{"title":"使用成对最大似然的离散数据中具有随机斜率的多层扫描电镜","authors":"Maria T. Barendse, Yves Rosseel","doi":"10.1111/bmsp.12294","DOIUrl":null,"url":null,"abstract":"<p>Pairwise maximum likelihood (PML) estimation is a promising method for multilevel models with discrete responses. Multilevel models take into account that units within a cluster tend to be more alike than units from different clusters. The pairwise likelihood is then obtained as the product of bivariate likelihoods for all within-cluster pairs of units and items. In this study, we investigate the PML estimation method with computationally intensive multilevel random intercept and random slope structural equation models (SEM) in discrete data. In pursuing this, we first reconsidered the general ‘wide format’ (WF) approach for SEM models and then extend the WF approach with random slopes. In a small simulation study we the determine accuracy and efficiency of the PML estimation method by varying the sample size (250, 500, 1000, 2000), response scales (two-point, four-point), and data-generating model (mediation model with three random slopes, factor model with one and two random slopes). Overall, results show that the PML estimation method is capable of estimating computationally intensive random intercept and random slopes multilevel models in the SEM framework with discrete data and many (six or more) latent variables with satisfactory accuracy and efficiency. However, the condition with 250 clusters combined with a two-point response scale shows more bias.</p>","PeriodicalId":55322,"journal":{"name":"British Journal of Mathematical & Statistical Psychology","volume":"76 2","pages":"327-352"},"PeriodicalIF":1.8000,"publicationDate":"2023-01-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/bmsp.12294","citationCount":"1","resultStr":"{\"title\":\"Multilevel SEM with random slopes in discrete data using the pairwise maximum likelihood\",\"authors\":\"Maria T. Barendse, Yves Rosseel\",\"doi\":\"10.1111/bmsp.12294\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Pairwise maximum likelihood (PML) estimation is a promising method for multilevel models with discrete responses. Multilevel models take into account that units within a cluster tend to be more alike than units from different clusters. The pairwise likelihood is then obtained as the product of bivariate likelihoods for all within-cluster pairs of units and items. In this study, we investigate the PML estimation method with computationally intensive multilevel random intercept and random slope structural equation models (SEM) in discrete data. In pursuing this, we first reconsidered the general ‘wide format’ (WF) approach for SEM models and then extend the WF approach with random slopes. In a small simulation study we the determine accuracy and efficiency of the PML estimation method by varying the sample size (250, 500, 1000, 2000), response scales (two-point, four-point), and data-generating model (mediation model with three random slopes, factor model with one and two random slopes). Overall, results show that the PML estimation method is capable of estimating computationally intensive random intercept and random slopes multilevel models in the SEM framework with discrete data and many (six or more) latent variables with satisfactory accuracy and efficiency. However, the condition with 250 clusters combined with a two-point response scale shows more bias.</p>\",\"PeriodicalId\":55322,\"journal\":{\"name\":\"British Journal of Mathematical & Statistical Psychology\",\"volume\":\"76 2\",\"pages\":\"327-352\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2023-01-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/bmsp.12294\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"British Journal of Mathematical & Statistical Psychology\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/bmsp.12294\",\"RegionNum\":3,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"British Journal of Mathematical & Statistical Psychology","FirstCategoryId":"102","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/bmsp.12294","RegionNum":3,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Multilevel SEM with random slopes in discrete data using the pairwise maximum likelihood
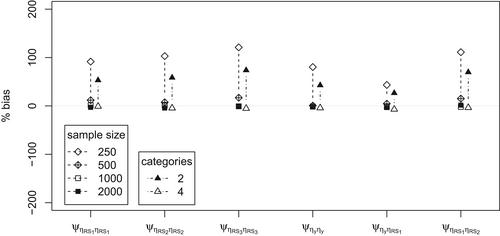
Pairwise maximum likelihood (PML) estimation is a promising method for multilevel models with discrete responses. Multilevel models take into account that units within a cluster tend to be more alike than units from different clusters. The pairwise likelihood is then obtained as the product of bivariate likelihoods for all within-cluster pairs of units and items. In this study, we investigate the PML estimation method with computationally intensive multilevel random intercept and random slope structural equation models (SEM) in discrete data. In pursuing this, we first reconsidered the general ‘wide format’ (WF) approach for SEM models and then extend the WF approach with random slopes. In a small simulation study we the determine accuracy and efficiency of the PML estimation method by varying the sample size (250, 500, 1000, 2000), response scales (two-point, four-point), and data-generating model (mediation model with three random slopes, factor model with one and two random slopes). Overall, results show that the PML estimation method is capable of estimating computationally intensive random intercept and random slopes multilevel models in the SEM framework with discrete data and many (six or more) latent variables with satisfactory accuracy and efficiency. However, the condition with 250 clusters combined with a two-point response scale shows more bias.
期刊介绍:
The British Journal of Mathematical and Statistical Psychology publishes articles relating to areas of psychology which have a greater mathematical or statistical aspect of their argument than is usually acceptable to other journals including:
• mathematical psychology
• statistics
• psychometrics
• decision making
• psychophysics
• classification
• relevant areas of mathematics, computing and computer software
These include articles that address substantitive psychological issues or that develop and extend techniques useful to psychologists. New models for psychological processes, new approaches to existing data, critiques of existing models and improved algorithms for estimating the parameters of a model are examples of articles which may be favoured.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
