Joyce C Ho , Lisa R Staimez , K M Venkat Narayan , Lucila Ohno-Machado , Roy L Simpson , Vicki Stover Hertzberg
{"title":"利用电子健康记录评估2型糖尿病患者多种心血管并发症的可用风险评分","authors":"Joyce C Ho , Lisa R Staimez , K M Venkat Narayan , Lucila Ohno-Machado , Roy L Simpson , Vicki Stover Hertzberg","doi":"10.1016/j.cmpbup.2022.100087","DOIUrl":null,"url":null,"abstract":"<div><h3>Aims</h3><p>Various cardiovascular risk prediction models have been developed for patients with type 2 diabetes mellitus. Yet few models have been validated externally. We perform a comprehensive validation of existing risk models on a heterogeneous population of patients with type 2 diabetes using secondary analysis of electronic health record data.</p></div><div><h3>Methods</h3><p>Electronic health records of 47,988 patients with type 2 diabetes between 2013 and 2017 were used to validate 16 cardiovascular risk models, including 5 that had not been compared previously, to estimate the 1-year risk of various cardiovascular outcomes. Discrimination and calibration were assessed by the c-statistic and the Hosmer-Lemeshow goodness-of-fit statistic, respectively. Each model was also evaluated based on the missing measurement rate. Sub-analysis was performed to determine the impact of race on discrimination performance.</p></div><div><h3>Results</h3><p>There was limited discrimination (c-statistics ranged from 0.51 to 0.67) across the cardiovascular risk models. Discrimination generally improved when the model was tailored towards the individual outcome. After recalibration of the models, the Hosmer-Lemeshow statistic yielded p-values above 0.05. However, several of the models with the best discrimination relied on measurements that were often imputed (up to 39% missing).</p></div><div><h3>Conclusion</h3><p>No single prediction model achieved the best performance on a full range of cardiovascular endpoints. Moreover, several of the highest-scoring models relied on variables with high missingness frequencies such as HbA1c and cholesterol that necessitated data imputation and may not be as useful in practice. An open-source version of our developed Python package, cvdm, is available for comparisons using other data sources.</p></div>","PeriodicalId":72670,"journal":{"name":"Computer methods and programs in biomedicine update","volume":"3 ","pages":"Article 100087"},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/b7/a4/nihms-1901943.PMC10274317.pdf","citationCount":"2","resultStr":"{\"title\":\"Evaluation of available risk scores to predict multiple cardiovascular complications for patients with type 2 diabetes mellitus using electronic health records\",\"authors\":\"Joyce C Ho , Lisa R Staimez , K M Venkat Narayan , Lucila Ohno-Machado , Roy L Simpson , Vicki Stover Hertzberg\",\"doi\":\"10.1016/j.cmpbup.2022.100087\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Aims</h3><p>Various cardiovascular risk prediction models have been developed for patients with type 2 diabetes mellitus. Yet few models have been validated externally. We perform a comprehensive validation of existing risk models on a heterogeneous population of patients with type 2 diabetes using secondary analysis of electronic health record data.</p></div><div><h3>Methods</h3><p>Electronic health records of 47,988 patients with type 2 diabetes between 2013 and 2017 were used to validate 16 cardiovascular risk models, including 5 that had not been compared previously, to estimate the 1-year risk of various cardiovascular outcomes. Discrimination and calibration were assessed by the c-statistic and the Hosmer-Lemeshow goodness-of-fit statistic, respectively. Each model was also evaluated based on the missing measurement rate. Sub-analysis was performed to determine the impact of race on discrimination performance.</p></div><div><h3>Results</h3><p>There was limited discrimination (c-statistics ranged from 0.51 to 0.67) across the cardiovascular risk models. Discrimination generally improved when the model was tailored towards the individual outcome. After recalibration of the models, the Hosmer-Lemeshow statistic yielded p-values above 0.05. However, several of the models with the best discrimination relied on measurements that were often imputed (up to 39% missing).</p></div><div><h3>Conclusion</h3><p>No single prediction model achieved the best performance on a full range of cardiovascular endpoints. Moreover, several of the highest-scoring models relied on variables with high missingness frequencies such as HbA1c and cholesterol that necessitated data imputation and may not be as useful in practice. An open-source version of our developed Python package, cvdm, is available for comparisons using other data sources.</p></div>\",\"PeriodicalId\":72670,\"journal\":{\"name\":\"Computer methods and programs in biomedicine update\",\"volume\":\"3 \",\"pages\":\"Article 100087\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/b7/a4/nihms-1901943.PMC10274317.pdf\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computer methods and programs in biomedicine update\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2666990022000386\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer methods and programs in biomedicine update","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2666990022000386","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Evaluation of available risk scores to predict multiple cardiovascular complications for patients with type 2 diabetes mellitus using electronic health records
Aims
Various cardiovascular risk prediction models have been developed for patients with type 2 diabetes mellitus. Yet few models have been validated externally. We perform a comprehensive validation of existing risk models on a heterogeneous population of patients with type 2 diabetes using secondary analysis of electronic health record data.
Methods
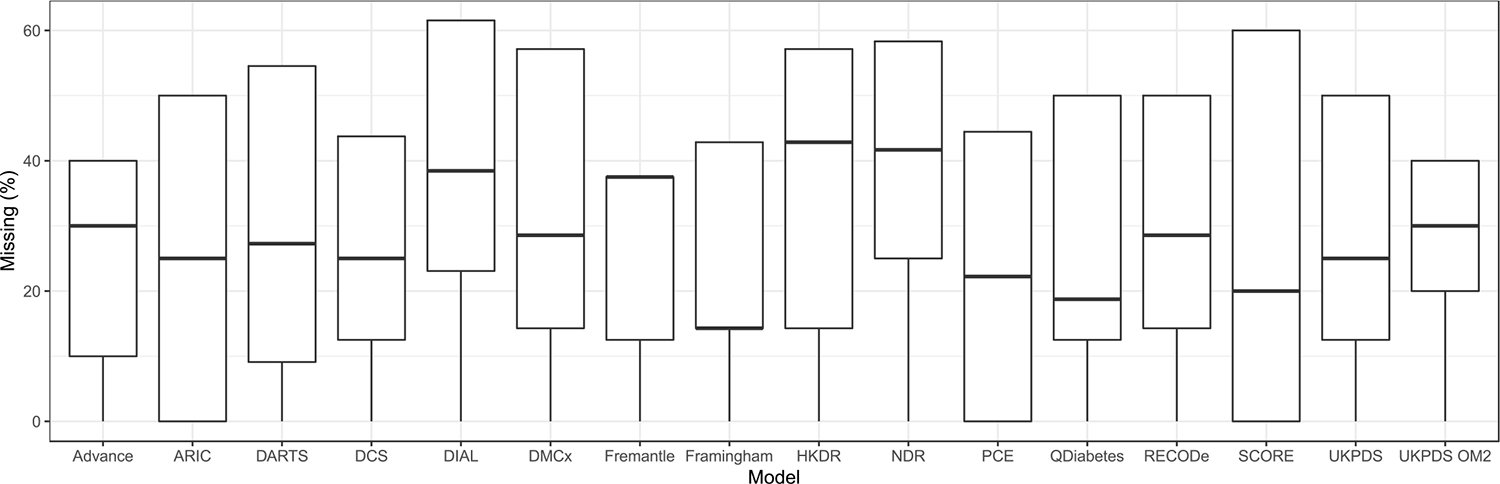
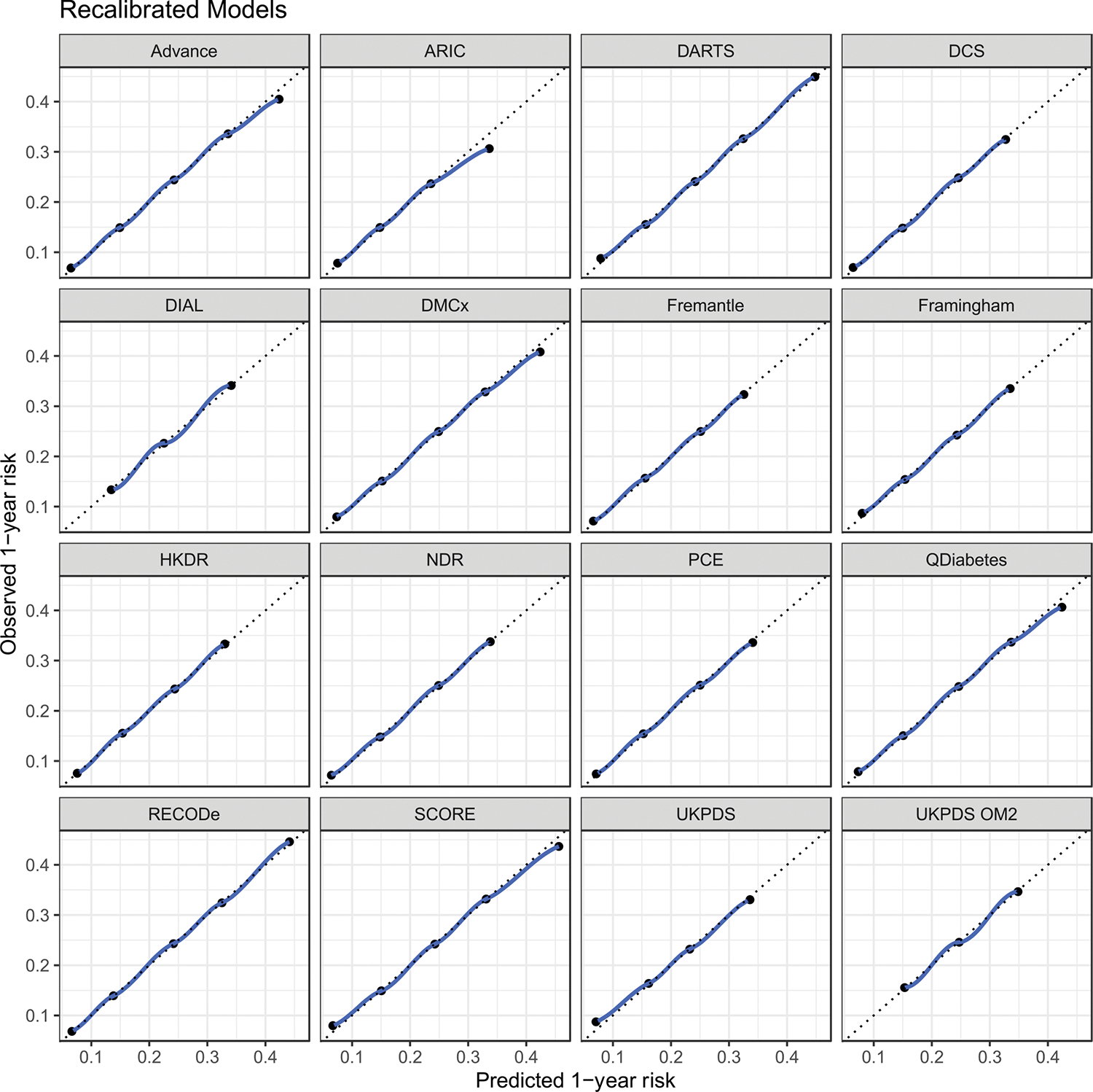
Electronic health records of 47,988 patients with type 2 diabetes between 2013 and 2017 were used to validate 16 cardiovascular risk models, including 5 that had not been compared previously, to estimate the 1-year risk of various cardiovascular outcomes. Discrimination and calibration were assessed by the c-statistic and the Hosmer-Lemeshow goodness-of-fit statistic, respectively. Each model was also evaluated based on the missing measurement rate. Sub-analysis was performed to determine the impact of race on discrimination performance.
Results
There was limited discrimination (c-statistics ranged from 0.51 to 0.67) across the cardiovascular risk models. Discrimination generally improved when the model was tailored towards the individual outcome. After recalibration of the models, the Hosmer-Lemeshow statistic yielded p-values above 0.05. However, several of the models with the best discrimination relied on measurements that were often imputed (up to 39% missing).
Conclusion
No single prediction model achieved the best performance on a full range of cardiovascular endpoints. Moreover, several of the highest-scoring models relied on variables with high missingness frequencies such as HbA1c and cholesterol that necessitated data imputation and may not be as useful in practice. An open-source version of our developed Python package, cvdm, is available for comparisons using other data sources.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
