{"title":"适应个性化研究和汇总个性化研究中的序列相关性和序列设计元素。","authors":"Nicholas J Schork","doi":"10.1162/99608f92.f1eef6f4","DOIUrl":null,"url":null,"abstract":"<p><p>Single subject, or 'N-of-1,' studies are receiving a great deal of attention from both theoretical and applied researchers. This is consistent with the growing acceptance of 'personalized' approaches to health care and the need to prove that personalized interventions tailored to an individual's likely unique physiological profile and other characteristics work as they should. In fact, the preferred way of referring to N-of-1 studies in contemporary settings is as 'personalized studies.' Designing efficient personalized studies and analyzing data from them in ways that ensure statistically valid inferences are not trivial, however. I briefly discuss some of the more complex issues surrounding the design and analysis of personalized studies, such as the use of washout periods, the frequency with which measures associated with the efficacy of an intervention are collected during a study, and the serious effect that serial correlation can have on the analysis and interpretation of personalized study data and results if not accounted for explicitly. I point out that more efficient sequential designs for personalized and aggregated personalized studies can be developed, and I explore the properties of sequential personalized studies in a few settings via simulation studies. Finally, I comment on contexts within which personalized studies will likely be pursued in the future.</p>","PeriodicalId":73195,"journal":{"name":"Harvard data science review","volume":"2022 SI3","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10081537/pdf/","citationCount":"0","resultStr":"{\"title\":\"Accommodating Serial Correlation and Sequential Design Elements in Personalized Studies and Aggregated Personalized Studies.\",\"authors\":\"Nicholas J Schork\",\"doi\":\"10.1162/99608f92.f1eef6f4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Single subject, or 'N-of-1,' studies are receiving a great deal of attention from both theoretical and applied researchers. This is consistent with the growing acceptance of 'personalized' approaches to health care and the need to prove that personalized interventions tailored to an individual's likely unique physiological profile and other characteristics work as they should. In fact, the preferred way of referring to N-of-1 studies in contemporary settings is as 'personalized studies.' Designing efficient personalized studies and analyzing data from them in ways that ensure statistically valid inferences are not trivial, however. I briefly discuss some of the more complex issues surrounding the design and analysis of personalized studies, such as the use of washout periods, the frequency with which measures associated with the efficacy of an intervention are collected during a study, and the serious effect that serial correlation can have on the analysis and interpretation of personalized study data and results if not accounted for explicitly. I point out that more efficient sequential designs for personalized and aggregated personalized studies can be developed, and I explore the properties of sequential personalized studies in a few settings via simulation studies. Finally, I comment on contexts within which personalized studies will likely be pursued in the future.</p>\",\"PeriodicalId\":73195,\"journal\":{\"name\":\"Harvard data science review\",\"volume\":\"2022 SI3\",\"pages\":\"\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2022-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10081537/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Harvard data science review\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1162/99608f92.f1eef6f4\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/9/8 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Harvard data science review","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1162/99608f92.f1eef6f4","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/9/8 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
Accommodating Serial Correlation and Sequential Design Elements in Personalized Studies and Aggregated Personalized Studies.
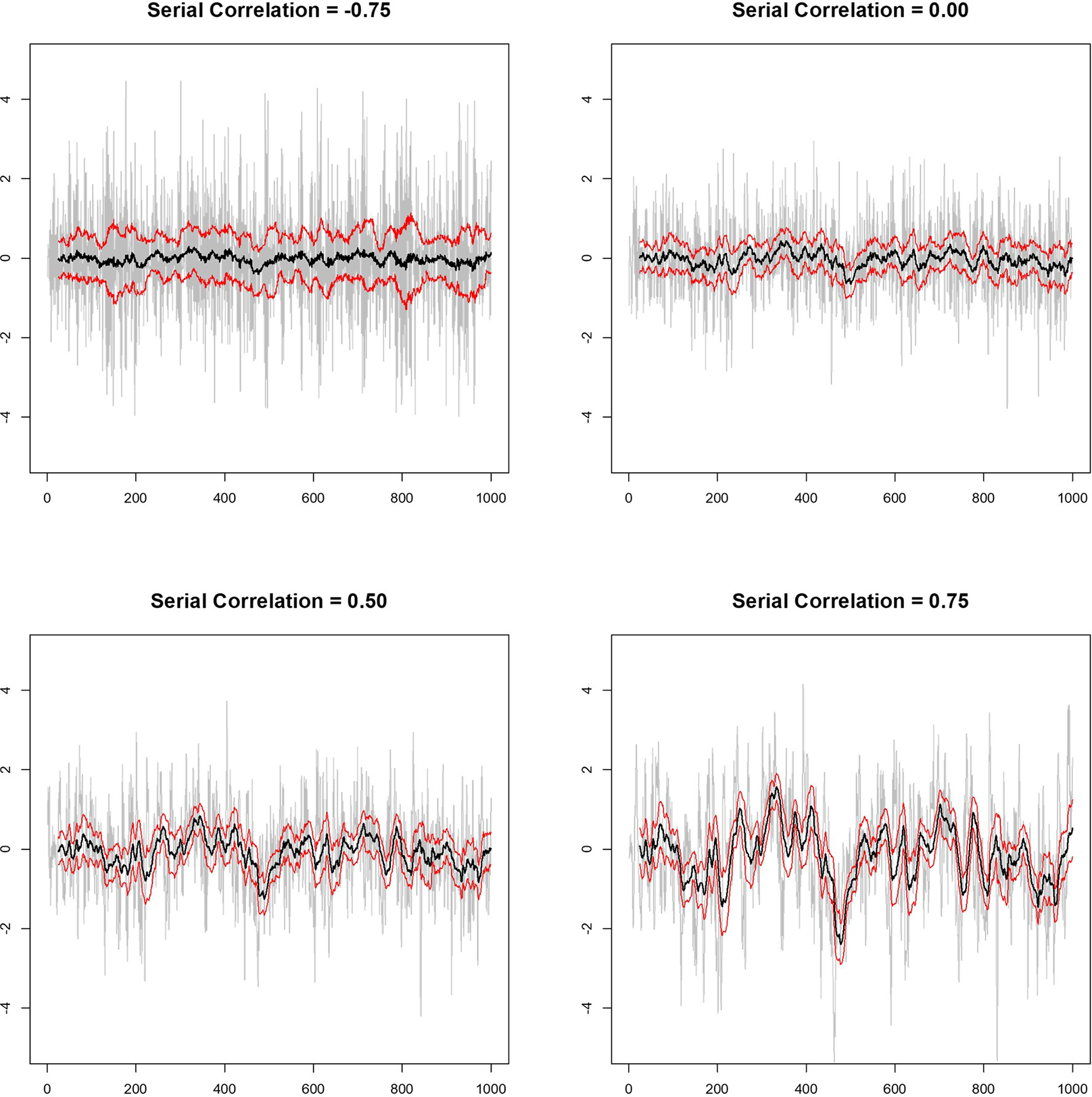
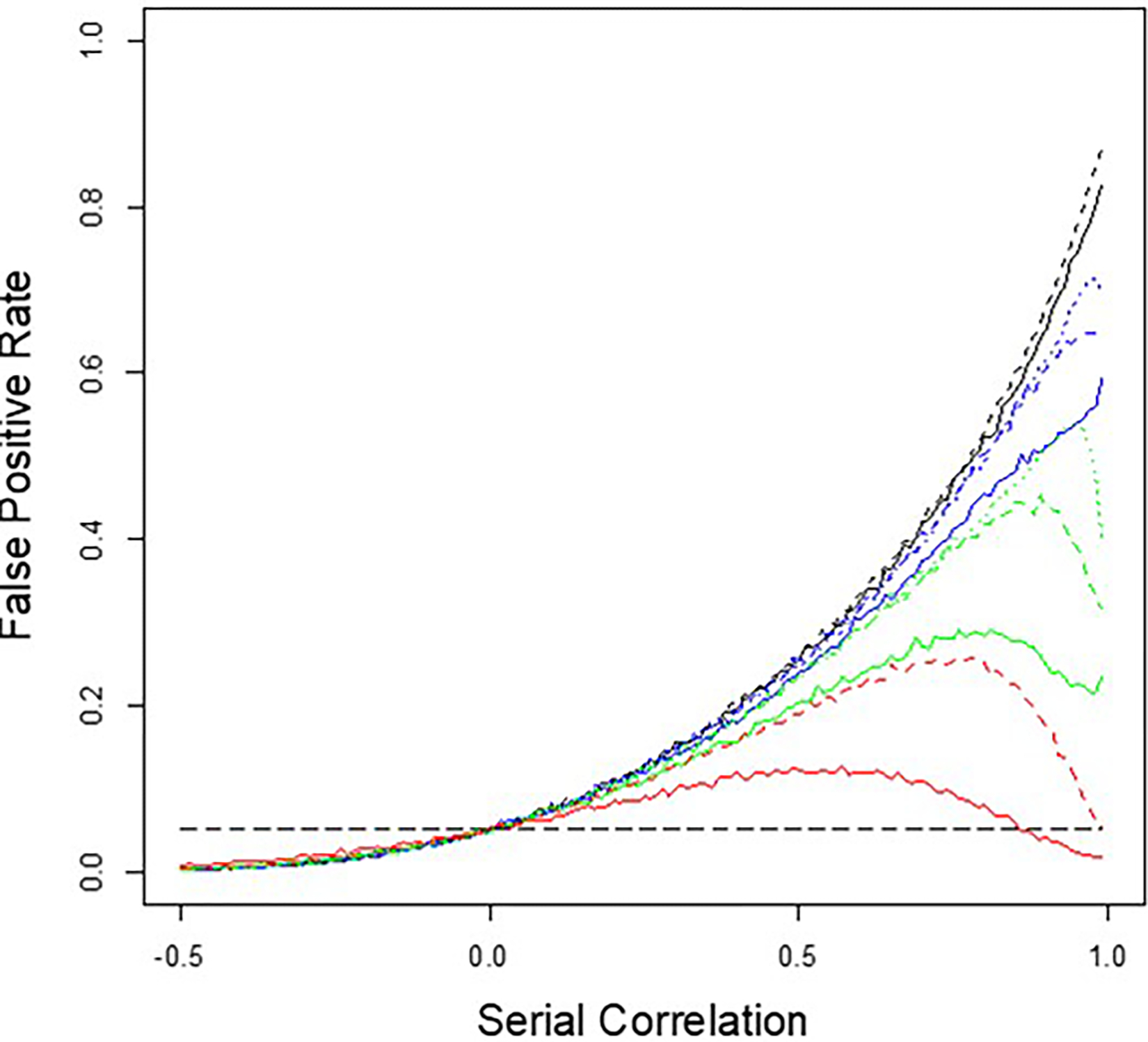
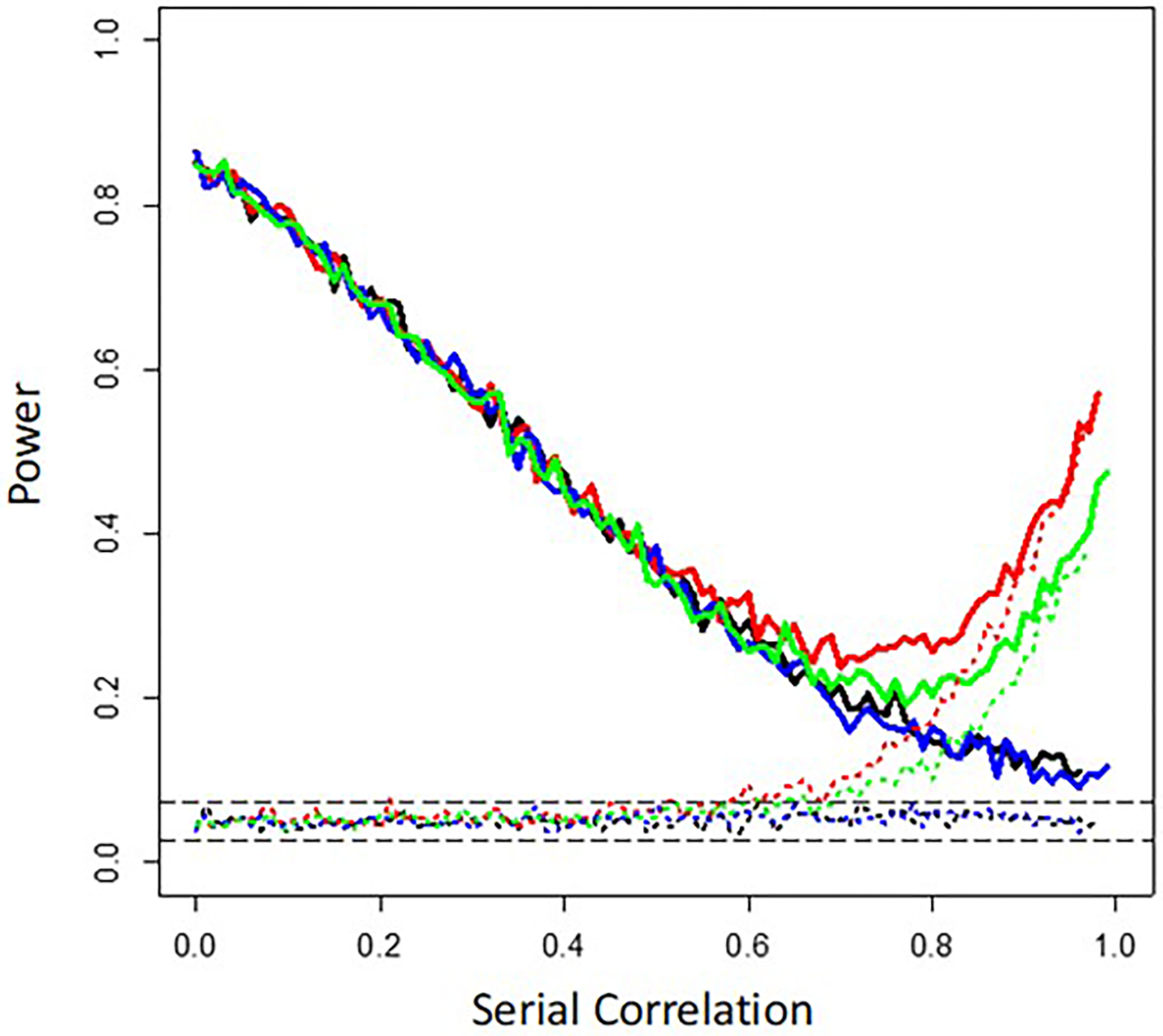
Single subject, or 'N-of-1,' studies are receiving a great deal of attention from both theoretical and applied researchers. This is consistent with the growing acceptance of 'personalized' approaches to health care and the need to prove that personalized interventions tailored to an individual's likely unique physiological profile and other characteristics work as they should. In fact, the preferred way of referring to N-of-1 studies in contemporary settings is as 'personalized studies.' Designing efficient personalized studies and analyzing data from them in ways that ensure statistically valid inferences are not trivial, however. I briefly discuss some of the more complex issues surrounding the design and analysis of personalized studies, such as the use of washout periods, the frequency with which measures associated with the efficacy of an intervention are collected during a study, and the serious effect that serial correlation can have on the analysis and interpretation of personalized study data and results if not accounted for explicitly. I point out that more efficient sequential designs for personalized and aggregated personalized studies can be developed, and I explore the properties of sequential personalized studies in a few settings via simulation studies. Finally, I comment on contexts within which personalized studies will likely be pursued in the future.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
