Manuel Feser, Patrick König, Anne Fiebig, Daniel Arend, Matthias Lange, Uwe Scholz
{"title":"通往植物数据共享之路--基因分型使用案例。","authors":"Manuel Feser, Patrick König, Anne Fiebig, Daniel Arend, Matthias Lange, Uwe Scholz","doi":"10.1515/jib-2022-0033","DOIUrl":null,"url":null,"abstract":"<p><p>Over the last years it has been observed that the progress in data collection in life science has created increasing demand and opportunities for advanced bioinformatics. This includes data management as well as the individual data analysis and often covers the entire data life cycle. A variety of tools have been developed to store, share, or reuse the data produced in the different domains such as genotyping. Especially imputation, as a subfield of genotyping, requires good Research Data Management (RDM) strategies to enable use and re-use of genotypic data. To aim for sustainable software, it is necessary to develop tools and surrounding ecosystems, which are reusable and maintainable. Reusability in the context of streamlined tools can e.g. be achieved by standardizing the input and output of the different tools and adapting to open and broadly used file formats. By using such established file formats, the tools can also be connected with others, improving the overall interoperability of the software. Finally, it is important to build strong communities that maintain the tools by developing and contributing new features and maintenance updates. In this article, concepts for this will be presented for an imputation service.</p>","PeriodicalId":53625,"journal":{"name":"Journal of Integrative Bioinformatics","volume":"19 4","pages":""},"PeriodicalIF":1.6000,"publicationDate":"2022-09-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9800039/pdf/","citationCount":"0","resultStr":"{\"title\":\"On the way to plant data commons - a genotyping use case.\",\"authors\":\"Manuel Feser, Patrick König, Anne Fiebig, Daniel Arend, Matthias Lange, Uwe Scholz\",\"doi\":\"10.1515/jib-2022-0033\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Over the last years it has been observed that the progress in data collection in life science has created increasing demand and opportunities for advanced bioinformatics. This includes data management as well as the individual data analysis and often covers the entire data life cycle. A variety of tools have been developed to store, share, or reuse the data produced in the different domains such as genotyping. Especially imputation, as a subfield of genotyping, requires good Research Data Management (RDM) strategies to enable use and re-use of genotypic data. To aim for sustainable software, it is necessary to develop tools and surrounding ecosystems, which are reusable and maintainable. Reusability in the context of streamlined tools can e.g. be achieved by standardizing the input and output of the different tools and adapting to open and broadly used file formats. By using such established file formats, the tools can also be connected with others, improving the overall interoperability of the software. Finally, it is important to build strong communities that maintain the tools by developing and contributing new features and maintenance updates. In this article, concepts for this will be presented for an imputation service.</p>\",\"PeriodicalId\":53625,\"journal\":{\"name\":\"Journal of Integrative Bioinformatics\",\"volume\":\"19 4\",\"pages\":\"\"},\"PeriodicalIF\":1.6000,\"publicationDate\":\"2022-09-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9800039/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Integrative Bioinformatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1515/jib-2022-0033\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/12/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Integrative Bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1515/jib-2022-0033","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/12/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
On the way to plant data commons - a genotyping use case.
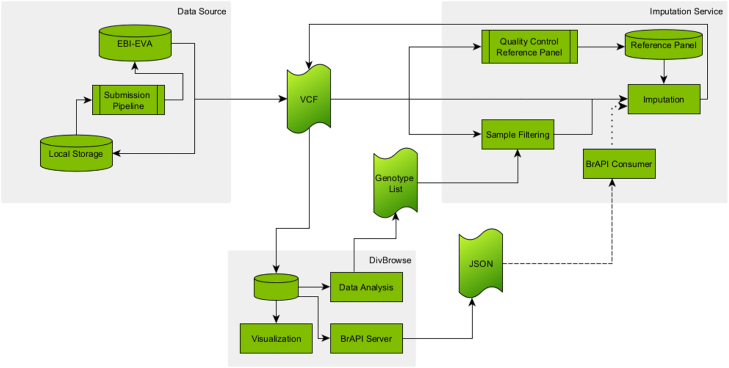
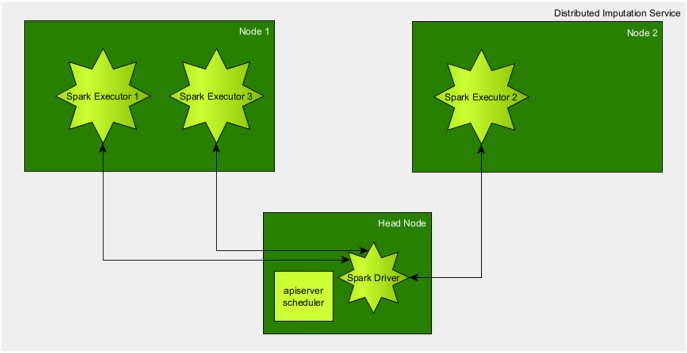
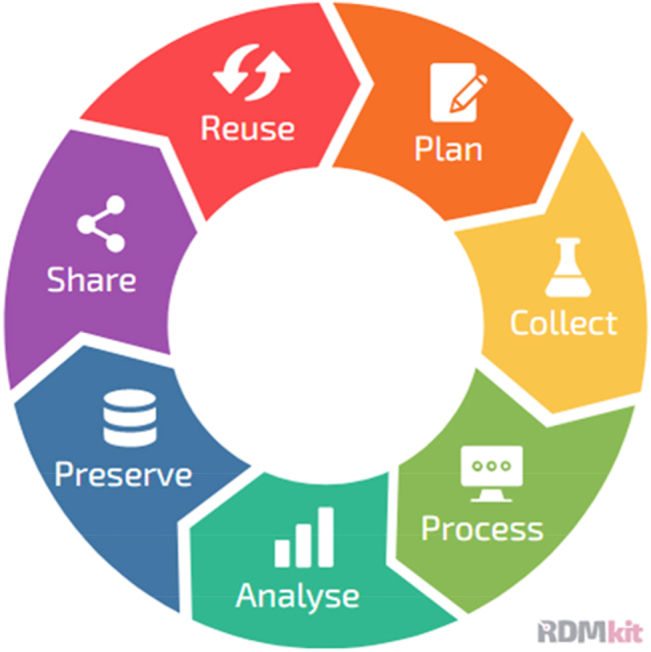
Over the last years it has been observed that the progress in data collection in life science has created increasing demand and opportunities for advanced bioinformatics. This includes data management as well as the individual data analysis and often covers the entire data life cycle. A variety of tools have been developed to store, share, or reuse the data produced in the different domains such as genotyping. Especially imputation, as a subfield of genotyping, requires good Research Data Management (RDM) strategies to enable use and re-use of genotypic data. To aim for sustainable software, it is necessary to develop tools and surrounding ecosystems, which are reusable and maintainable. Reusability in the context of streamlined tools can e.g. be achieved by standardizing the input and output of the different tools and adapting to open and broadly used file formats. By using such established file formats, the tools can also be connected with others, improving the overall interoperability of the software. Finally, it is important to build strong communities that maintain the tools by developing and contributing new features and maintenance updates. In this article, concepts for this will be presented for an imputation service.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
