Koen Welvaars, Jacobien H F Oosterhoff, Michel P J van den Bekerom, Job N Doornberg, Ernst P van Haarst
{"title":"重采样数据解决类别不平衡问题(IRCIP)的意义:医疗数据分类算法对性能影响的评估","authors":"Koen Welvaars, Jacobien H F Oosterhoff, Michel P J van den Bekerom, Job N Doornberg, Ernst P van Haarst","doi":"10.1093/jamiaopen/ooad033","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>When correcting for the \"class imbalance\" problem in medical data, the effects of resampling applied on classifier algorithms remain unclear. We examined the effect on performance over several combinations of classifiers and resampling ratios.</p><p><strong>Materials and methods: </strong>Multiple classification algorithms were trained on 7 resampled datasets: no correction, random undersampling, 4 ratios of Synthetic Minority Oversampling Technique (SMOTE), and random oversampling with the Adaptive Synthetic algorithm (ADASYN). Performance was evaluated in Area Under the Curve (AUC), precision, recall, Brier score, and calibration metrics. A case study on prediction modeling for 30-day unplanned readmissions in previously admitted Urology patients was presented.</p><p><strong>Results: </strong>For most algorithms, using resampled data showed a significant increase in AUC and precision, ranging from 0.74 (CI: 0.69-0.79) to 0.93 (CI: 0.92-0.94), and 0.35 (CI: 0.12-0.58) to 0.86 (CI: 0.81-0.92) respectively. All classification algorithms showed significant increases in recall, and significant decreases in Brier score with distorted calibration overestimating positives.</p><p><strong>Discussion: </strong>Imbalance correction resulted in an overall improved performance, yet poorly calibrated models. There can still be clinical utility due to a strong discriminating performance, specifically when predicting only low and high risk cases is clinically more relevant.</p><p><strong>Conclusion: </strong>Resampling data resulted in increased performances in classification algorithms, yet produced an overestimation of positive predictions. Based on the findings from our case study, a thoughtful predefinition of the clinical prediction task may guide the use of resampling techniques in future studies aiming to improve clinical decision support tools.</p>","PeriodicalId":36278,"journal":{"name":"JAMIA Open","volume":"6 2","pages":"ooad033"},"PeriodicalIF":3.4000,"publicationDate":"2023-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/bb/be/ooad033.PMC10232287.pdf","citationCount":"1","resultStr":"{\"title\":\"Implications of resampling data to address the class imbalance problem (IRCIP): an evaluation of impact on performance between classification algorithms in medical data.\",\"authors\":\"Koen Welvaars, Jacobien H F Oosterhoff, Michel P J van den Bekerom, Job N Doornberg, Ernst P van Haarst\",\"doi\":\"10.1093/jamiaopen/ooad033\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objective: </strong>When correcting for the \\\"class imbalance\\\" problem in medical data, the effects of resampling applied on classifier algorithms remain unclear. We examined the effect on performance over several combinations of classifiers and resampling ratios.</p><p><strong>Materials and methods: </strong>Multiple classification algorithms were trained on 7 resampled datasets: no correction, random undersampling, 4 ratios of Synthetic Minority Oversampling Technique (SMOTE), and random oversampling with the Adaptive Synthetic algorithm (ADASYN). Performance was evaluated in Area Under the Curve (AUC), precision, recall, Brier score, and calibration metrics. A case study on prediction modeling for 30-day unplanned readmissions in previously admitted Urology patients was presented.</p><p><strong>Results: </strong>For most algorithms, using resampled data showed a significant increase in AUC and precision, ranging from 0.74 (CI: 0.69-0.79) to 0.93 (CI: 0.92-0.94), and 0.35 (CI: 0.12-0.58) to 0.86 (CI: 0.81-0.92) respectively. All classification algorithms showed significant increases in recall, and significant decreases in Brier score with distorted calibration overestimating positives.</p><p><strong>Discussion: </strong>Imbalance correction resulted in an overall improved performance, yet poorly calibrated models. There can still be clinical utility due to a strong discriminating performance, specifically when predicting only low and high risk cases is clinically more relevant.</p><p><strong>Conclusion: </strong>Resampling data resulted in increased performances in classification algorithms, yet produced an overestimation of positive predictions. Based on the findings from our case study, a thoughtful predefinition of the clinical prediction task may guide the use of resampling techniques in future studies aiming to improve clinical decision support tools.</p>\",\"PeriodicalId\":36278,\"journal\":{\"name\":\"JAMIA Open\",\"volume\":\"6 2\",\"pages\":\"ooad033\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2023-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/bb/be/ooad033.PMC10232287.pdf\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JAMIA Open\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/jamiaopen/ooad033\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JAMIA Open","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/jamiaopen/ooad033","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Implications of resampling data to address the class imbalance problem (IRCIP): an evaluation of impact on performance between classification algorithms in medical data.
Objective: When correcting for the "class imbalance" problem in medical data, the effects of resampling applied on classifier algorithms remain unclear. We examined the effect on performance over several combinations of classifiers and resampling ratios.
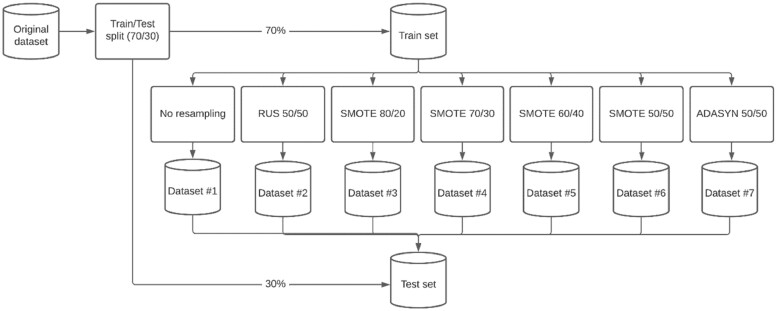
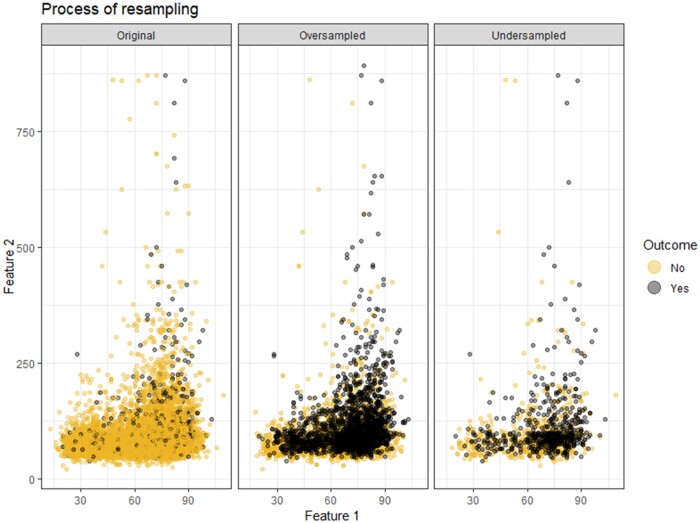
Materials and methods: Multiple classification algorithms were trained on 7 resampled datasets: no correction, random undersampling, 4 ratios of Synthetic Minority Oversampling Technique (SMOTE), and random oversampling with the Adaptive Synthetic algorithm (ADASYN). Performance was evaluated in Area Under the Curve (AUC), precision, recall, Brier score, and calibration metrics. A case study on prediction modeling for 30-day unplanned readmissions in previously admitted Urology patients was presented.
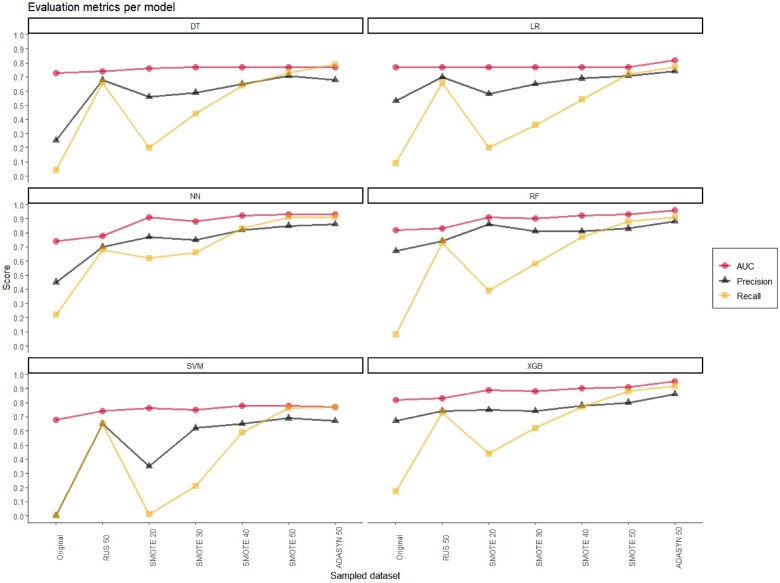
Results: For most algorithms, using resampled data showed a significant increase in AUC and precision, ranging from 0.74 (CI: 0.69-0.79) to 0.93 (CI: 0.92-0.94), and 0.35 (CI: 0.12-0.58) to 0.86 (CI: 0.81-0.92) respectively. All classification algorithms showed significant increases in recall, and significant decreases in Brier score with distorted calibration overestimating positives.
Discussion: Imbalance correction resulted in an overall improved performance, yet poorly calibrated models. There can still be clinical utility due to a strong discriminating performance, specifically when predicting only low and high risk cases is clinically more relevant.
Conclusion: Resampling data resulted in increased performances in classification algorithms, yet produced an overestimation of positive predictions. Based on the findings from our case study, a thoughtful predefinition of the clinical prediction task may guide the use of resampling techniques in future studies aiming to improve clinical decision support tools.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
