敏度(> 90% vs . 47%),同时保持较高的阳性预测值(> 90% vs . 97%)。解释:我们发现高血压在电子病历中往往有明确的记录,并且通过免费文本的概念搜索可以很好地分类。机器学习可以深入了解emr中记录条件的方式和位置,并建议实施非机器学习表型。
Hypertension identification using inpatient clinical notes from electronic medical records: an explainable, data-driven algorithm study.
Background: Case identification is important for health services research, measuring health system performance and risk adjustment, but existing methods based on manual chart review or diagnosis codes can be expensive, time consuming or of limited validity. We aimed to develop a hypertension case definition in electronic medical records (EMRs) for inpatient clinical notes using machine learning.
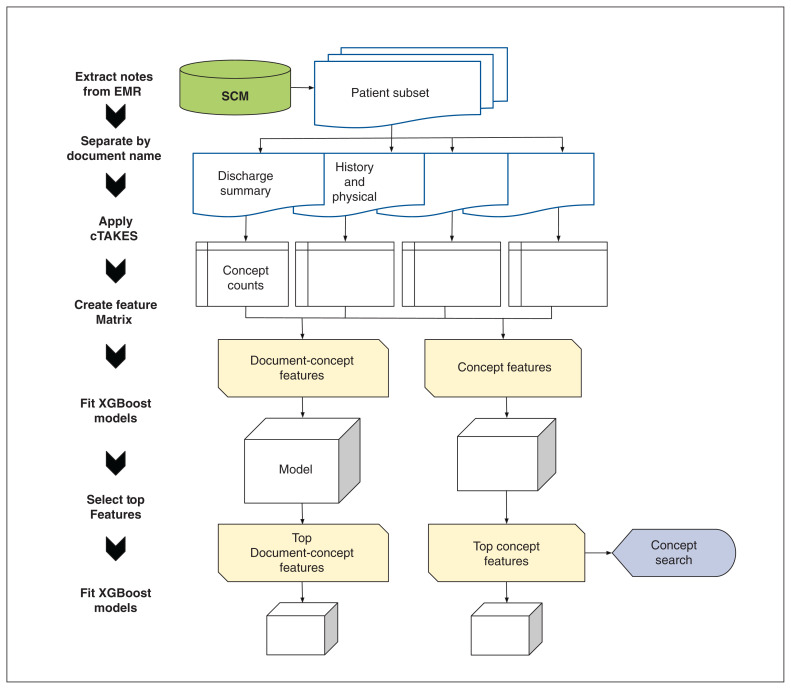
Methods: A cohort of patients 18 years of age or older who were discharged from 1 of 3 Calgary acute care facilities (1 academic hospital and 2 community hospitals) between Jan. 1 and June 30, 2015, were randomly selected, and we compared the performance of EMR phenotype algorithms developed using machine learning with an algorithm based on the Canadian version of the International Statistical Classification of Diseases and Related Health Problems, 10th Revision (ICD), in identifying patients with hypertension. Hypertension status was determined by chart review, the machine-learning algorithms used EMR notes and the ICD algorithm used the Discharge Abstract Database (Canadian Institute for Health Information).
Results: Of our study sample (n = 3040), 1475 (48.5%) patients had hypertension. The group with hypertension was older (median age of 71.0 yr v. 52.5 yr for those patients without hypertension) and had fewer females (710 [48.2%] v. 764 [52.3%]). Our final EMR-based models had higher sensitivity than the ICD algorithm (> 90% v. 47%), while maintaining high positive predictive values (> 90% v. 97%).
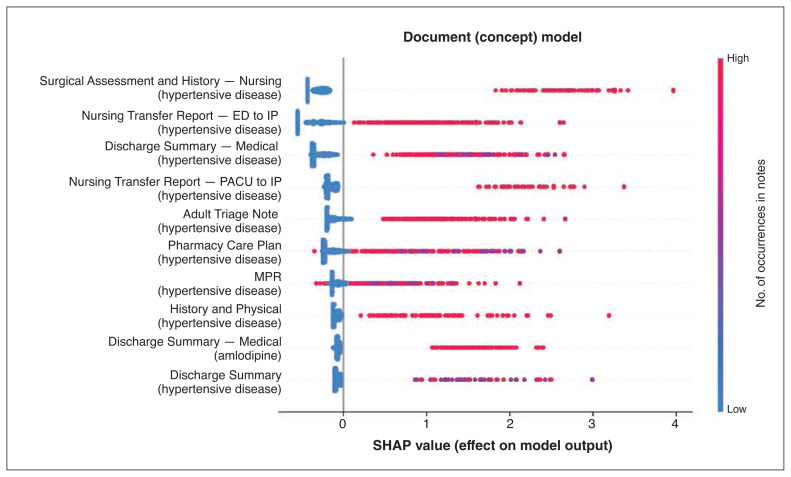
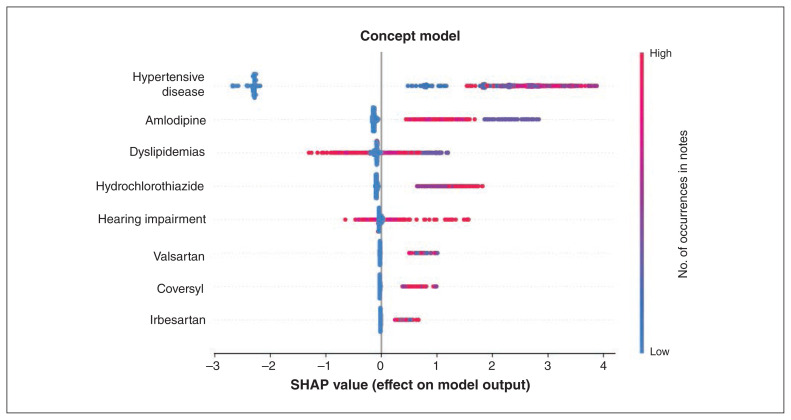
Interpretation: We found that hypertension tends to have clear documentation in EMRs and is well classified by concept search on free text. Machine learning can provide insights into how and where conditions are documented in EMRs and suggest nonmachine-learning phenotypes to implement.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
